推荐系统在应对信息过载挑战中发挥着关键作用,通过基于个人用户偏好提供个性化推荐来实现。深度学习技术,如循环神经网络(RNNs)、图神经网络(GNNs)和变换器架构(Transformers),已显著推动了推荐系统的进步,增强了对用户行为和偏好的理解。然而,监督学习方法在现实生活场景中遇到数据稀疏性的挑战,这限制了它们有效学习表示的能力。为了解决这一问题,自监督学习(SSL)技术作为一种解决方案出现,它利用固有的数据结构产生监督信号,而不完全依赖于标记数据。通过利用未标记的数据并提取有意义的表示,使用SSL的推荐系统即使在面对数据稀疏性时也能做出准确的预测和推荐。在本文中,我们提供了一个针对推荐系统设计的自监督学习框架的综述,包括对超过170篇论文的彻底分析。我们探讨了九种不同的场景,使得在不同的上下文中能对SSL增强的推荐器有一个全面的理解。对于每一个领域,我们详细论述了不同的自监督学习范式,包括对比学习、生成学习和对抗学习,以展示SSL如何在各种情境中增强推荐系统的技术细节。我们始终保持相关开源材料在 https://github.com/HKUDS/Awesome-SSLRec-Papers 更新。
推荐系统在解决信息过载的挑战中扮演着至关重要的角色,通过提供基于用户独特偏好的个性化推荐来实现。这些系统旨在通过提供与用户兴趣密切相关的推荐来增强用户体验,使用户体验更加引人入胜、高效且最终更加满意。推荐系统的核心是理解用户对各种项目的偏好,这一理解是通过对用户过去的互动(如点击和购买)进行细致分析实现的。通过检查这些互动,推荐系统能够获得有关用户行为的宝贵见解,帮助它们识别模式并发现个人偏好。
得益于深度学习技术的强大表示能力,推荐系统领域经历了革命性的变革。神经网络架构在这一范式转变中起了关键作用。通过利用深度学习模型,如循环神经网络(RNNs)、图神经网络(GNNs)和变换器架构,推荐系统在理解用户偏好和行为方面达到了前所未有的水平,从而为精确和个性化的推荐铺平了道路,满足个别用户的需求和偏好。
现有的监督学习方法严重依赖于丰富的标记数据进行有效训练。然而,实际的推荐系统常常遇到数据稀疏的问题。这意味着现实生活中的推荐场景常常因为可用数据量有限或标记样本不足而受阻。因此,监督学习方法在这些场景中有效泛化和准确学习用户偏好表示方面遇到了重大困难。幸运的是,受自监督学习(SSL)的启发,SSL技术已被证明对解决数据稀疏问题十分有益。通常而言,SSL的关键思想是利用数据本身固有的结构或模式来创建学习的监督信号,而不完全依赖于外部标记数据。这使得推荐系统能够利用未标记的数据并提取有意义的表示,即使在数据稀疏的情况下也能做出准确的预测和推荐。
我们的论文提供了一个针对推荐系统专门定制的自监督学习框架的全面回顾,旨在为来自不同学科的研究人员提供一个宝贵的资源,使他们能够探索这一迅速发展的领域。在此背景下,我们的论文提出了几个重要贡献,总结如下:
全面的论文集合。我们对超过160篇探索推荐领域中自监督学习应用的论文进行了彻底的回顾,使用包括“自监督”、“对比”、“生成”、“对抗”、“变分”、“扩散”和“遮蔽自编码器”等特定关键词进行搜索,并结合“推荐”和“推荐系统”进行搜索,这些论文主要来源于KDD、SIGIR、WWW、ICLR、WSDM、CIKM、ICDE、AAAI、IJCAI、RecSys、TOIS、TKDE等知名会议和期刊。
- 开源库支持。我们的团队开发了SSLRec,一个健壮的自监督学习框架。这个用户友好的框架包括流行的数据集、标准化的数据处理、训练、测试、评估脚本以及最先进的自监督学习推荐模型。

在本节中,我们将介绍自监督学习在推荐系统中的全面分类。如前所述,自监督学习范式可以分为对比学习、生成学习和对抗学习。因此,我们的分类基于这三个类别,为每个类别提供更详细的见解。我们的整体分类如图1所示。
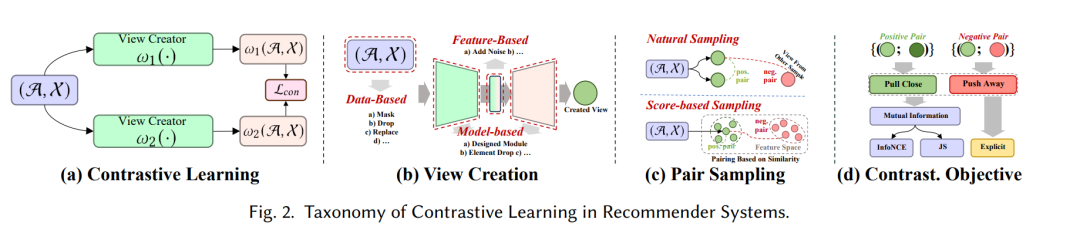
推荐中的对比学习
对比学习(CL)的基本原则涉及最大化不同视图之间的一致性。因此,我们提出了一个以视角为中心的分类法,其中包含了在应用对比学习时需要考虑的三个关键组成部分:创建视图、配对视图以最大化一致性,以及优化一致性。
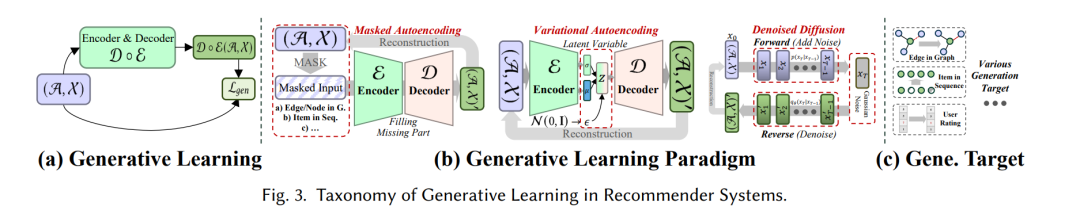
推荐中的生成学习
在生成自监督学习(GL)中,主要目标是最大化真实数据分布的似然估计。这使得学习到的有意义的表示能够捕捉数据中的基本结构和模式,随后可以用于下游任务。在我们的分类中,我们考虑两个方面来区分具有GL的各种推荐方法:生成学习范式和生成目标。
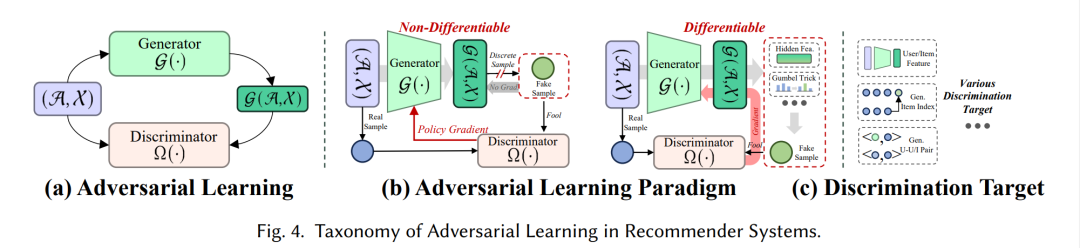
推荐中的对抗学习
在推荐系统中对抗学习(AL)的背景下,鉴别器在区分生成的假样本和真实样本中扮演着关键角色。类似于生成学习,我们提出了我们的分类法,该分类法从学习范式和鉴别目标的角度包含了推荐系统中的AL