大型语言模型(LLMs)自从2022年11月ChatGPT发布以来,因其在广泛的自然语言任务上的强大表现而受到了大量关注。LLMs通过在海量文本数据上训练数十亿模型参数获得了通用语言理解和生成的能力,正如扩展定律[1]、[2]所预测的。尽管LLMs的研究领域非常新近,但它正在多个不同的方向上迅速发展。在本文中,我们回顾了一些最突出的LLMs,包括三个受欢迎的LLM家族(GPT, LLaMA, PaLM),并讨论了它们的特点、贡献和限制。我们还概述了构建和增强LLMs的技术。接着,我们调研了为LLM训练、微调和评估准备的流行数据集,回顾了广泛使用的LLM评估指标,并比较了几种受欢迎的LLMs在一组代表性基准测试上的性能。最后,我们通过讨论开放性挑战和未来研究方向来结束本文。
https://www.zhuanzhi.ai/paper/6211cbd80a246ae8e282d1b2ebf0ab23
1. 引言
大型语言模型(LLMs)自ChatGPT于2022年11月发布以来,因其在广泛的自然语言任务上的强大表现而吸引了大量关注。LLMs通过在大量文本数据上训练数十亿参数来获得通用语言理解和生成能力,这与扩展定律的预测相符。虽然LLMs的研究领域非常新,但它在许多不同方面迅速发展。在本文中,我们回顾了一些最突出的LLMs,包括三个受欢迎的LLM家族(GPT, LLaMA, PaLM),并讨论了它们的特点、贡献和限制。我们还概述了用于构建和增强LLMs的技术。然后,我们调查了为LLM训练、微调和评估准备的流行数据集,回顾了广泛使用的LLM评估指标,并比较了几种受欢迎的LLMs在一组代表性基准测试上的性能。最后,我们通过讨论开放性挑战和未来研究方向来结束本文。
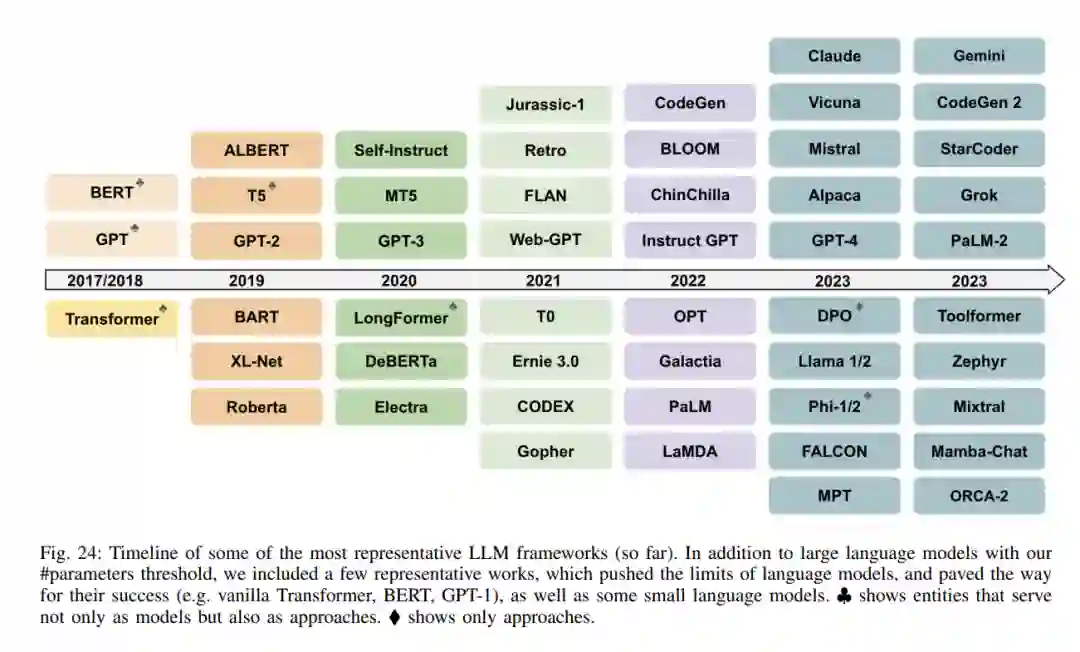
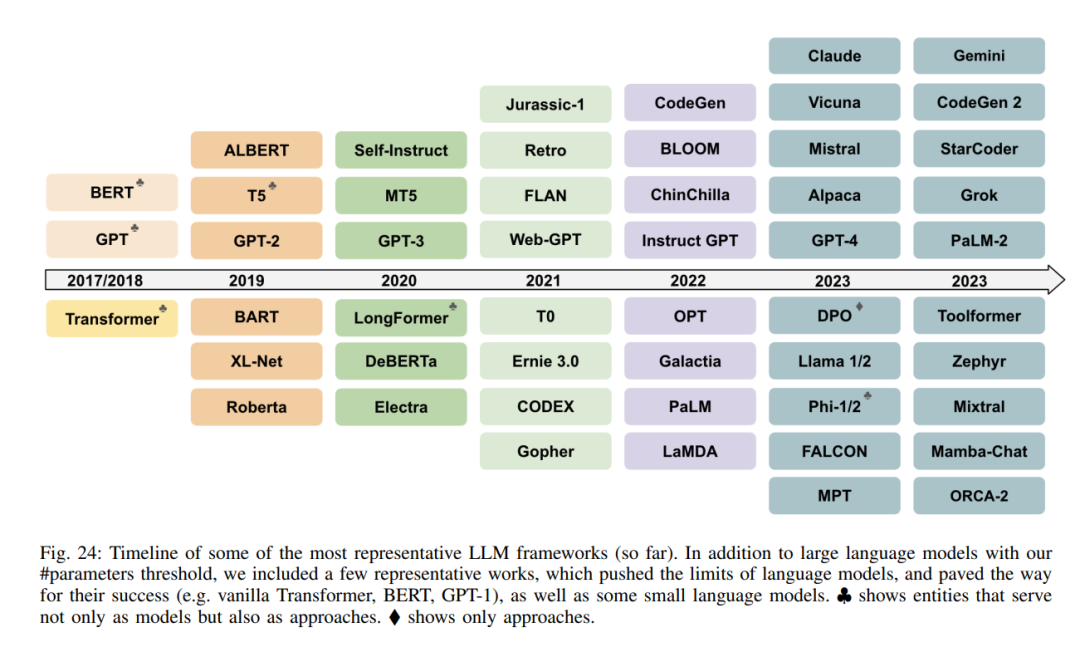
LLMs是基于神经网络的大规模预训练统计语言模型。LLMs的成功是数十年语言模型研究和开发积累的结果,可以分为四个波浪,这些波浪有不同的起点和速度:统计语言模型、神经语言模型、预训练语言模型和LLMs。
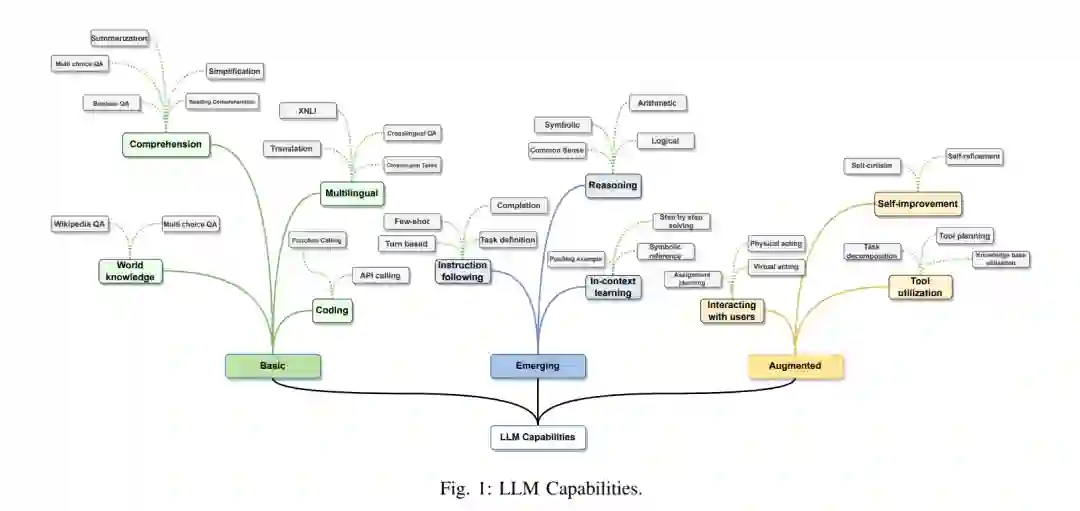
统计语言模型(SLMs)将文本视为单词序列,并估计文本的概率为其单词概率的乘积。SLMs的主要形式是马尔可夫链模型,即n-gram模型,它计算一个词的概率,条件是其前n-1个词。由于单词概率是根据从文本语料库收集的单词和n-gram计数估计的,模型需要通过使用平滑处理数据稀疏性(即,为未见单词或n-gram分配零概率)。 早期的神经语言模型(NLMs)通过将单词映射到低维连续向量(嵌入向量)并使用神经网络基于其前序单词的嵌入向量聚合来预测下一个单词,来处理数据稀疏性。NLMs学习的嵌入向量定义了一个隐藏空间,其中向量之间的语义相似性可以通过它们的距离轻松计算。 预训练语言模型(PLMs)与早期NLMs不同,它们是任务不可知的。PLMs的训练和推理遵循预训练和微调范式,其中基于循环神经网络或变换器的语言模型在Web规模的未标记文本语料库上进行预训练,然后使用少量(标记的)特定任务数据进行微调。 大型语言模型(LLMs)主要指基于变换器的神经语言模型,包含数十亿到数千亿参数,预训练于大量文本数据。与PLMs相比,LLMs不仅在模型大小上要大得多,而且在语言理解和生成能力上也更强,更重要的是,它们展示了在小规模语言模型中不存在的新兴能力。这些新兴能力包括在推理时从提示中给出的少量示例学习新任务的上下文内学习、在不使用明确示例的情况下遵循新类型任务指令的指令跟随,以及通过将复杂任务分解为中间推理步骤来解决复杂任务的多步骤推理。 通过高级使用和增强技术,LLMs可以部署为所谓的AI代理:感知环境、做出决策并采取行动的人工实体。以前的研究集中在为特定任务和领域开发代理。LLMs展示的新兴能力使基于LLMs构建通用AI代理成为可能。尽管LLMs被训练以在静态设置中产生响应,但AI代理需要采取行动与动态环境互动。因此,基于LLM的代理通常需要增强LLMs,例如,从外部知识库获取更新的信息,验证系统操作是否产生预期结果,以及应对事情不如预期进行时的情况等。我们将在第四节详细讨论基于LLM的代理。 本文的其余部分,第二节介绍LLMs的最新进展,重点是三个LLM家族(GPT,LLaMA和PaLM)及其他代表性模型。第三节讨论了如何构建LLMs。第四节讨论了如何使用LLMs,并为现实世界的应用增强LLMs。第五节和第六节回顾了评估LLMs的流行数据集和基准,总结了报告的LLM评估结果。最后,第七节通过总结挑战和未来研究方向来结束本文。
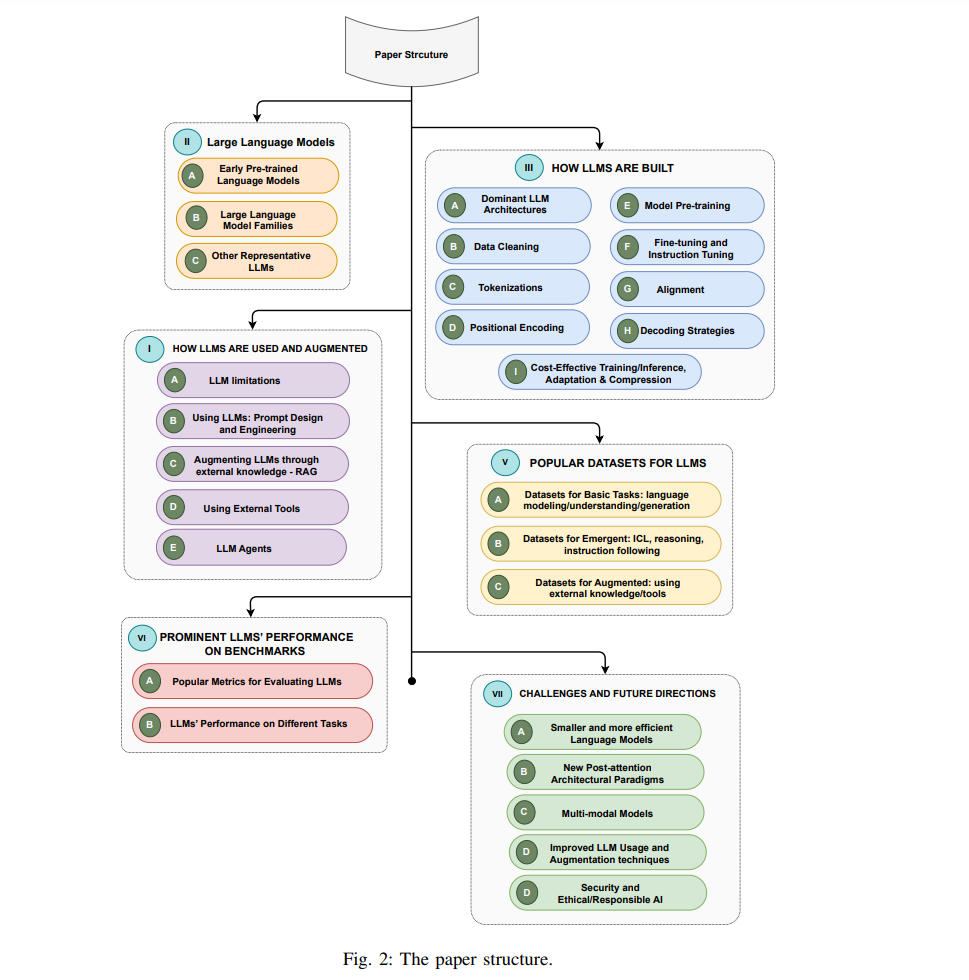
II. 大型语言模型在这一部分,我们首先回顾早期的预训练神经语言模型,因为它们是LLMs的基础,然后我们将讨论三个LLMs家族:GPT、LlaMA和PaLM。表I提供了这些模型及其特性的概览。
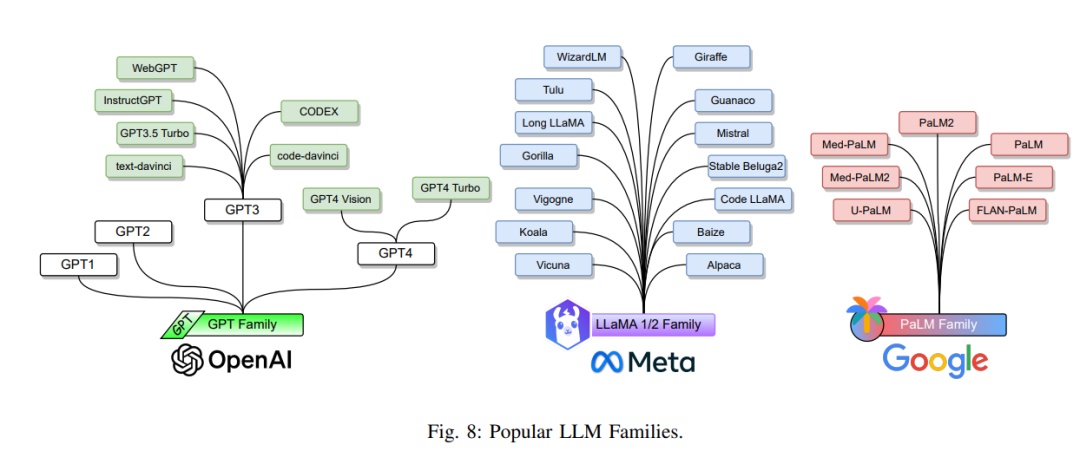
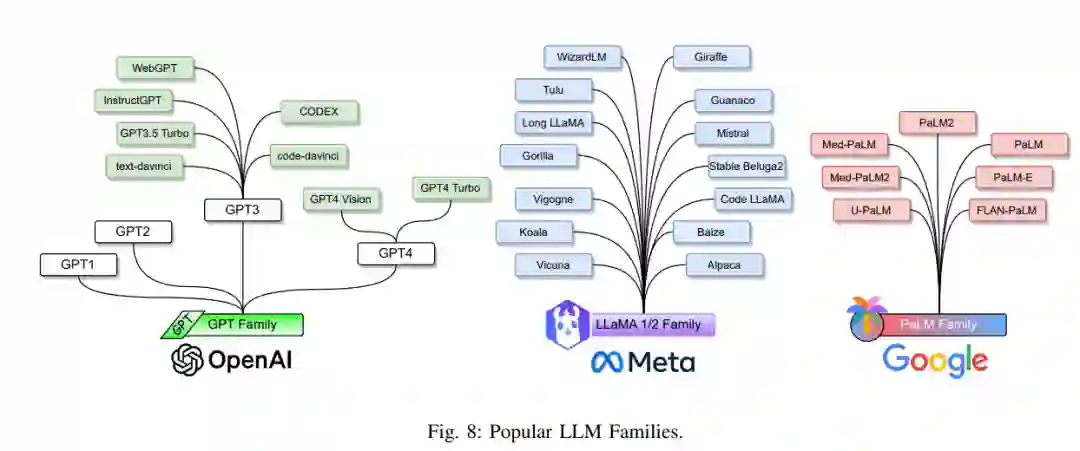
大型语言模型(LLMs)主要指基于变换器的预训练语言模型(PLMs),包含数十亿到数百亿的参数。与上述的PLMs相比,LLMs不仅在模型大小上要大得多,而且还展示了更强的语言理解和生成能力以及在小规模模型中不存在的新兴能力。下面,我们将回顾三个LLM家族:GPT、LLaMA和PaLM,如图8所示。
如何构建LLMs?
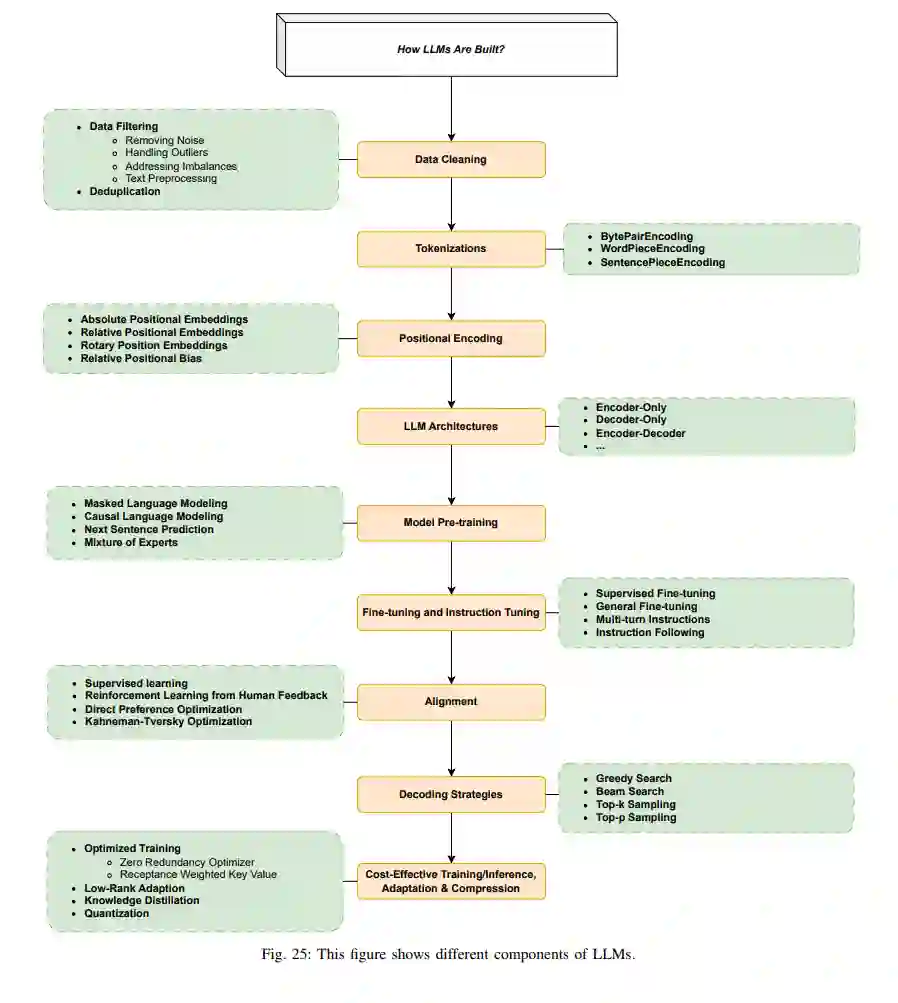
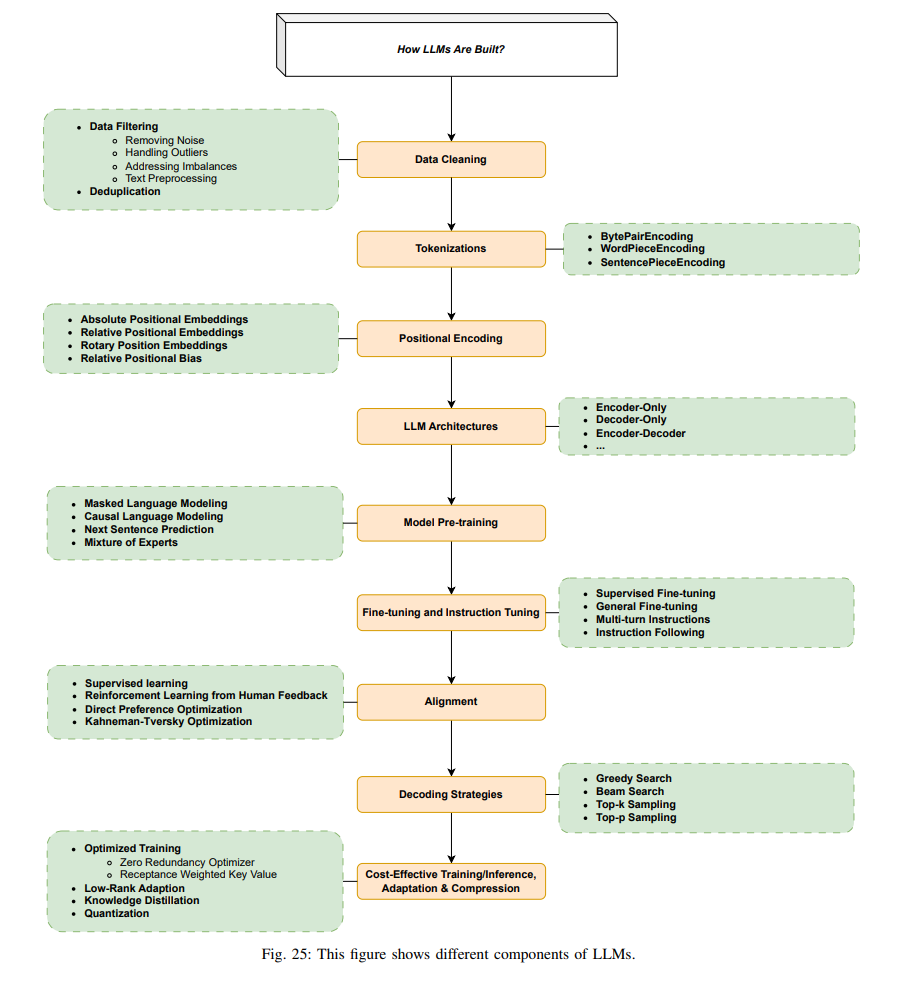
在本节中,我们首先回顾用于LLMs的流行架构,然后讨论从数据准备、标记化,到预训练、指令调整和对齐等一系列数据和建模技术。 一旦选择了模型架构,训练LLM涉及的主要步骤包括:数据准备(收集、清洗、去重等)、标记化、模型预训练(以自监督学习的方式)、指令调整和对齐。我们将在下面的各个小节中解释每一个步骤。这些步骤也在图25中示意。
如何使用和增强LLMs?
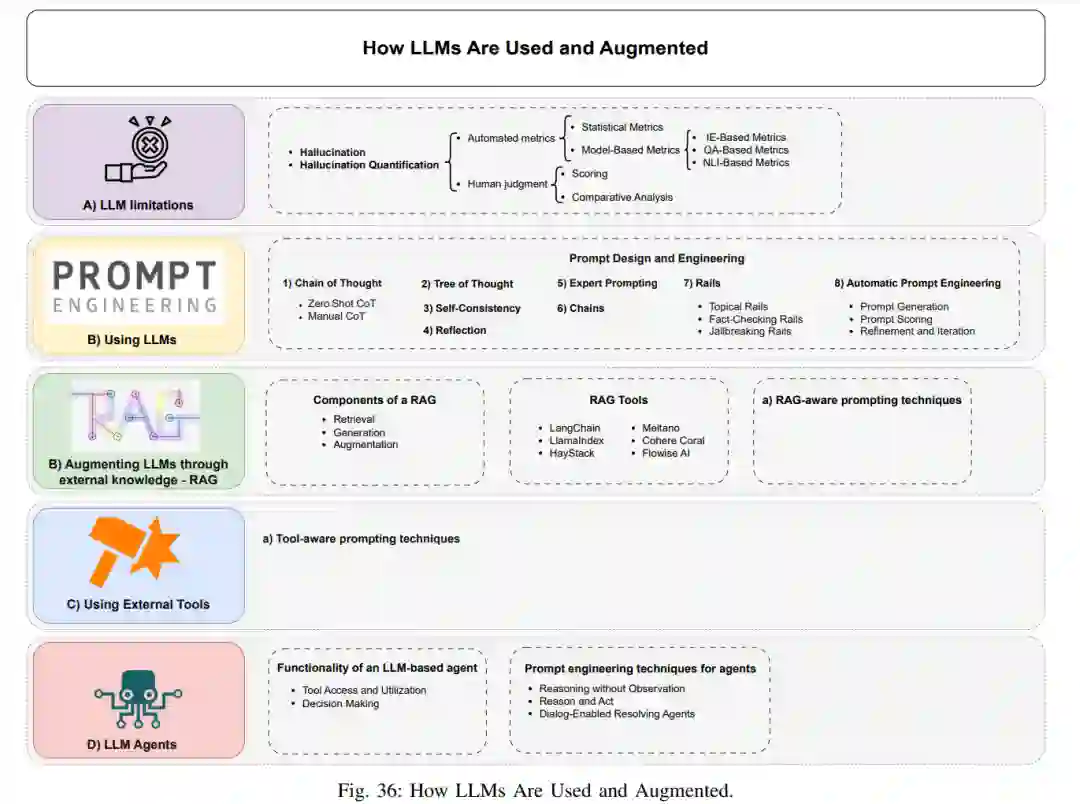
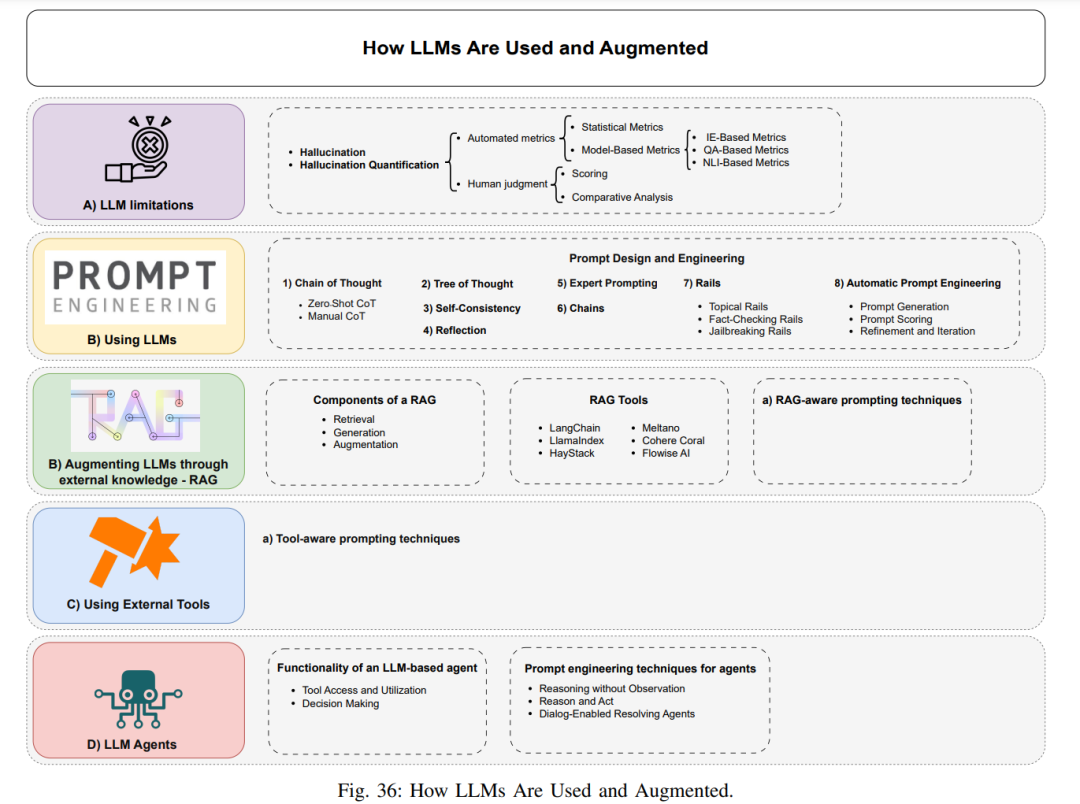
一旦LLMs被训练好,我们就可以使用它们为各种任务生成所需的输出。LLMs可以通过基本的提示直接使用。然而,为了充分发挥它们的潜力或解决某些缺陷,我们需要通过一些外部手段来增强模型。在本节中,我们首先简要概述LLMs的主要缺点,更深入地探讨了幻觉问题。然后,我们描述了如何通过提示和一些增强方法不仅解决这些限制,还可以增强LLMs的能力,甚至将LLM转变为具有与外部世界交互能力的全功能AI代理。
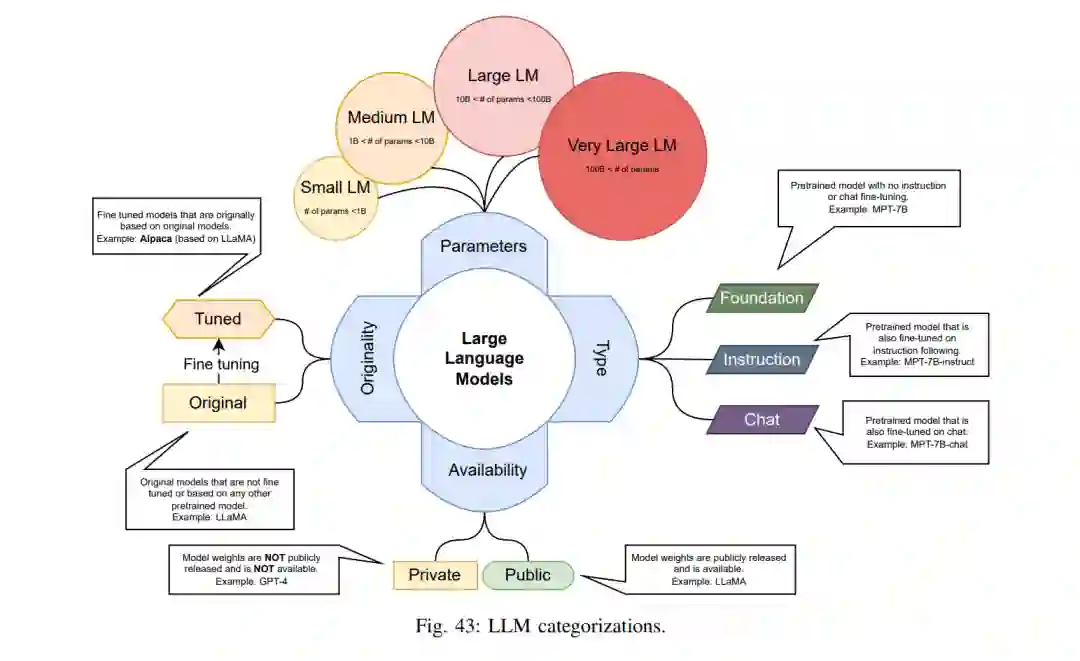
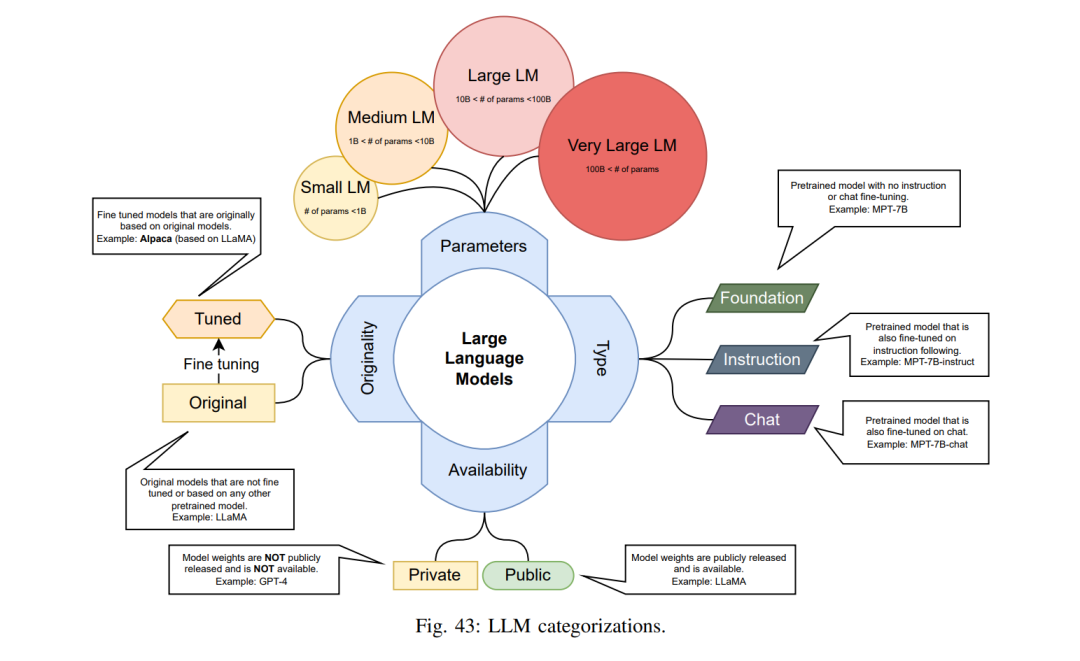
评估不同的LLMs也可以从不同的角度进行。例如,参数数量大幅减少的LLM与参数数量更多的LLM并不完全可比。从这个角度出发,我们也将LLMs分为四类:小型(等于或少于10亿参数)、中型(在10亿到100亿之间)、大型(在100亿到1000亿之间)和超大型(超过1000亿)。我们使用的另一种LLM分类是它们的主要用途。我们认为每个LLM要么是:基础模型(预训练的语言模型,没有指令微调和聊天微调)、指令模型(只有指令微调的预训练语言模型)、聊天模型(有指令和聊天微调的预训练语言模型)。除了所有描述的分类之外,还需要另一个分类来区分原始模型和调整过的模型。原始模型是那些作为基础模型或微调模型发布的。调整过的模型是那些抓住原始模型并用不同的数据集或甚至不同的训练方法进行调整的模型。同样值得注意的是,原始模型通常是基础模型,已经在特定数据集上进行了微调,甚至是不同的方法。模型权重的可用性,不论许可如何,是我们分类中的另一个类别。权重公开可用(即使通过请求)的模型被标记为公共模型,而其他的则被标记为私有模型。表III展示了本文余下部分使用的所有这些定义和缩写。图43直观地说明了这些。
结论
本文对过去几年发展的LLMs进行了综述。我们首先提供了早期预训练语言模型(例如,BERT)的概览,然后回顾了三个受欢迎的LLM家族(GPT、LLaMA、PaLM)和其他代表性LLMs。接着,我们调研了构建、增强和使用LLMs的方法和技术。我们回顾了流行的LLM数据集和基准,并比较了一组杰出模型在公共基准上的性能。最后,我们提出了开放性挑战和未来研究方向。