Nature长文:打破AI黑盒的“持久战”

大数据文摘转载自数据实战派
2020年2月,随着 COVID-19在全球迅速传播且抗原检测难以获得,一些医生转向人工智能(AI)来尝试诊断病例。一些研究人员采用深度神经网络通过查看X射线和胸部计算机断层扫描(CT)扫描来快速区分患有COVID-19肺炎的人和未患肺炎的人。
“在COVID-19大流行的早期,人们竞相构建工具,尤其是AI工具来提供帮助”,西雅图华盛顿大学的计算机工程师Alex DeGrave说,“但研究人员并没有注意到许多人工智能模型已经决定走一些捷径” 。
AI通过分析被标记为COVID-19阳性和阴性的X射线图片来训练模型,然后利用它们在图像之间发现的差异性来进行推断,但是在当时面临着一个问题,“可用的训练数据并不多。”DeGrave说。
多家医院公开了COVID-19患者的X射线照片(被标记为COVID-19阳性),美国国立卫生研究院在大流行之前收集的肺部图像库提供了未感染COVID-19的X射线数据(被标记为COVID-19阴性),这些数据在被用作训练时存在无法忽视的误作用,例如,许多X射线会使用字母R来标记一个人身体右侧,从而方便放射科医生正确定位图像与人体的关系,但是不同医院采用的字母R的外观不同,同时,大多数COVID-19阴性图片来源单一,这使得最终使用这些数据训练的模型不仅会根据照片上显示的生物特征进行推断,还会根据图片上字母R的风格与位置进行推断(如图1所示)。
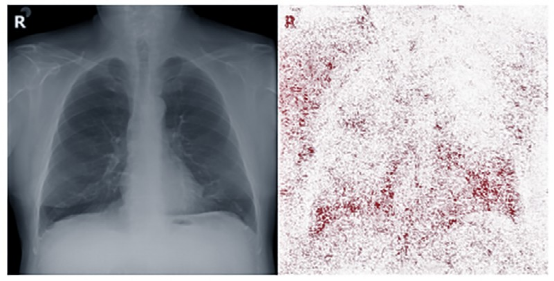
图1 用作训练的X射线图片
DeGrave和 Joseph Janizek 都是计算机科学家Su-In Lee位于西雅图的生物和医学科学可解释AI实验室的成员,他们于2021年5月在《Nature Machine Intelligence》上发表了一篇论文,报告了前文所述问题。
机器学习模型的决策过程通常被学者称为黑匣子,因为研究人员通常只知道模型的输入和输出,但很难看到模型里面究竟发生了什么。
DeGrave和Janizek 使用旨在测试AI系统并解释它们为什么这样做的技术来打开这些黑盒子,即构建可解释的AI模型。
构建可解释的AI(eXplainable AI,XAI)有很多优势,在医疗环境中,了解模型系统做出特定诊断的原因有助于让病理学家相信它是合法的,因为在某些情况下,法律要求做出解释。例如,当一个贷款系统就用户贷款资格做出决定时,美国和欧盟都要求提供证据,证明拒绝信贷不是出于法律禁止的原因(例如种族或性别)。
深入了解AI系统的内部工作原理还可以帮助计算机科学家改进和完善他们创建的模型,甚至可能会带来关于如何解决某些问题的新想法。
然而,只有当XAI给出的解释本身是可理解和可验证的,并且构建模型的人认为这是值得的努力时,XAI的好处才能实现。
神经元
DeGrave和Janizek研究的深度神经网络因其不可思议的能力而广受欢迎,因为它们能够通过曝光来了解照片中的内容、口语的含义等等。
这些神经网络的工作方式与人脑相似,就像某些活性神经细胞响应外部刺激从而以某种模式发射一样。例如,神经网络中的人工神经元会在他们收到的输入的基础之上,当看到一只猫时会触发与看到一棵树不同的模式,即神经元会寻找到二者之间的差异性。
在这种情况下,神经元是数学函数,输入数据以数字形式进入系统。例如描述照片中像素的颜色,然后神经元对该数据执行计算。在人体中,神经元只有在收到的刺激超过某个电阈值时才会发出信号。类似地,人工神经网络中的每个数学神经元都用一个阈值加权。
如果计算结果超过该阈值,则将其传递给另一层神经元进行进一步计算。最终,系统会学习到输出数据与输入数据之间关系的统计模式。例如,被标记为有猫的图像将与那些标记为没有猫的图像存在系统差异,然后这些明显的差异可以帮助AI模型在其他图像中确定猫存在的可能性。
神经网络的设计与其他机器学习技术存在差异。
神经网络模型作用于输入的计算层(即hidden layer)越多,解释模型在做什么的难度就越大。马萨诸塞州波士顿大学的计算机科学家Kate Saenko说,“简单的模型,例如小型决策树并不是真正的黑匣子。小型决策树‘基本上是一组规则’,人类可以很容易地理解该模型在做什么,因此它本质上是可解释的。然而,深度神经网络通常过于复杂,一个神经网络涉及数百万计算,或者现在更可能是数十亿计算,学者们很难对其内在工作机理进行解释”。
一般来说,解释深度神经网络神秘工作原理的工作涉及到找出输入数据的哪些特征会影响输出结果。
帮助DeGrave和Janizek确定胸部 X 射线图片上的方向标记(字母R)影响诊断的一种工具是显着性图(Saliency Map),这是一种用颜色编码的图表,显示计算机在推断时最关注图像的哪一部分。如图2所示。
Saenko 和她的同事开发了一种称为D-RISE(用于解释AI的检测器随机输入采样)的技术来生成此类映射。研究人员拍摄了一张照片,例如,一个装满鲜花的花瓶(图2),并系统地屏蔽了图像的不同部分,然后将其展示给负责识别特定对象(例如花瓶)的AI模型。然后,他们记录每组像素的模糊程度如何影响结果的准确性,并根据每个部分对识别过程的重要性对整张照片进行颜色编码。
不出所料,在一张装满鲜花的花瓶的照片中,花瓶本身被明亮的红色和黄色照亮,这表明AI识别花瓶时,花瓶本身的存在很重要。但这并不是图片中唯一突出显示的区域。“显着性一直延伸到一束鲜花,”Saenko说,“它们没有被标记为花瓶的一部分,但模型了解到,如果你看到鲜花,这个物体更有可能是花瓶。”D-RISE突出强调了会导致 AI 模型改变其结果的因素。
“这有助于了解他们可能犯了什么错误,或者他们是否出于错误的原因做某事,”Saenko说,他在该领域的工作部分由美国国防高级研究中心运营的现已完成的XAI项目资助。
更改输入数据以识别重要特征是探究许多AI模型的基本方法。
但宾夕法尼亚州匹兹堡卡内基梅隆大学的计算机科学家Anupam Datta表示,这项任务在更复杂的神经网络中变得更具挑战性,在这些复杂的情况下,科学家们不仅要弄清楚哪些特征在模型推断中发挥作用以及这个作用效果有多大,而且还要弄清楚一个特征的重要性如何随着其他特征的变化而变化。
“因果关系仍然存在,因为我们仍在试图找出哪些特征对模型的预测具有最高的因果影响,” Datta说,“但测量它的机制会发生一点变化。”,与Saenko的显着性图一样,Datta系统地屏蔽了图像中的单个像素,然后为图像的该部分像素分配一个数学值,表示由于遮挡该部分而导致的变化幅度。看
到哪些像素是最重要的,可以告诉Datta隐藏层中的哪些神经元在结果中的作用最大,从而帮助他更好地解释模型工作原理。
可解释性的好处
DeGrave和Janizek通过另一种复杂神经网络来测量显著性图,这种网络叫做生成对抗网络(generative adversarial network,GAN)。
典型GAN由一对网络组成,一个负责生成数据(如街道的图像),另一个尝试确定该输出是真实还是虚假的。这两个网络不停地以这种方式交互,直到第一个网络可靠地创建能够欺骗另一网络的图像。在他们的案例中,研究人员要求GAN将COVID-19阳性X射线突变转为COVID-19阴性图片,通过查看GAN修改了X射线图片的哪些方面,研究人员可以确定图片的哪一部分对AI模型产生了作用,从而增加模型可解释性。
尽管GAN原理简单,但研究人员对这对网络的微妙动态改变还不是很清楚。“GAN生成图像的方式很神秘,给定一个随机输入的数字,GAN最终会输出一张看起来很真实的图片”,计算机科学家Antonio Torralba说。Torralba和他的团队负责剖析GAN,查看GAN的每个神经元到底在做什么,就像Datta一样,他们发现GAN中一些神经元会特别专注于某些特定概念。“我们找到了负责绘制树木的神经元组,负责绘制建筑物的神经元组以及绘制门窗的神经元”,Torralba说。

图2 显著性图示例(图中指出AI在识别花瓶时也注意到了花瓶中的花朵)
Torralba说,能够识别出哪些神经元正在识别或产生哪些物体,这为改进神经网络提供了可能性,而无需向其展示数千张新照片。
如果一个模型已经被训练来识别汽车,但它所训练的所有图像都是铺砌路面上的汽车,那么当展示一张雪地上的汽车图片时,模型可能会无法识别该车。但是了解模型内部连接的计算机科学家能够调整模型以识别一层雪,使其相当于铺砌的表面,从而提高模型识别该类型图片的准确率。类似地,可能想要自动创建不可能的场景的计算机特效设计师可以手动重新设计模型来实现这一点。
可解释性的另一个价值是了解机器执行任务的方式可以让使用模型的人了解模型如何以不同的方式做事,并修改模型做其得更好。
计算生物学家 Laura-Jayne Gardiner 训练了一个AI来预测哪些基因在调节生物钟(控制一系列生物过程的内部分子计时器)中起作用。Gardiner和她在IBM Research Europe和英国诺里奇生命科学研究小组Earlham Institute的同事也让计算机突出了它用来决定基因是否可能在昼夜节律中发挥作用的特征。
“我们只关注基因调控的启动子,”加德纳说,“但AI在基因序列中发现了研究人员会忽略的线索”,加德纳解释说;该团队可以在实验室的研究中使用AI来进一步完善其对生物学的理解。
AI准确性和可信度
卡内基梅隆大学的计算机科学家 Pradeep Ravikumar 说,解释AI是一个开始,但也应该有一种方法来量化它们的准确性,他正在研究自动化这种评估的方法,他认为对人类来说似乎有意义的解释实际上可能与模型实际在做什么几乎没有关系。
“如何客观评估解释AI这一问题仍处于早期阶段,”Ravikumar 说,“我们需要得到更好的解释,也需要更好的方法来评估解释。”,测试解释真实性的一种方法是对它所说的重要特征进行小的改动。
如果解释正确,那么输入的这些微小变化应该会导致输出的巨大变化。样,对不相关特征的大改动,比如,从猫的照片中删除一辆公共汽车,应该不应该影响模型判断结果。如果更进一步评估AI,不仅可以预测哪些特征很重要,还可以预测如果对这些特征进行微小更改,模型的推测判断结果将如何变化。“如果一个解释实际上是在解释模型,那么它就会更好地了解模型在这些微小变化下的表现”Ravikumar 说。
解释AI内在工作原理有时看起来像是一项繁重的工作,以至于许多计算机科学家可能会想跳过它,并从表面上看待AI的结果。但至少某种程度的可解释性相对简单,例如,显着性图现在可以快速且廉价地生成,相比之下,训练和使用GAN更加复杂和耗时。
“你肯定必须非常熟悉深度学习的东西,以及一台带有一些图形处理单元的好机器才能让它工作,”Janizek 说。他的团队尝试的第三种方法——使用照片编辑软件手动修改数百张图像以确定某项特征是否重要——甚至更加耗费人力。
机器学习社区的许多研究人员也倾向于在模型可解释性和准确性之间进行权衡。他们认为,庞大的计算量使得神经网络输出更准确,也使它们超出了人类的理解范围。但有些人质疑这种权衡是否真实,Janizek 说。“最终可能会出现这样的情况,即一个更可解释的模型是一个更有用的模型和一个更准确的模型。”
Ravikumar 说,无论可解释性的挑战是大是小,一个好的解释并不总是足以说服用户依赖一个系统,知道为什么人工智能助手(例如亚马逊的 Alexa)以某种方式回答问题可能不会像禁止滥用私人对话记录的法律那样促进用户之间的信任,也许医生需要临床证据证明计算机的诊断随着时间的推移证明是正确的。政策制定者可能会要求将有关使用此类系统的一些保护措施写入法律。
然而,在解释领域,人工智能研究人员已经取得了长足的进步。Torralba 说,尽管可能仍有一些细节需要制定以涵盖正在使用的各种机器学习模型,但这个问题可能会在一两年内得到解决。
他说,“人们总是谈论这个黑匣子,我们不认为神经网络是黑匣子。如果他们工作得非常好,那么如果你仔细观察,他们所做的事情是有道理的。”


