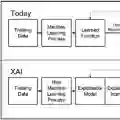
机器学习正迅速发展,既作为蓬勃发展的学术学科,又作为一种有潜力改变我们日常生活方方面面的技术。我们已经见证了语音生成、药物发现、推荐算法等领域的突破,这些都得益于机器学习的帮助。务必认识到,任何机器学习的实际应用不仅限于在经过清理的数据集上创建一个准确的模型。这些现实生活中的应用是复杂的软件系统,其中模型虽然重要,但只是一个组件。大量精力也花在创建数据收集和清理管道、质量保证、模型更新工作流、系统的监控和运维上。许多从业者的经验表明,将表现良好的机器学习模型转化为性能良好的机器学习系统并不容易。这篇论文试图了解这一转化过程中的痛点,并探索适合现代数据驱动系统需求的软件架构范式。
我们首先调查了现有关于机器学习部署的报告以及它们描述的困难。将识别出的问题与典型的机器学习部署流程相匹配后,我们发现没有单一的瓶颈,整个部署流程充满了挑战。我们认为,许多这些挑战是由现有的软件基础设施造成的,需要更多数据导向的方法来应对这些挑战。这一观察引出了本文的第二个贡献,即我们将数据导向架构(DOA)作为机器学习系统可能受益的有前途的软件架构范式加以考察。我们重点关注DOA在机器学习实际部署中的采用程度,尽管该范式本身相对不为人知,但其原则已广泛渗透到现代机器学习系统工程中。具体来说,我们将数据流架构确定为实现所有DOA原则的模式之一。
我们接下来评估了数据流架构在机器学习部署中的优势。评估分为两部分。在第一部分中,我们比较了在使用数据流和面向服务的方法实现的功能等效的应用代码库中部署机器学习模型的过程,后者作为基线。我们发现了数据流架构的一些优点,例如系统中更高的可发现性和更简单的数据收集。同时也识别了该范式的局限性。随后我们介绍了Seldon Core v2,这是我们根据数据流架构设计的开源模型推理平台。我们详细讨论了DOA原则如何在实践中实现,探讨了该平台的数据可观测性特性,并量化了其中涉及的性能权衡。
论文的最后一个贡献指出了数据流架构对软件开发的另一个好处:数据流软件与图形因果模型之间的紧密联系。我们发现数据流图和因果图之间的联系,并认为这种关系使得因果推理在数据流软件中的应用变得简单明了。我们以故障定位作为这一理念的具体例子,并在各种数据流系统和场景中展示它。
论文最后讨论了可以进一步发展社区对数据导向架构和数据流在机器学习系统中的理解和应用的研究方向。