

目的:本文旨在研究国家冲突建模中的区域变量如何影响预测的准确性,并确定进一步改进预测的方法。
设计/方法/途径:本文使用统计学习方法评估国家聚类的数据量,并根据使用的聚类数量量化准确性。
研究结果:本研究表明,只要模型稳健,增加建模聚类的数量可提高预测冲突的能力。
独创性/价值:本研究调查了冲突建模中使用的聚类数量,而之前的研究在建模前假设了特定的数量。
战争是一场混乱的战争。战争不仅会付出当前的生命代价,还会影响未来的生命、财富和荣誉(声望)。尽管 20 世纪 40 年代在德国发生的事件已经过去了 70 多年,但人们仍然对大屠杀的宗教种族灭绝感到精神痛苦。如今,也门的政治冲突阻碍了发展,各派争夺政府的官方合法性。战争夺走的不仅仅是生命,它渗透到生活的方方面面。
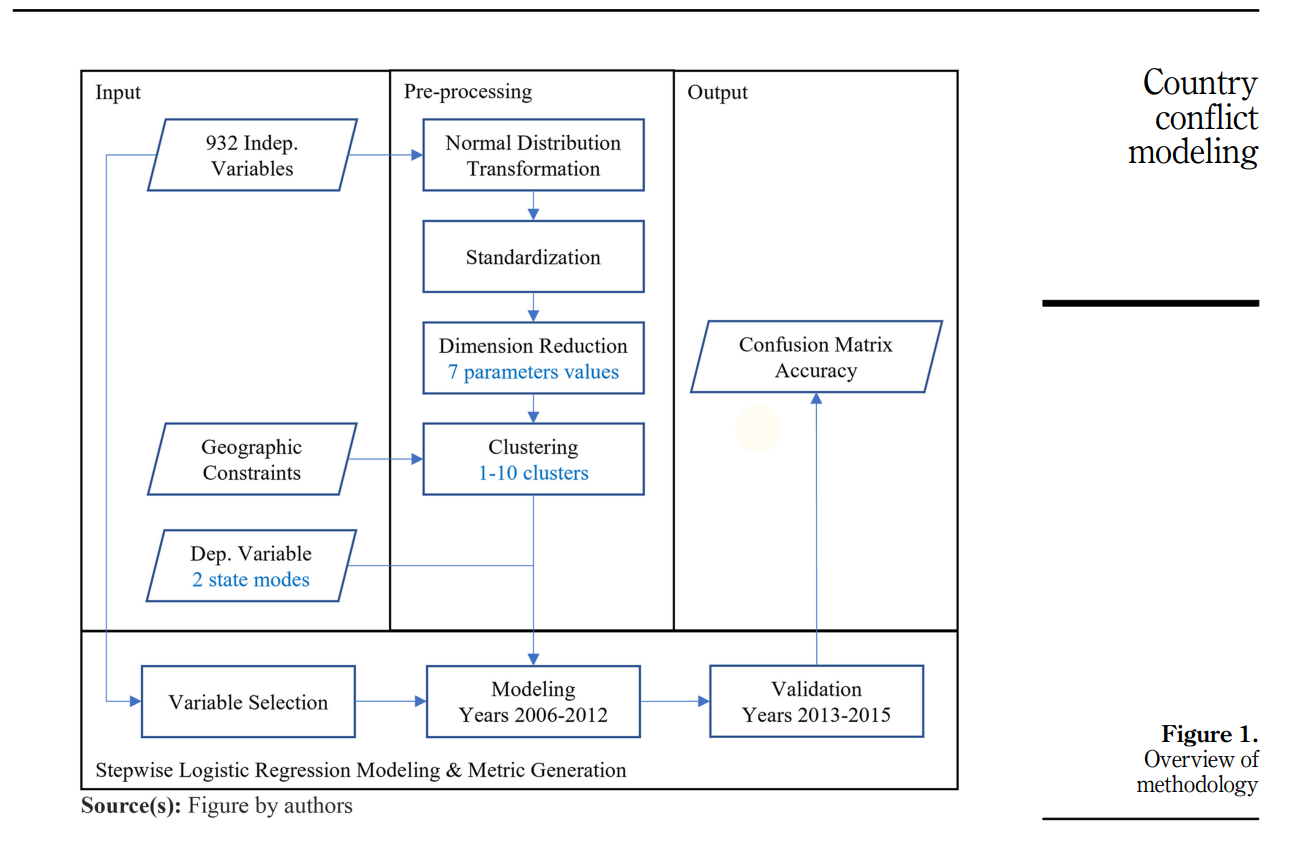
从最高权力层到最底层的贫困地区,研究人员都在寻求并努力了解使战火持续不熄的构造--大量的时间、资源和研究推动着国家冲突与和平模型的建立。然而,具有讽刺意味的是,研究人员往往从狭隘的角度看待冲突,认为冲突与经济资源分配和信息博弈论有关(Brito 和 Intriligator,1985 年)。例如,Gartzke 主要关注资本相互依存的经济贡献(Gartzke et al. 然而,国家冲突总是比这更复杂--它是一个包含政治、经济和社会方面的产物。在对预测国家冲突的重要变量进行调查时,有五个代用指标不断浮出水面: 政体(通过政权类型)、人均国内生产总值(GDP)、冲突历史、人口数量和地区。然而,许多非政府组织在开发特定数据集方面花费了大量时间和资金。除地区分组外,所有变量都可追溯到开放源数据库。然而,区域往往是定性的,同时也显示出提高预测准确性的整体性(Hegre 等人,2013 年;Ahner 等人,2015 年;Leiby,2017 年)。尽管先前的研究将国家划分为多个地区,但在揭示地区代理的驱动因素及其重要性方面仍存在差距。有一种假设认为,地区代表了产生共同文化的各种变量的复杂混合物,驱动着其他变量如何影响国家的不稳定性。换句话说,在一个稳健的国家冲突预测模型中,地区替代值设定了所有其他替代值的系数水平。因此,我们的任务就是发展这些地区,使其他独立变量的预测影响最大化。
本研究考虑的变量远远多于以往文献中考虑的变量,在发展整体文化概念的同时,还形成了区域,以通过文化界限更好地模拟国家冲突。最值得注意的是,它研究了在建模过程中需要考虑的最佳区域数量,以及每个区域的地理边界划分,同时还考虑了数据的相似性。

