
最近,数据挖掘顶会 ACM CKIM 2021 上,CWRU图神经网络过度处方获最佳论文!伍斯特理工学院-深度迁移抑郁筛查获最佳应用论文
第30届ACM信息与知识管理国际会议(CIKM 2021)于11月1日至5日在线举行。本次会议共收到1251篇长文(Full Paper)和626篇短文(Short Paper)投稿,其中271篇长文和177篇短文被大会接收,录取率分别为21.7%和28.3%。接收论文列表见https://www.cikm2021.org/accepted-papers。

https://www.cikm2021.org/programme/best-paper-nominations
最佳长论文
图神经网络过量处方检测

RxNet: Rx-refill Graph Neural Network for Overprescribing Detection ‐ Jianfei Zhang (Case Western Reserve University & University of Alberta, USA), Ai-Te Kuo (Auburn University, USA), Jianan Zhao (Case Western Reserve University, USA), Qianlong Wen (Case Western Reserve University, USA), Erin Winstanley (West Virginia University, USA), Chuxu Zhang (Brandeis University, USA), Yanfang Ye (Case Western Reserve University & University of Notre Dame, USA)
处方药很容易过量,导致药物滥用或阿片类药物过量。因此,为了减少“过度处方”,美国政府制定了处方药监控计划(PDMP)。然而,PDMP在检测患者潜在的过量用药行为方面能力有限,影响了其预防药物滥用和过量用药的效果。尽管已经提出了一些基于机器学习的方法来检测过度开药,但它们通常忽略了患者的开药行为,其性能也不令人满意。鉴于此,我们提出了一种新的模型RxNet用于PDMP中的过量处方检测。RxNet建立了一个动态的异构图来对Rx-refills模型进行建模,该模型本质上是各种Rx条目(如患者)之间的处方和配药(P&D)关系,这些条目的表示是通过图神经网络编码的。此外,为了探索患者的动态Rx-refill 行为和医疗状况变化,设计了一个RxLSTM网络来更新患者的表示。在RxLSTM输出的基础上,利用一个剂量自适应网络来提取和重新校准剂量模式,并获得精炼的患者表示,最终用于过量处方检测。俄亥俄州1年PDMP数据的广泛实验结果表明,RxNet在预测阿片类药物过量和药物滥用高危患者方面始终优于最新的方法,F1评分平均分别提高5.7%和7.3%。
https://dl.acm.org/doi/10.1145/3459637.3482465
最佳应用论文
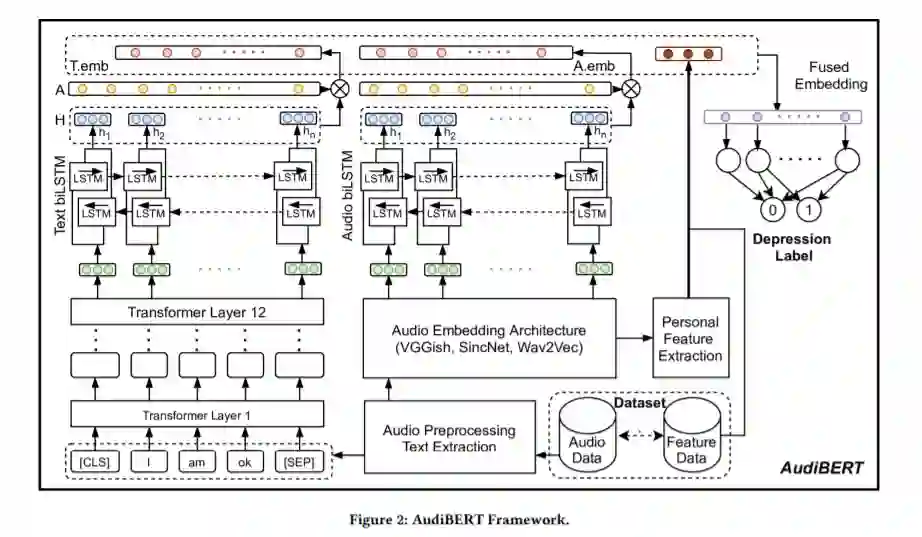
深度迁移学习多模态分类框架的抑郁症筛查
AudiBERT: A Deep Transfer Learning Multimodal Classification Framework for Depression Screening ‐ Ermal Toto (Worcester Polytechnic Institute, USA), ML Tlachac (Worcester Polytechnic Institute, USA), Elke A. Rundensteiner (Worcester Polytechnic Institute, USA)
抑郁症是导致残疾的主要原因,造成巨大的社会经济损失。尽管早期发现对改善预后至关重要,但这种精神疾病在很大程度上仍未得到诊断。通过将这种筛选功能无处不在地整合到虚拟助手和智能手机技术中,从声音分类抑郁症有望带来革命性的诊断。不幸的是,由于隐私问题,带有抑郁标签的音频数据集参与者很少,导致当前的分类模型性能低下。为了应对这一挑战,我们引入了音频辅助BERT (AudiBERT),这是一种利用人类声音的多模态特性的新型深度学习框架。为了缓解小数据问题,AudiBERT将通过双重自注意机制增强的各自模式的预训练的音频和文本表示模型集成到深度学习体系结构中。应用于抑郁症分类的AudiBERT始终实现了令人满意的性能,与15个主题问题数据集的最先进的音频和文本模型相比,F1分数增加了6%至30%。使用针对医疗和一般健康问题的答案,我们的框架分别获得高达0.92和0.86的F1分数,证明了使用语音技术从非正式对话中筛选抑郁症的可行性。
https://dl.acm.org/doi/10.1145/3459637.3481895
最佳短论文
Neuron Campaign for Initialization Guided by Information Bottleneck Theory ‐ Haitao Mao (University of Electronic Science and Technology of China, China), Xu Chen (Peking University, China), Qiang Fu (Microsoft Research Asia, China), Lun Du (Microsoft Research Asia, China), Shi Han (Microsoft Research Asia, China), Dongmei Zhang (Microsoft Research Asia, China)
近年,随着深度学习相关研究的深入,如何训练好神经网络日益成为学术焦点。在神经网络的初始化策略研究中,最著名的方法有Xavier Initialization,He Initialization,这些方法更多的关注了解决梯度消失和梯度爆炸的训练问题,而没有考虑如何寻找更好的初始化策略来提高神经网络的泛化能力。
为此,该论文基于“信息瓶颈理论”(Information Bottleneck Theory)提出了一套在理解初始化网络泛化性能的新角度。基于这种新视角,作者提出,满足特定互信息指标条件的初始化网络,能具有好的泛化性能,并对互信息指标进行了一系列的简化,以降低实际计算复杂度。在确定指标基础上,作者提出了一套神经元竞争方法,以组合优化的方式选择出合适的神经网络初始化。
最佳资源论文
PyTorch Geometric Temporal: Spatiotemporal Signal Processing with Neural Machine Learning Models ‐ Benedek Rozemberczki (AstraZeneca, United Kingdom), Paul Scherer (University of Cambridge, United Kingdom), Yixuan He (University of Oxford, United Kingdom), George Panagopoulos (École Polytechnique, France), Alexander Riedel (Ernst-Abbe University for Applied Sciences, Germany), Maria Astefanoaei (IT University of Copenhagen Denmark, Denmark), Oliver Kiss (Central European University, Hungary), Ferenc Beres (ELKH SZTAKI, Hungary), Guzmán López (Tryolabs, Uruguay), Nicolas Collignon (Pedal Me, United Kingdom), Rik Sarkar (University of Edinburgh, United Kingdom)
我们提出了PyTorch Geometric Temporal,一个结合了最先进的机器学习算法的深度学习框架,用于神经时空信号处理。该库的主要目标是在一个统一的易于使用的框架中为研究人员和机器学习从业者提供时间几何深度学习。PyTorch Geometric Temporal是基于PyTorch生态系统中的现有库、流线神经网络层定义、用于批处理的时态快照生成器和集成的基准数据集创建的。这些特性通过类似于教程的案例研究进行了说明。实验表明,该图书馆中实现的模型对诸如流行病学预测、叫车需求预测和网络流量管理等现实问题的预测性能良好。我们对运行时的敏感性分析表明,该框架可以在具有丰富时间特征和空间结构的web规模的数据集上运行。
最佳Demo论文
DORA THE EXPLORER: Exploring Very Large Data With Interactive Deep Reinforcement Learning ‐ Aurélien Personnaz (CNRS, Univ. Grenoble Alpes, France), Sihem Amer-Yahia (CNRS, Univ. Grenoble Alpes, France), Laure Berti-Equille (IRD, ESPACE-DEV, France), Maximilian Fabricius (Max Planck Institute for Extraterrestrial Physics, Germany), Srividya Subramanian (Max Planck Institute for Extraterrestrial Physics, Germany)



