

深度学习在敏感领域的迅速应用带来了巨大的好处。然而,这种广泛的应用也带来了严重的漏洞,尤其是模型反演(MI)攻击,这对个人数据的隐私性和完整性构成了重大威胁。这些攻击在生物识别、医疗保健和金融等应用中的日益普及,促使人们迫切需要了解其机制、影响和防御方法。本综述旨在填补文献中的空白,通过提供关于MI攻击和防御策略的结构化且深入的回顾。我们的贡献包括MI攻击的系统分类、对攻击技术和防御机制的广泛研究,以及对这一发展中的领域面临的挑战和未来研究方向的讨论。通过探讨MI攻击的技术性和伦理性影响,本综述旨在提供对AI驱动系统对隐私、安全和信任影响的深入见解。与本综述相结合,我们还开发了一个全面的资源库,以支持MI攻击和防御的研究。该资源库包括最前沿的研究论文、数据集、评估指标和其他资源,以满足对MI攻击和防御以及更广泛的AI安全与隐私领域感兴趣的初学者和经验丰富的研究人员的需求。该资源库将持续维护,以确保其相关性和实用性。资源库可以通过以下链接访问:https://github.com/overgter/DeepLearning-Model-Inversion-Attacks-and-Defenses。关键词:深度学习,模型反演(MI)攻击,隐私,安全
1 引言
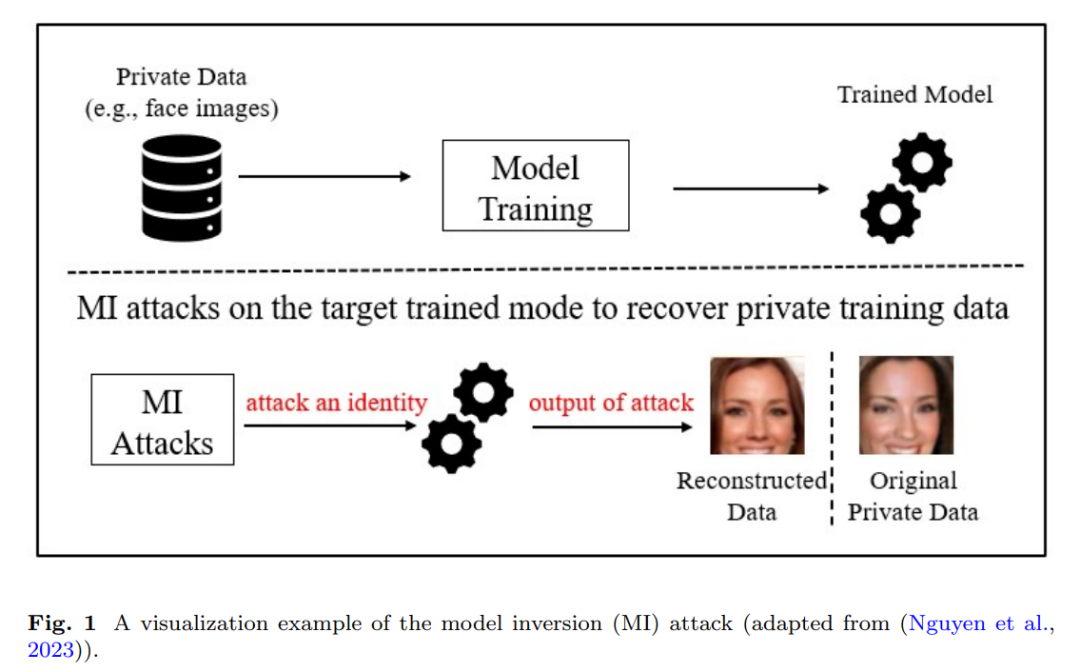
1.1 背景随着深度学习模型在敏感应用中的日益集成,强大的隐私和安全措施变得至关重要。尽管深度学习机制提供了前所未有的预测准确性,但它也带来了与模型如何编码和保留训练数据相关的漏洞(Rigaki 和 Garcia, 2023;Sen 等, 2024)。复杂的架构,如卷积神经网络(CNN)和变换器,通常在泛化能力上表现出色,但可能会不经意地记住训练数据的细节。在隐私敏感的应用中,这种记忆可能构成重大风险,因为关于训练数据的间接推断可能会导致严重后果。在威胁深度学习系统的主要攻击(例如,模型提取、模型反演(MI)、数据投毒和对抗攻击)中(He 等, 2020),MI 攻击由于能够从训练数据集中提取敏感信息并破坏用户隐私而尤为突出(Gong 等, 2023)。MI 攻击由 Fredrikson 等人(Fredrikson 等, 2014)提出,利用输入数据和模型学习参数之间的关系来恢复敏感信息。MI 攻击的影响不仅仅是侵犯个人隐私,它还破坏了对机器/深度学习系统在关键应用中的信任,如生物识别、医疗保健分析和金融建模。例如,在人脸识别系统中使用 MI 攻击,攻击者可以近似训练数据集中的面部特征并重建人脸图像,从而破坏生物识别系统的安全性(Yang 等, 2023;Tran 等, 2024;Qiu 等, 2024)。在医疗保健系统中,泄露的敏感患者数据可能违反伦理标准并导致法律后果(Dao 和 Nguyen, 2024)。类似地,在金融系统中,私人交易数据或信用评分可能会受到 MI 攻击的影响(Milner, 2024)。除了隐私问题外,这些攻击还可能削弱用户对机器/深度学习系统的信任,因为用户可能失去对其个人或敏感信息安全性的信心。图1展示了 MI 攻击的可视化示例。从技术角度来看,MI 攻击利用深度学习模型固有的脆弱性,即过拟合或记忆训练数据中的模式(Titcombe 等, 2021)。研究人员已集中精力了解加剧这种脆弱性的因素,并开发稳健的防御机制。影响 MI 攻击成功的因素有几个(Fredrikson 等, 2015;Shokri 等, 2017)。首先,访问模型:攻击者需要访问模型的输出、架构或参数。在白盒场景中,攻击者对模型有完全的了解,包括其架构和参数,而在黑盒场景中,攻击者只能访问输出。其次,模型架构:不同的模型保留关于训练数据的不同信息量。复杂的模型,如深度神经网络(DNN),特别容易受到 MI 攻击,因为它们更可能记住并存储关于输入的详细信息。第三,数据相关性:MI 攻击通常利用输入数据和模型输出之间的相关性。通过了解输入的小变化如何影响模型输出,攻击者可以微调原始数据的重建。防御 MI 攻击提出了独特的挑战。首先,设计防御策略需要平衡模型的效用和预测能力与减少隐私保护机制的风险。其次,MI 攻击通常只需要有限的信息,如访问模型输出或中间特征,而不是完全访问模型参数或训练数据(Han 等, 2023;Fang 等, 2023b)。因此,防止这些攻击并非易事。此外,隐私保护技术往往会降低模型性能,因此需要在准确性和隐私之间进行仔细的权衡。MI 攻击突显了深度学习模型中的一个关键漏洞,强调了需要强有力的防护措施来保护敏感信息。本综述探讨了 MI 攻击的分类,并审视了为减轻这些威胁而提出的防御策略。1.2 现有的 MI 攻击与防御综述已有一些关于 MI 攻击和防御的综述,提供了关于这种隐私威胁的机制、挑战和对策的宝贵见解。这些综述总结如下。Zhang 等人(Zhang 等, 2022)发现,通过名为梯度反演(GradInv)攻击的技术,可以从梯度中重建训练样本。这些攻击展示了攻击者如何利用梯度数据危害数据隐私。作者将 GradInv 攻击分为两种主要模式(即基于范式迭代和基于递归的方法),并突出了梯度匹配和数据初始化等关键技术,以优化恢复过程。Dibbo(Dibbo, 2023)对 MI 攻击进行了系统的综述,提供了一种分类法,将 MI 攻击根据不同的方法和特征进行分类。该分类法突出了 MI 攻击与其他隐私威胁(如模型提取和成员推理)相比的独特性质,将 MI 攻击定位为具有独特复杂性和影响的攻击。作者还概述了关键的防御策略,并提出了若干开放性问题。Yang 等人(Yang 等, 2023)对联邦学习(FL)中的梯度泄漏攻击进行了深入研究,并将这些攻击分为基于优化的攻击和基于分析的攻击。前者将数据重建视为优化问题,而后者通过线性方程分析来解决问题。为了克服这些传统方法的局限性,作者提出了一种新型的基于生成的范式,大大提高了重建的准确性和效率。
Fang 等人(Fang 等, 2024)提供了对 MI 攻击和防御的全面综述,揭示了 DNN 应用中使用的不同方法和特征。他们的研究系统地分类了 MI 攻击,基于数据类型和目标任务进行分类,概述了传统机器/深度学习中的早期 MI 技术,随后将焦点转向 DNN 中的先进现代方法。作者还提供了一种防御分类法,探讨了当前减少 MI 风险的努力。Liu 等人(Liu 等, 2024)对数据重建攻击进行了系统评估,批评了以往研究过于依赖经验观察,缺乏足够的理论基础。作者引入了一种方法,使得能够对数据泄漏进行理论评估,并为重建误差建立上界,特别是对于二层神经网络。该研究确定了重建误差的上界和信息理论的下界,推动了对攻击和防御动态的理解。Shi 等人(Shi 等, 2024)对联邦学习(FL)中的梯度反演攻击(GIA)进行了综述,解决了从传统的“诚实但好奇”的服务器模型扩展到涉及恶意服务器和客户端的威胁模型的关键需求。作者根据这些对手的角色对 GIA 进行了分类,证明了传统的防御措施往往无法有效应对更具攻击性的恶意参与者。作者还详细描述了他们分类中的各种攻击策略,特别是恶意服务器和客户端如何绕过现有的防御措施,并强调了 FL 在应对这些复杂威胁时的不足之处。该研究强调了重建方法、模型架构和评估指标在塑造防御效果中的作用,强调了开发更强大的 GIA 防御的重要性。1.3 本研究的动机与贡献以上提到的现有综述在 MI 攻击及其影响的分类上做出了重要贡献。然而,这些综述通常缺乏统一的框架,未能整合来自不同范式和应用领域的最新进展,同时也未能提供关于新兴挑战及相应未来研究方向的全面总结。许多研究狭隘地集中于特定的技术、数据集或环境,忽略了对更广泛 MI 威胁的理解,尤其是在联邦学习等复杂分布式环境中的 MI 威胁。本综述旨在通过对 MI 攻击和防御的全面综合分析,弥补这些不足。通过结合理论见解与实践考虑,本综述旨在推动 MI 防御的研究,并为开发稳健的隐私保护策略提供指导。本研究的主要贡献总结如下。本研究的第一个主要贡献是提出了一种新的结构化分类法,源自近年来提出的多种技术。新的分类法提供了一个清晰、统一的框架,用于根据关键因素(如方法论、数据类型和应用领域)理解和分类 MI 攻击。这一结构化组织不仅增强了对各种场景中 MI 攻击差异和漏洞的理解,还突出研究中的空白,为探索防御策略奠定了基础。结合分类法,全面的综述概述了 MI 攻击的演变,并提供了对当前挑战和瓶颈的深入见解。根据模型架构、数据可用性、计算限制和隐私保护需求,我们探讨了几种新兴的威胁、机制和技术的交集,探讨了它们对深度学习隐私保护研究的影响。第二,综述重点关注了当前的防御策略,探讨了现有防御技术的关键优缺点。通过将不同防御方法与实际应用需求相匹配,本文分析了现有方法在适应性、计算开销和实时应用等方面的限制。基于当前的防御状况,本文提供了关于如何设计更有效防御策略的见解,并讨论了可能的未来研究方向。第三,本文提出了具有挑战性的开放性问题,特别是针对 MI 攻击的未来威胁情景。这些挑战可能涉及模型复杂性、数据隐私要求、对抗性样本和多方协作等方面。在此基础上,本文还提供了开发更强大防御体系的建议,旨在为研究人员和从业者提供有关应对当前和未来 MI 攻击挑战的战略方向。最后,本文强调了 MI 攻击在与现有防御机制相互作用时的动态性质,提出了在优化隐私保护和减少性能损失之间的深度权衡问题。通过结合各种视角和案例研究,本文为 MI 攻击和防御策略的未来研究提供了一个深刻的全景视图,力求为该领域的发展做出贡献。
