

大型语言模型(LLMs)在解决多样的自然语言处理任务方面具有强大的能力。然而,LLM系统的安全性和安全问题已成为其广泛应用的主要障碍。许多研究广泛调查了LLM系统中的风险,并开发了相应的缓解策略。像OpenAI、谷歌、Meta和Anthropic这样的领先企业也在负责任的LLM上做了大量努力。因此,组织现有研究并为社区建立全面的分类体系的需求日益增长。在本文中,我们深入研究了LLM系统的四个基本模块,包括用于接收提示(prompt)的输入模块、在广泛语料库上训练的语言模型、用于开发和部署的工具链模块,以及用于输出LLM生成内容的输出模块。基于此,我们提出了一个全面的分类体系,系统地分析了与LLM系统每个模块相关的潜在风险,并讨论了相应的缓解策略。此外,我们回顾了流行的基准,旨在促进LLM系统风险评估。我们希望本文能帮助LLM参与者以系统的视角构建他们负责任的LLM系统。
https://www.zhuanzhi.ai/paper/327b8030016bf5ebb68cfd832fc22a16

大型语言模型(LLMs)[1]-[5],拥有大量在广泛语料库上预训练的模型参数,已在自然语言处理(NLP)领域引发了一场革命。模型参数的规模扩大和预训练语料库的扩展,赋予了LLMs在各种任务上的显著能力,包括文本生成[2]、[4]、[5],编码[2]、[6],以及知识推理[7]-[10]。此外,提出了对齐技术(例如,监督微调和基于人类反馈的强化学习[4]、[11]),以鼓励LLMs与人类偏好保持一致,从而提高LLMs的可用性。在实践中,像ChatGPT [12]这样的先进LLM系统已经在全球范围内获得了用户群,成为复杂NLP任务的竞争性解决方案。
尽管LLM系统取得了巨大的成功,但它们有时可能违反人类的价值观和偏好,从而引发了对基于LLM应用的安全性和安全问题的担忧。例如,由于Redis客户端开源库的漏洞,ChatGPT泄露了用户的聊天历史[13]。此外,精心设计的对抗性提示(prompt)可能会引发LLMs产生有害的回应[14]。即使没有对抗性攻击,当前的LLMs仍可能生成不真实的、有害的、有偏见的,甚至是非法的内容[15]-[19]。这些不良内容可能被滥用,导致不利的社会影响。因此,大量研究工作致力于缓解这些问题[15]-[18]。像OpenAI、谷歌、Meta和Anthropic这样的领先机构也在负责任的LLMs上做了大量努力,优先发展有益的人工智能[20]-[23]。
为了减轻LLMs的风险,迫切需要开发一种全面的分类体系,列举构建和部署LLM系统时固有的所有潜在风险。这种分类体系旨在作为评估和提高LLM系统可靠性的指导。目前,大多数现有努力[15]-[18]基于对输出内容的评估和分析,提出了自己的风险分类。一般来说,一个LLM系统由各种关键模块组成——一个用于接收提示(prompt)的输入模块,一个在大量数据集上训练的语言模型,一个用于开发和部署的工具链模块,以及一个用于输出LLM生成内容的输出模块。据我们所知,目前提出的针对LLM系统各个模块的风险分类较少。因此,本工作旨在弥补这一差距,鼓励LLM参与者:1)理解与LLM系统每个模块相关的安全性和安全问题;2)采用系统的视角构建更负责任的LLM系统。
为了实现这一目标,我们提出了一种面向模块的分类体系,对LLM系统每个模块的风险及其缓解策略进行分类。对于特定的风险,面向模块的分类体系可以帮助快速定位需要关注的模块,从而帮助工程师和开发者确定有效的缓解策略。如图1所示,我们提供了LLM系统内部隐私泄露的一个例子。使用我们的面向模块的分类体系,我们可以将隐私泄露问题归因于输入模块、语言模型模块和工具链模块。 因此,开发人员可以通过对抗提示(adversarial prompts)、实施隐私训练和纠正工具中的漏洞来减轻隐私泄露的风险。除了总结LLM系统的潜在风险及其缓解方法外,本文还回顾了广泛采用的风险评估基准,并讨论了流行LLM系统的安全性和安全问题。
总结本文的主要贡献如下:
我们对LLM系统的每个模块相关的风险和缓解方法进行了全面的综述(survey),并回顾了评估LLM系统安全性和安全性的基准。
我们提出了一个面向模块的分类体系,将潜在风险归因于LLM系统的特定模块。这种分类体系帮助开发者更深入地理解可能风险的根本原因,从而促进有益LLM系统的开发。
我们的分类体系从更系统的角度覆盖了比以往分类更广泛的LLM风险范围。值得注意的是,我们考虑了与工具链密切相关的安全问题,这在以前的综述中很少讨论。
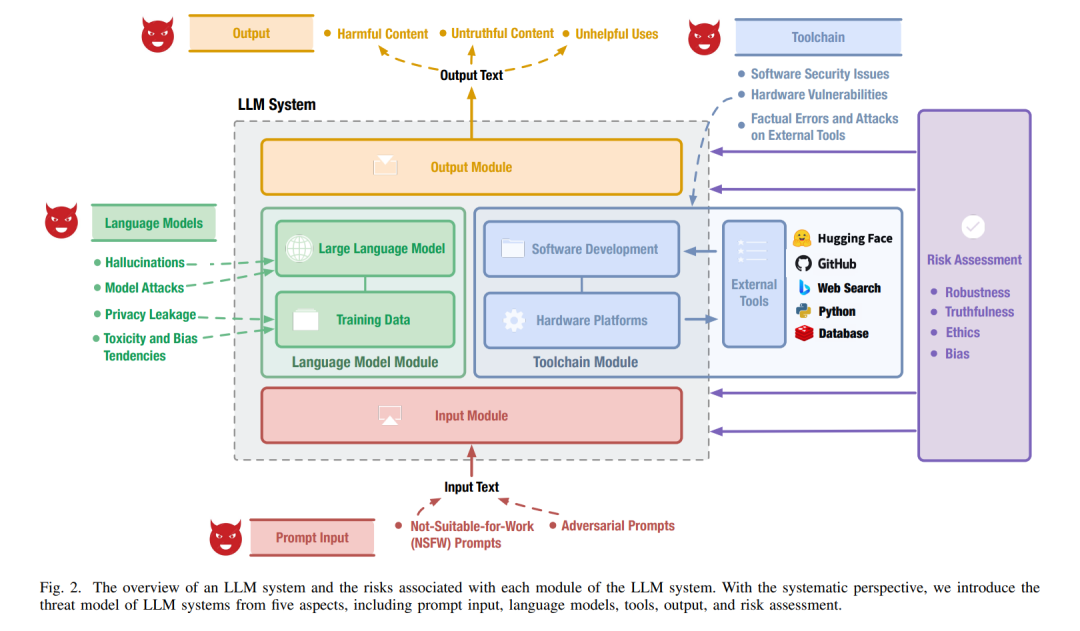
LLM模块。一个LLM系统涉及一系列数据、算法和工具,可以划分为LLM系统的不同模块。在这篇综述中,我们讨论了最主要的模块,包括用于接收提示的输入模块、在大量数据集上训练的语言模型、用于开发和部署的工具链模块,以及用于输出LLM生成内容的输出模块。
图2展示了上述模块之间的关系。
输入模块。输入模块实现了输入保护功能,用于接收和预处理输入提示。具体来说,这个模块通常包含一个等待用户输入请求的接收器和基于算法的策略来过滤或限制请求。
语言模型模块。语言模型是整个LLM系统的基础。本质上,这个模块涉及到大量的训练数据和使用这些数据训练的最新语言模型。
工具链模块。工具链模块包含了LLM系统开发和部署所使用的实用工具。具体来说,这个模块涉及到软件开发工具、硬件平台和外部工具。
输出模块。输出模块返回LLM系统的最终响应。通常,该模块配备了输出保护功能,以修正LLM生成的内容,使其符合伦理正当性和合理性。
随着LLM(大型语言模型)的日益普及,与LLM系统相关的风险也越来越受到关注。在本节中,我们将这些风险按照LLM系统的不同模块进行分类。图3展示了我们在这篇综述中调查的风险概览。

在这项工作中,我们对LLM系统的安全性和安全问题进行了广泛的综述,旨在激励LLM参与者在构建负责任的LLM系统时采用系统性的视角。为了促进这一点,我们提出了一个面向模块的风险分类体系,用于组织LLM系统每个模块相关的安全性和安全风险。通过这个分类体系,LLM参与者可以快速识别与特定问题相关的模块,并选择合适的缓解策略来减轻问题。我们希望这项工作能够服务于学术界和工业界,为负责任的LLM系统的未来发展提供指导。
