

随着大语言模型(LLM)的快速发展,强化学习(RL)已经成为代码生成和优化领域中的关键技术。本文系统地综述了强化学习在代码优化和生成中的应用,重点介绍了它在提升编译器优化、资源分配以及框架和工具开发方面的作用。随后的章节首先深入探讨了编译器优化的复杂过程,分析了强化学习算法在提高效率和资源利用率方面的应用。接着,讨论转向强化学习在资源分配中的作用,重点涉及寄存器分配和系统优化。我们还探讨了框架和工具在代码生成中的新兴作用,分析了如何将强化学习集成进来以增强其能力。本文综述旨在为研究人员和实践者提供一个全面的资源,帮助他们利用强化学习推动代码生成和优化技术的发展。
1 引言
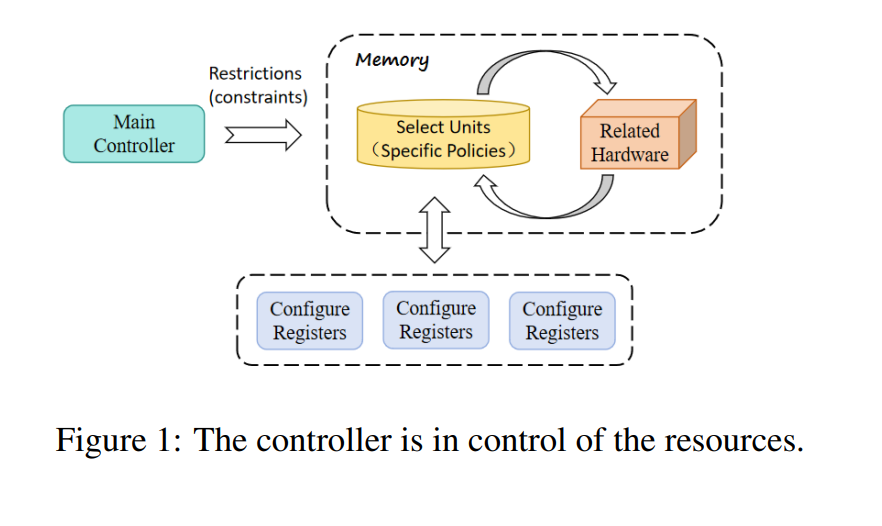
随着软件系统的复杂度不断增加,开发周期也越来越紧张,手工编写代码和优化在一定程度上变得不切实际。因此,利用自然语言(NL)进行代码生成和优化已经成为提高软件开发效率的关键(Zhu 等,2022;Allamanis 等,2018)。与此同时,随着自然语言处理(NLP)技术的进步,特别是在大语言模型(LLM)方面的突破,为代码生成开辟了新的可能性。编译器优化在提高软件性能和减少资源消耗方面至关重要。传统的编译器优化依赖于诸如自动调优(Basu 等,2013)等技术,而深度学习方法在优化编译器序列(Li 等,2020)时存在泛化困难。尽管大语言模型(LLM)在代码生成和优化方面有所改善(Cummins 等,2023),但它们往往产生偏向或不一致的输出(Wang 等,2023b;Barke 等,2023),且需要时间消耗较大的预训练过程,尤其是使用特定于代码的模型,如 Code T5(Wang 等,2021a)和 Code T5+(Wang 等,2023c)。在图1中,我们展示了内存管理的示意图,其中主控制器根据约束条件选择特定策略,随后与相关硬件组件(如编译器)进行交互,配置寄存器,从而实现整体优化效果。
当前的代码大语言模型(Code LLM)研究更多集中在与代码相关的语料库的预训练上。强化学习(RL)作为一种能够在复杂环境中学习最优策略的方法,为代码生成(Le 等,2022a)和优化(Bendib 等,2024)提供了一种新的思路。它能够处理无标签的输入输出对,并通过试错的方式利用现有知识进行策略改进。使用强化学习进行代码优化和编译器增强的优势在于,它能够减少对预训练模型的依赖,并使大语言模型(LLM)能够更灵活地适应不断变化的环境条件。图2展示了强化学习在编译器优化和代码生成中的相关应用研究。鉴于强化学习在提高软件性能和效率的各个关键方面具有巨大的应用潜力,本文探讨了强化学习如何成功地应用于代码生成与优化,并提供了更广泛的RL相关问题概述,旨在鼓励更多研究者从强化学习的进展中受益。

