

作为计算机视觉中最基本的任务,目标检测和分割在深度学习时代取得了巨大的进步。由于昂贵的手动标注,现有数据集中注释的类别通常规模较小且预先定义,即使是最先进的检测器和分割器也无法在封闭词汇之外进行泛化。为了解决这个限制,近年来对开放词汇检测(OVD)和分割(OVS)越来越受关注。在这项综述中,我们对OVD和OVS的过去和最近的发展进行了全面回顾。为此,我们根据任务类型和方法论制定了一个分类系统。我们发现,对于不同的方法论,包括:视觉-语义空间映射,新颖的视觉特征合成,区域感知训练,伪标签,基于知识蒸馏的方法和基于迁移学习的方法,弱监督信号的使用和许可能够很好地区分它们。所提出的分类系统适用于不同的任务,包括目标检测,语义/实例/全景分割,三维场景和视频理解。在每个类别中,我们都对其主要原理、关键挑战、发展路线、优势和缺点进行了深入讨论。此外,我们还对每个方法的关键组成部分进行了基准测试。最后,我们提供了几个有前景的方向,以激励未来的研究。
https://www.zhuanzhi.ai/paper/c6e614f147b3bd4206b1762b160532d5
目标检测和分割是计算机视觉中核心的高级感知和场景理解任务。它们是许多现实世界应用的基石,包括自动驾驶[1],[2],医学图像分析[3]和智能机器人[4],[5]等。在给定图像或一组点云的情况下,目标检测[6],[7]会预测出围绕目标紧密包围的边界框,并附带它们的类别标签,而分割会将像素或点划分为一个语义连贯的区域或体积(语义分割)[8],一个具有独特ID的实例(实例分割)[9],或同时包含物体(人、汽车等)和背景(草地、天空等)的区域(全景分割)[10]。过去十年中,由于先进的深度神经网络架构(如卷积神经网络CNNs)[6],[8],[9],[11],[12],[13],[14],[15],[16],[17]和Transformer-based模型[18],[19],[20],[21],[22],[23],[24],[25],目标检测和分割任务取得了稳步进展。然而,现有的目标检测器和分割器只能在每个特定数据集中定位预定义的语义概念(或类别),其数量通常规模较小,例如Pascal VOC中的20个类别[26],COCO中的80个类别[27],甚至最大的数据集LVIS也仅注释了1,203个类别[28]。相反,我们的人类感知系统可以将任意视觉概念与开放类名或自然语言描述相联系。封闭集合的本地化限制阻碍了当前检测器和分割器在复杂场景中的应用。 为了解决目标定位任务中的封闭词汇限制,研究努力致力于零样本或开放词汇检测和分割。在发展的早期,零样本检测(ZSD) [29],[30],[31]和分割(ZSS) [32],[33]首次被提出,试图在没有访问任何未标注的未知视觉样本的情况下进行尝试。为了实现这一目标,当前主流的ZSD和ZSS方法总是将“分类器”的可学习权重替换为固定的类别语义嵌入,例如Word2Vec [34] (W2V),FastText [35] (FT),GloVe [36],或来自BERT [37],这些嵌入可以被利用来将已见(基类)的知识传递给未见(新类)的对象。然而,由于这些语义嵌入仅在文本语料库上进行无监督训练,它们与视觉特征缺乏对齐,因此在用作视觉空间校准的锚点时存在噪声[38],[39]。
随后,新提出的开放词汇检测(OVD) [40]和分割(OVS) [41],[42],[43]允许模型在带有未标注新对象的图像上进行训练。它们通常通过弱监督信号来解决封闭集合的限制,例如图像-文本对(图像标题或图像级标签),或者来自大型预训练的视觉-语言模型(VLMs),如CLIP [44]。来自CLIP [44]的文本嵌入可以很好地与视觉模态对齐。因此,与ZSD和ZSS相比,OVD和OVS在性能上取得了巨大的飞跃。由于其巨大的应用价值,近年来提出了大量的方法,使得研究人员难以跟上它们的步伐。然而,据我们所知,目前只有少数相关综述可用,而这些综述只关注于有限的任务和设置,因此迫切需要一份更全面的综述,涵盖所有任务和设置。
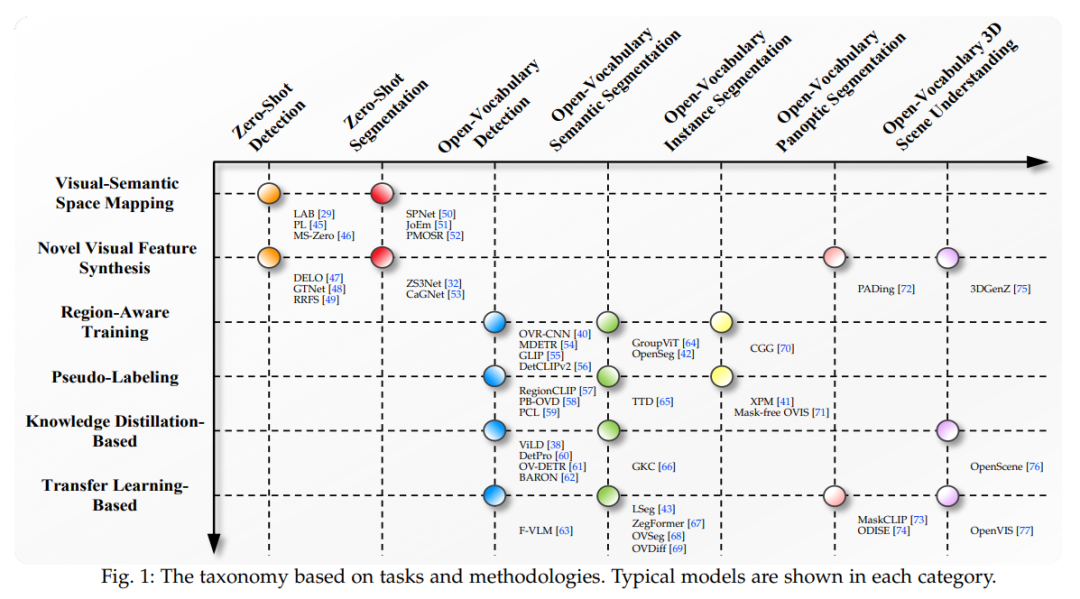
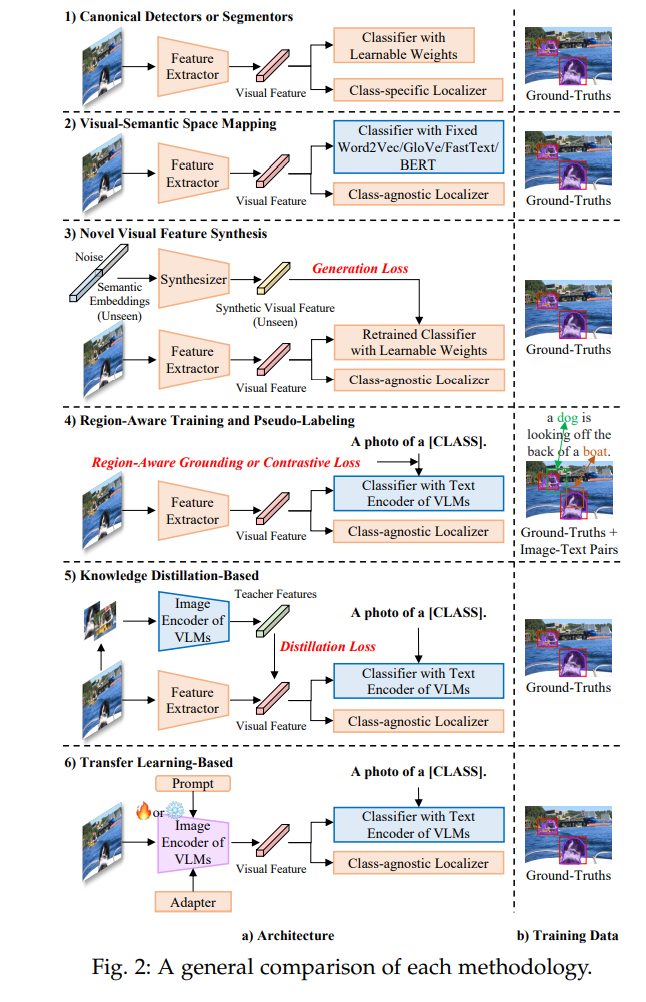
在这篇论文中,我们对不同任务和设置进行了全面的回顾,包括零样本/开放词汇检测,零样本/开放词汇语义/实例/全景分割,以及三维场景和视频理解。为了组织来自这些多样化任务和设置的方法,我们需要回答一个问题:如何建立一个分类系统,可以区分零样本和开放词汇的设置,同时抽象出跨任务的通用方法学?我们发现,是否允许访问弱监督信号,以及如果允许,如何利用它们是分类的关键。因此,我们根据任务和方法学构建了一个分类系统,如图1所示。零样本和开放词汇的设置是通过允许弱监督信号的访问与否来区分的,并且不同任务在每个设置下共享相同的方法学。不同方法学的一般框架总结在图2中。
具体来说,零样本检测(ZSD)和零样本分割(ZSS)可以粗略地分为以下两类:
-
视觉-语义空间映射。虽然在单一模态中,视觉和语义空间可能具有辨别能力,但没有直接跨模态的训练机制来挖掘两个空间之间的相互关系。因此,学习从视觉到语义空间的映射,从语义到视觉空间的映射,或通过定制的损失函数进行视觉-语义空间的联合映射对于实现可靠的跨空间相似度测量至关重要。对传统的封闭集合检测器/分割器进行了两个主要的架构修改:1) 可学习分类器被固定的语义嵌入替代(例如W2V [36] / GloVe [36] / FT [35] / BERT [37]);2) 类别特定的定位分支被替换为类别无关的分支,依靠其泛化能力来发现新的对象。
-
新颖的视觉特征合成。由于先前方法中缺乏未知类别的注释,对于未见类别的置信度常常被已见类别的样本所淹没。为了缓解偏置问题[78],这种方法利用了额外的生成模型[79],[80],[81],根据语义嵌入和随机噪声向量来合成假的未见视觉特征。生成损失的目标是逼近真实视觉特征的潜在分布。然后在纯粹的真实已见和生成的未见视觉特征上重新训练检测或分割头中的分类器嵌入。一旦允许访问弱监督信号,OVD和OVS方法可以主要分为以下四类:
1) 区域感知训练。这类方法旨在通过廉价且丰富的图像-文本对(图像标题或图像级标签)来隐式地在图像和文本之间建立对齐关系,除了真实的标注数据集之外。它的主要特点是施加双向弱监督 grounding 或对比损失,将同一图像-文本对中的区域和单词拉近,同时将批次中的其他负样本推开。通过这些额外的区域感知损失,模型可以学习跨模态对齐并扩展词汇表。在架构方面,它采用了VLMs中文本编码器的文本嵌入,而不是在零样本设置中仅训练在文本语料库上的语义嵌入。
2) 伪标记。伪标记方法也利用了图像-文本对,除了真实标注数据,但它明确地构建伪区域-文本对来在师生框架下学习对应关系。它可以看作是一种硬对齐,即一个区域只能对应一个单词,反之亦然,而不是区域感知训练中的软对齐,其中一个单词可以对应多个由softmax加权的区域。伪标记可以采用VLMs作为教师来生成伪标签,但也可以视为不使用VLMs进行自训练(教师是模型本身)。需要注意的是,区域感知训练也不使用VLMs的图像编码器。
3) 基于知识蒸馏的方法。通过对比学习训练的VLMs(如CLIP)在各种下游任务中具有优越的零样本识别能力。该组方法主要将教师模型,即VLMs的图像编码器中的区域嵌入,蒸馏到学生模型中,以使它们与VLMs的文本嵌入相兼容,使用检测或分割数据。与区域感知训练和伪标记不同,它不在图像-文本对上训练,但需要VLMs的图像编码器。
4) 基于迁移学习的方法。由于知识蒸馏需要将每个感兴趣区域(RoI)反复转发到VLMs的图像编码器,因此不可避免地会导致大量的内存消耗。基于迁移学习的模型在VLMs的图像编码器上增加了可忽略的额外计算开销。它们可以进一步分为:1) VLMs的冻结图像编码器作为特征提取器;2) 在下游数据上对VLMs的图像编码器进行微调;3) 冻结VLMs的图像编码器,并在真实标注数据上训练可学习的视觉提示 [82];4) 在下游数据集上训练轻量级适配器,附加到冻结的VLMs的图像编码器上。关于基于迁移学习的模型的更详细框架在图5中给出。
在这篇综述中,我们使用术语“开放词汇”来总结传统的零样本和新兴的开放词汇设置的方法,原因如下:1) 零样本和开放词汇设置都允许进行超出固定词汇的目标检测和分割;2) 两种设置之间的方法学可以共享,例如新颖的视觉特征合成可以无缝地转换为开放词汇设置;3) 鉴于图像-文本对的存在和大型VLMs的兴起,开放词汇设置更加现实和有前景。目前的OVD和OVS实验设置因方法而异,导致性能比较不完整,并且直接比较可能对某些方法不公平。为了缓解这个问题,我们另外提供了一个包含每种方法的关键组成部分的综合基准。按照我们的分类系统,本文的其余部分组织如下:第2节描述了OVD和OVS的形式化定义,相关领域和任务,传统的封闭集合检测器和分割器,大型VLMs,以及常见的数据集和评估协议。然后,我们在第3节和第4节回顾ZSD和ZSS,第5节和第6节回顾OVD和OVS。开放词汇的三维场景理解和视频实例分割也在第7节中进行了介绍。最后,第8节得出了结论,讨论挑战和有前景的未来方向。



