对图像的细粒度理解有两个方面:视觉理解和语义理解。前者致力于理解图像中对象的内在属性,而后者旨在将不同的对象与一定的语义联系起来。这些都是深入理解图像的基础。今天的深度卷积网络默认架构已经在捕捉图像的2D视觉外观,并随后将视觉内容映射到语义类方面表现出了惊人的能力。然而,关于细粒度图像理解的研究,如推断固有的3D信息和更结构化的语义,却很少被探索。在本文中,我们通过提出“如何更好地利用几何来更好地理解图像?”
- 第一部分研究了基于三维几何的视觉图像理解。有可能用无纹理的3D形状自动解释图像中的各种视觉内容。开发了一种深度学习框架,从2D图像中可靠地恢复一组3D几何属性,如物体的姿态及其形状的表面法线。
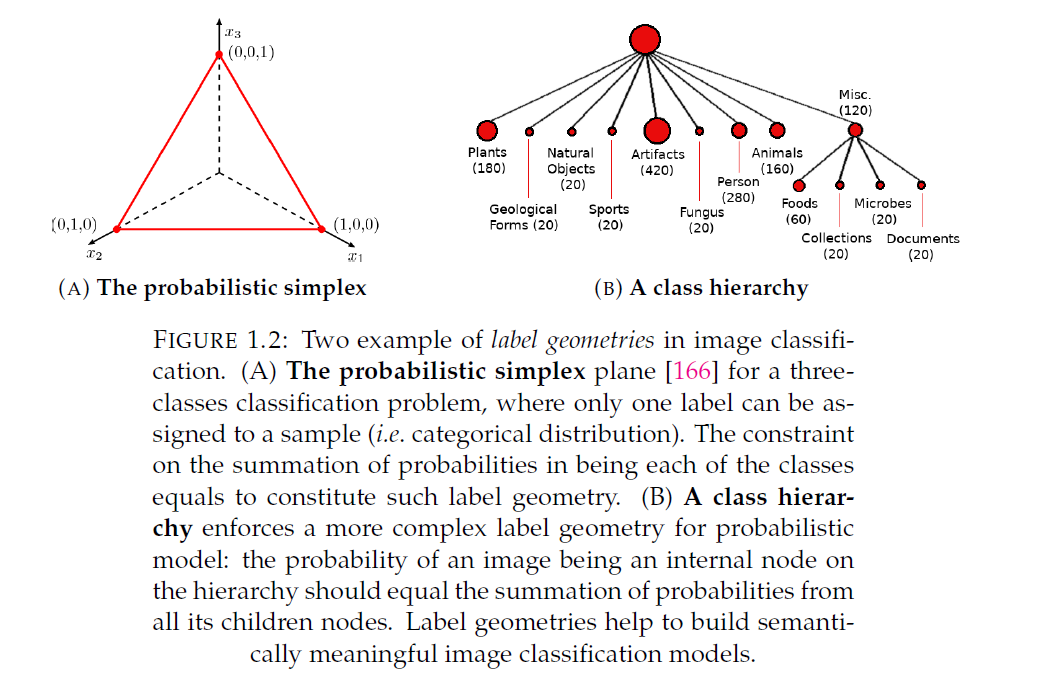
- 在第二部分中,我们探索了用于图像语义理解的标签几何。发现一组图像分类问题具有几何上相似的概率空间。因此,引入标记几何,统一了one-vs rest分类、多标签分类和分布外分类放在一个框架中。此外,学习的层次标签几何可以平衡图像分类器的准确性和特异性。
引言
多伦多大学于2012年取得了彻底改变现代计算机视觉的突破[83]。他们的深度学习架构AlexNet在模拟大规模ImageNet计算机视觉挑战[134]中取得了巨大的成功,在该挑战中,一个算法被要求将数百万张图像分类为1000个类别。这个图像分类模型,被称为深度卷积神经网络(DCNN),是受到我们大脑中数十亿相互连接的神经元的启发。通常,深度卷积神经网络建立在一堆卷积层之上,每一层包含数十万个功能连接,即人工神经元。视觉表征被一层一层地处理和转换,类似于大脑视觉皮层中神经元的功能。与传统的手工特征相比,例如[144,14,104,22,39],DCNN可以通过梯度反向传播以端到端的方式从头开始训练。这使我们在设计手工特征描述符时摆脱了对专业知识的依赖。如今,更深[143]、更广[176]和拥有更多连接[66]是新出现的深度神经网络架构的关键特征[70,33,147,41]。随着深度神经网络容量的不断增加,计算机在图像分类[58]上的准确率正达到人类水平,甚至超越人类。在目标检测[47,132,59,130,101],动作识别[142,150,32,159,15,161,174],创建艺术或照片逼真的[181,73]图像以及许多其他应用中也取得了类似的成功。
尽管最近在使用深度学习解决计算机视觉问题方面取得了进展,但对图像进行细粒度的理解仍然具有挑战性。通常,对图像的理解是双重的:视觉理解和语义理解。前者努力理解图像中物体的内在属性,例如2D视觉外观、3D形状、3D位置和3D姿态等,而后者旨在将不同的物体与特定的语义联系起来,例如物体的类别名称[47,132,59,130,101]、动作[142,150,32,159,15,161,174]或属性[135,99,158,135]。所有这些构成了深入理解我们希望机器拥有的图像的基础。当今的深度卷积网络默认架构已经在捕捉二维域图像的视觉外观,并将视觉内容映射到特定的语义类(如图像分类、动作识别)方面表现出了惊人的能力。然而,关于细粒度图像理解的研究,如推断固有的3D信息和更结构化的语义,却很少被探索。本文通过研究如何利用几何来更好地理解图像,在这两方面做出了贡献。激发我们的角度来看待图像的视觉理解和语义理解问题。