
这项工作是DARPA资助的Active Interpretation of Disparate Alternatives(AIDA,对不同选择的积极解释)项目的一部分,该项目旨在自动建立一个知识库,可以通过查询来战略性地生成关于事件的不同方面的假设。我们作为TA1团队参与了这个项目,并开发了一个管道,可以整合文本和视觉输入,并处理这些多模态数据以捕捉由实体、事件和关系代表的事件。我们开发了基于图表示的方法,通过借鉴文本中确定的依赖关系,或借鉴我们开发的一种新方法,使用关联嵌入来创建视频上的图表示。由此产生的结构是一个知识图谱,通过查询可以战略性地产生关于事件不同方面的假设。

在我们的现代世界中,事件和情况迅速铺展,产生了大量的互联网文章、照片和视频。对这些丰富的信息进行自动分类的能力将使我们能够确定哪些信息是最重要和最可信的,以及趋势是如何随着时间的推移展开的。在本文中,我们提出了对网络上大量政治数据进行分类的系统第一部分。我们的系统接受原始的多模态输入(如文本、图像和视频),并生成一个以有意义的方式连接实体、事件和关系的知识图谱。
我们的项目是DARPA资助的Active Interpretation of Disparate Alternatives (AIDA)项目的一部分,该项目旨在自动建立一个知识库,可以通过查询来战略性地生成关于一个事件的不同方面的假说。我们作为TA1团队参与了这个项目,建立了整个系统的第一步。
我们的方法在图1中概述,并将在以下章节中详细讨论。该管道的第一步是预处理,如图1最上面一行所示。原本以多种语言书写的原始文本文件被翻译成英文,音频和视频片段被转录并翻译成英文。这些经过翻译的数据被传递到管道的第二阶段(图1的中间一行)。在这里,相关的实体(例如,人、地方、国家)被提取出来,这些实体被用来提取连接实体的关系和事件。最后,这些实体、事件和关系被传递到管道的最后阶段(图1的底行)。我们输出一个完全成型的知识图,代表我们从原始输入文档中收集到的信息。这个知识图谱包括实体以及它们之间的联系。
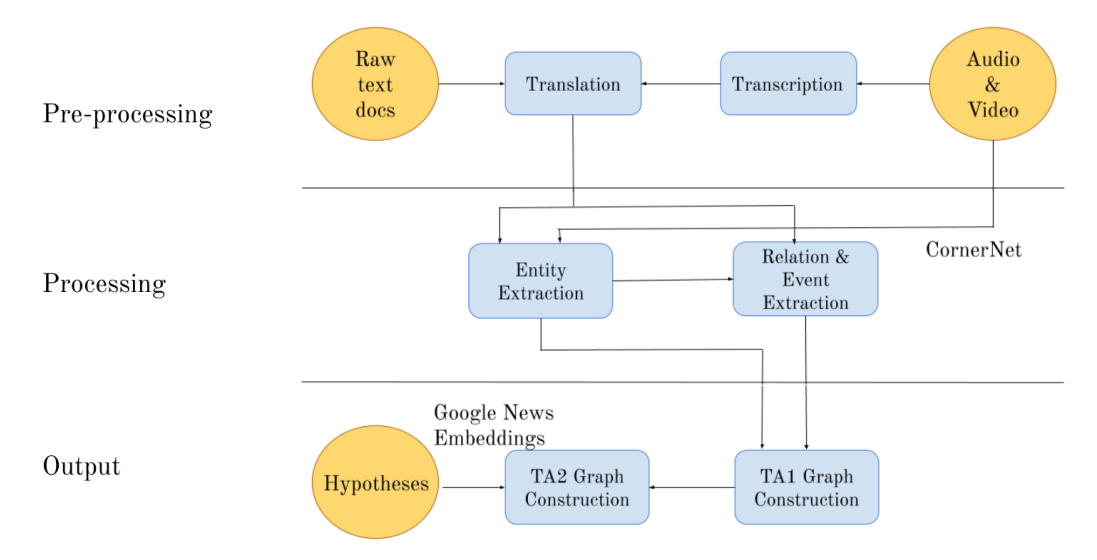
图1:AIDA的整体管道。我们的系统部分接收原始文本文件(左上)和音频和视频(右上),并输出一个知识图谱(右下)。


