近年来,深度生成模型由于其准确复制固有经验分布并产生新样本的能力而受到欢迎。特别地,提出了一些进展,其中模型根据指定的属性生成数据示例。然而,仍然存在一些挑战有待克服,即难以外推样本数据和对解缠表示的学习不足。另一方面,结构性因果模型(SCM)封装了支配生成过程的因果因素,并根据因果关系描述了一个生成模型,为解决深度生成模型中当前的障碍提供了关键的见解。本文对因果型深度生成模型(CGMs)进行了全面的综述,将SCM和深度生成模型相结合,以提高几个值得信任的属性,如鲁棒性、公平性和可解释性。本文概述了CGM的最新进展,根据生成类型对其进行分类,并讨论了如何将因果关系引入深度生成模型家族。本文还探索了该领域未来研究的潜在途径。
https://arxiv.org/abs/2301.12351
1. 引言
深度生成模型是一类用深度神经网络估计和表示训练样本概率分布的范式,涉及广泛的应用,如图像合成、属性操作、姿态估计以及语音和文本合成。最近的进展强制要求新生成的样本应满足一组属性条件[Wang et al.,2022;Kaddour et al.,2022],并有助于可控数据的生成,这在关键领域非常重要,即图像编辑[Liu et al.,2019]和医疗检测[Sanchez et al.,2022]。
尽管如此,由于从条件分布中采样的约束,仍然存在固有的局限性。我们希望生成的样本能够超越经验分布并编辑数据示例,同时考虑属性之间的关系[Kaddour等人,2022]。
与生成对抗网络(GANs)和变分自编码器(VAE)等深度生成模型不同,结构性因果模型(SCM)描述了一种源自因果关系的生成模型,封装了因果知识,并能够回答干预性和反事实问题[Pearl, 2009],从而提供了关键的见解,有可能消除当前深度生成模型中的显著限制。我们将在3.3节中介绍SCM。因果深度生成模型(CGMs)结合了深度生成模型和SCM,寻求解决现有生成模型的局限性,并增强多种可靠的属性。为此,开展了各种研究:基于GANs的模型[Kocaoglu等人,2018;Xu等人,2019;Zhang等人,2021;绍尔和盖格,2021年;冯等,2022;Shen等人,2022],基于vaes的模型[Suter等人,2019;Pawlowski等人,2020;Yang等人,2021;Sanchez-Mart´ın等人,2021;Hu和Li, 2021],以及基于扩散的模型[Sanchez和Tsaftaris, 2022;Sanchez等人,2022;Augustin等人,2022]。这些研究,如引用的工作中描述的研究,旨在促进表示学习中的因果可控生成和可解释解缠。
**本文对CGMs进行了首次全面的综述(据我们所知),重点是因果关系对深度生成模型家族的贡献。**文中围绕模型、可信属性、数据集和应用等方面,讨论了该领域面临的挑战和有希望的发展方向。我们的目标是为该领域的未来研究提供有价值的指导。
2. 因果关系在深度生成模型中很重要
为证明将因果关系纳入深度生成模型的好处,本文强调了当前深度生成模型的几个问题,并解释了为什么考虑因果关系对解决这些问题很重要。
**增强可控生成的外推能力。**深度生成模型能够复制复杂的数据分布,并根据指定的属性生成新的样本,例如合成一个事实为{Mustache = 1, Gender = M ale}的人脸图像。然而,由于依赖于观察分布的抽样,它们在训练分布之外进行外推的能力有限。相比之下,CGMs纳入了编码的因果知识,可能允许在训练分布的支持之外进行泛化[Besserve等人,2021],并在之前未观察到的上下文中产生数据示例,即{Mustache = 1, Gender = F male} [Kocaoglu等人,2018;冯等,2022]。这种增强的外推能力在医学检测和图像编辑等领域很有价值,在这些领域中,生成超出经验分布的样本的能力至关重要。
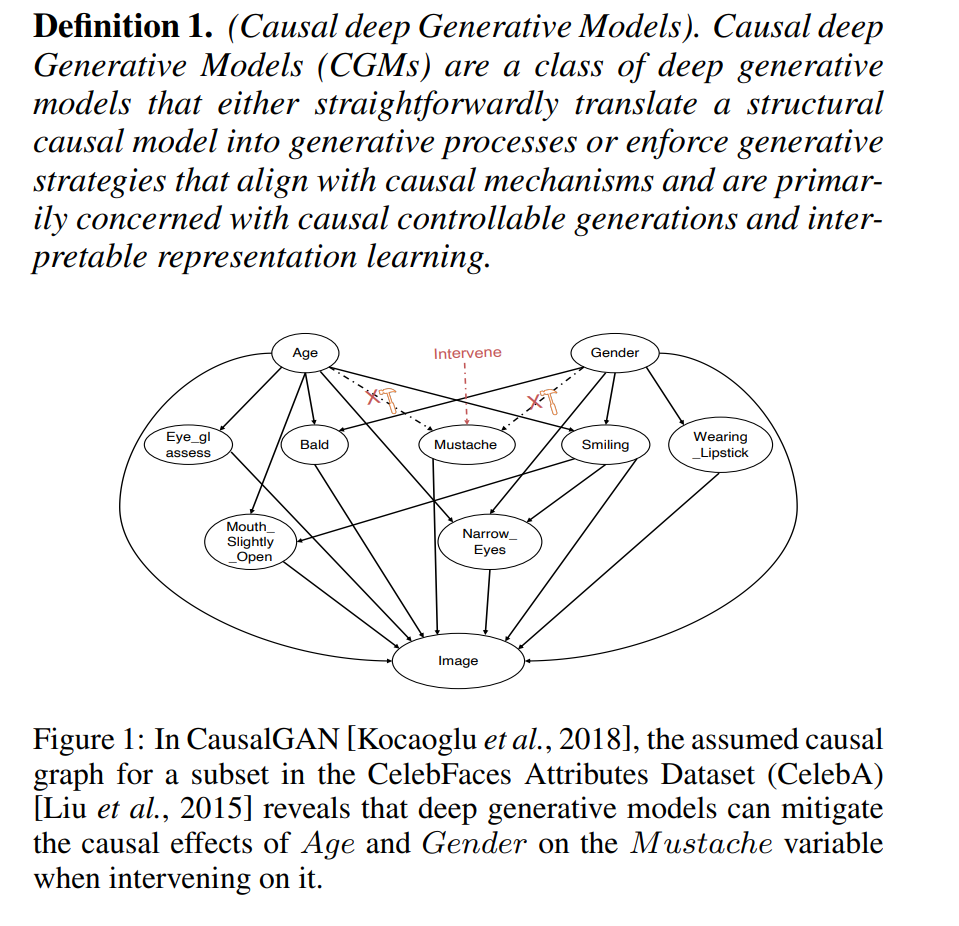
**通过表示学习中的因果解缠提高可解释性。**深度生成模型适用于学习有效的特征表示,分解潜在的变化因素[Bengio等人,2013],用于下游判别任务[Donahue等人,2016],即MNIST数据集中的数字类型、旋转和宽度的多个相互独立的因素[Higgins等人,2017]。然而,正如Hyvarinen和Pajunen, 1999;¨Hyvarinen et al., 2019],仅靠统计独立性通常不足以强制从其非线性混合的基础来源的可识别性。此外,最近的研究[Locatello等人,2019;Besserve等人,2020]还认为,在现有的解缠表示学习中加强潜在因素之间的独立性,不足以满足复杂的现实世界场景。相反,因果关系,特别是独立因果机制(ICM)原理,代表了一个更一般的概念,其中包含作为特殊情况的统计独立性[Scholkopf¨等人,2021]。特别是,因果解缠的过程,发现和建立潜变量之间的因果关系,对提供更实用和可解释的表示至关重要。例如,在面部图像中,微笑属性更可能导致嘴巴微微张开和N个箭头眼[Kocaoglu等人,2018;Shen et al., 2022],如图1所示。这种改进的可解释性在医疗检测等领域很有价值,在这些领域中,理解特征之间的关系至关重要。
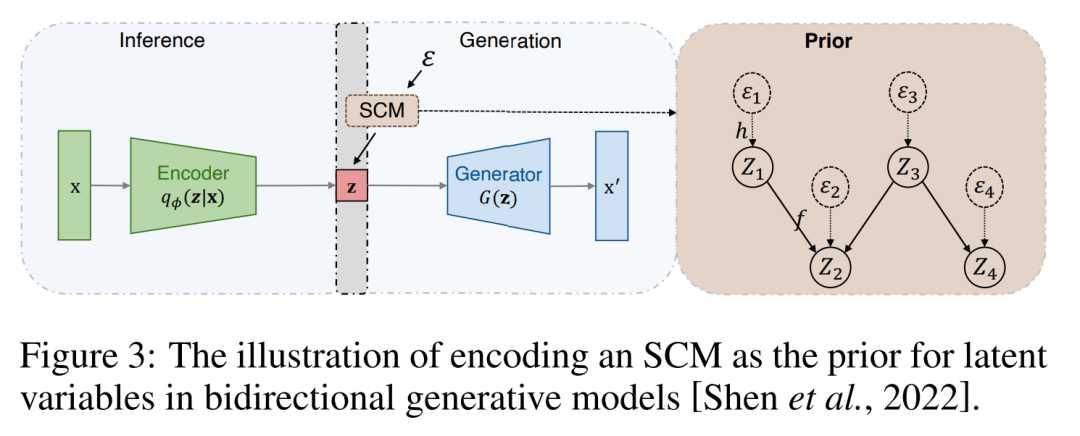
一致地管理多个属性。[Wang et al., 2022]强调,当前关于可控深度数据生成的研究存在局限性,即一次只能操作一个属性,而在真实场景中往往需要同时控制多个属性。另一方面,CGM通过整合因果学习,具有处理跨代不同属性的内在能力。这使得对SCM中的因果变量进行干预(见[Scholkopf和von Kugelgen,¨2022]中的定义4.9),允许生成具有多个属性的数据示例。例如,通过干预{秃头= 1,微笑= 1},可以生成同时显示秃头和微笑属性的面部图像[Shen等人,2022]。本文还提供了CGM的定义,以阐明这类模型的范围和重点。 * 、
**3. 方法 **
在本节中,我们提供当前CGM的全面概述。根据使用的生成方法对这些模型进行分类,包括对抗性训练、变分推理和扩散过程。本文的重点是如何将因果关系纳入深度生成模型家族。
基于GAN的方法
尽管GANs [Goodfellow等人,2014]在许多生成任务上取得了最先进的性能,并且一些研究设计了可控的数据生成[Wang等人,2022],即InfoGAN [Chen等人,2016],但第2节中的问题仍然存在。为了提高GAN生成数据的可控性和可解释性,一些研究通过将SCM转换为GAN架构或在GANs的生成策略中实施因果机制,将GANs与因果关系相结合。
基于VAE的方法
VAEs因其提供解纠缠的潜在表示的能力而被广泛应用[Kingma和Welling, 2014],并被认为是深度生成模型的最先进技术[Higgins等人,2017]。一些研究假设VAE中的潜变量是相互独立的。这个问题与非线性独立成分分析(ICA)密切相关,其中众所周知,在一般非线性情况下,生成过程是不可识别的。然而,这一领域的最新发展[Hyvarinen和Pajunen, 1999;Hyvarinen¨et al., 2019]已经证明,如果有多个分布的数据共享相同的生成函数,但具有不同的潜在独立潜变量分布,则生成函数变得可识别[Khemakhem等人,2020;Kong等,2022]。
基于扩散模型的方法
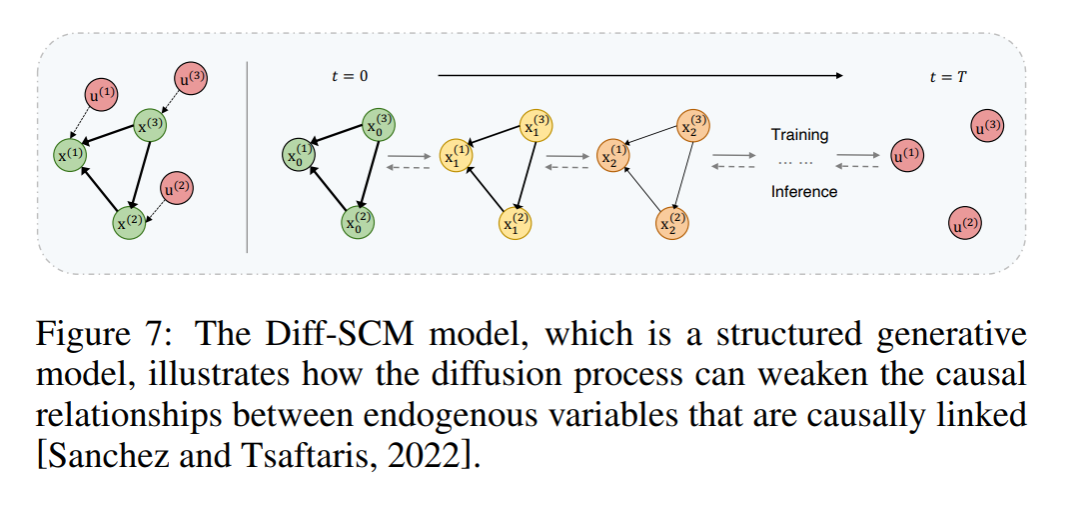
最近的研究表明,通过使用扩散概率模型,可以将生成扩散模型和scm结合起来进行反事实估计和解释[Dhariwal和Nichol, 2021]。这种方法已经在许多研究中进行了探索[Sanchez和Tsaftaris, 2022;Augustin等人,2022]。