

为了真实地再现军事行动,严肃的战斗模拟要求建模实体具有合理的战术行为。因此,必须定义作战战术、条令、交战规则和行动概念。事实证明,强化学习可以在相关实体的行为边界内生成广泛的战术行动。在多智能体地面作战场景中,本文展示了人工智能(AI)应用如何制定战略并向附属单元提供命令,同时相应地执行任务。我们提出了一种将人类知识和责任与人工智能系统相结合的方法。为了在共同层面上进行交流,人工智能以自然语言下达命令和行动。这样,人类操作员就可以扮演 "人在回路中 "的角色,对人工智能的推理进行验证和评估。本文展示了自然语言与强化学习过程的成功整合。
RELEGS:针对复杂作战情况的强化学习
为了获得模型架构的灵感,我们研究了 DeepMind 的 AlphaStar 架构,因为它被认为是复杂 RL 问题领域的最先进架构。通过我们的架构(如图 2 所示),我们提出了一种灵活、可扩展的行动空间与深度神经网络相结合的适应性新方法。观察空间的设计基于如何准备战场的军事经验。通常使用地图和可用部队表。因此,模拟观测被分为标量数据(如可用坦克数量及其弹药)。同时,基于地图的输入作为视觉输入提供给空间编码器。
标量数据用于向人工智能提供几乎所有场景细节的建议。其中包括有关自身部队及其平台的数据,以及有关敌方部队的部分信息。输入并非以绝对数字给出,而是采用归一化方法来提高训练效果。编码器可以很容易地写成多层感知器(MLP);不过,使用多头注意力网络可以大大提高训练后智能体的质量,因此应予以采用(Vaswani 等人,2017 年)。
为了理解地理地形、距离和海拔高度的含义,人工智能会被输入一个带有实体编码的地图视觉表示。颜色方案基于三通道图像,这使我们能够轻松地将数据可视化。虽然使用更多通道会给人类的图形显示带来问题,但人工智能能够理解更多通道。不同的字段类型和实体会用特殊的颜色进行编码,以便始终能够区分。这种所谓的空间编码器由多个卷积层组成。最初,我们尝试使用 ResNet-50 (He 和 Zhang,2016 年)和 MobileNetV3 (Howard 等,2019 年)等著名架构,甚至使用预先训练的权重。然而,这并没有带来可接受的训练性能。因此,我们用自己的架构缩小了卷积神经网络(CNN)的规模。
为了测试和优化这一架构,我们使用了一个自动编码器设置,并使用了模拟中的真实样本。我们能够将参数数量从大约 200 万减少到大约 47000。此外,我们还生成了一个预训练模型,该模型已与模拟的真实观测数据相匹配。这一步极大地帮助我们加快了 RL 进程。
一个可选元素是添加语言输入,为人工智能定义任务。虽然一般的战略人工智能不使用这一元素,但计划将其用于下属智能体。这些智能体将以自然语言接收来自战略人工智能的任务,并使用双向门控递归单元(GRU)编码器对其进行处理。
视觉数据、任务数据和标量数据的编码值被合并并输入核心网络。根据 Hochreiter 和 Schmidhuber(1997 年)的介绍,核心主要是一个拥有 768 个单元的长短期记忆(LSTM)组件。在军事场景中,指挥官必须了解高价值资产的长期战略规划。在本模拟中,人工智能可以请求战斗支援要素,这些要素在影响战场之前需要长达 15 分钟的时间。因此,人工智能必须了解未来任务的时间安排和规划。在 RL 中使用 LSTM 网络相当困难,因为它需要大量的训练时间,而且会导致上面各层的梯度消失。因此,我们决定在 LSTM 上添加一个跳过连接,以尽量减少新增层的负面影响。
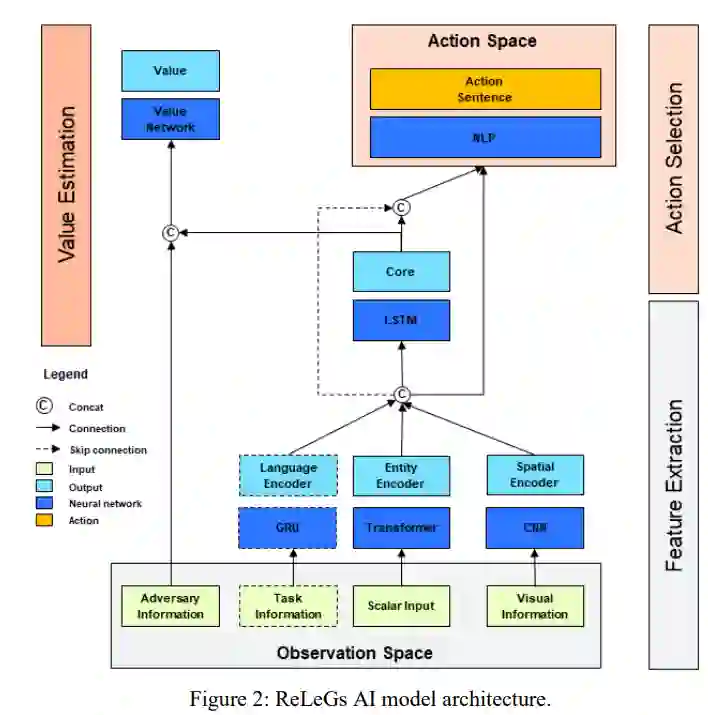
动作头由一个自然语言处理(NLP)模型组成。这是一个非常简化的动作头模型,包含一个小型 LSTM 和一个额外的密集层,共有约 340000 个参数。其结果是一个尺寸为 8 x 125 的多离散动作空间。
除主模型外,还有一个单独的价值网络部分。价值网络使用核心 LSTM 的输出,并将对手信息串联起来传递给 MLP。然后,MLP 可以精确预测价值函数。通过对手信息,价值网络对模拟有了一个上帝般的地面实况视图。由于该网络只与训练相关,因此可以在不干扰训练完整性的情况下进行。

