在本论文中,我们研究了机器学习算法的在分布内泛化,着重于建立泛化误差的严格上界。我们脱离传统的基于复杂性的方法,通过引入和分析信息论上界来量化学习算法与训练数据之间的依赖性。我们考虑了两类泛化保证:
- 期望中的保证。这些界限衡量平均情况下的性能。在这里,算法与数据之间的依赖性通常通过互信息或基于f-散度的其他信息度量来捕捉。虽然这些度量提供了直观的解释,但它们可能忽略了算法假设类的几何特性。为了解决这一限制,我们引入了使用Wasserstein距离的界限,该距离在数学上更为复杂,但考虑到了几何因素。此外,我们提出了一种结构化、系统化的方法来推导捕捉算法与单个数据点之间以及算法与训练数据子集之间的依赖性的界限,条件是已知其他数据。这些类型的界限提供了更深入的洞察,我们通过将其应用于推导随机梯度Langevin动力学算法的泛化误差界限来证明这一点。
- PAC-Bayesian保证。这些界限衡量高概率下的性能水平。在这里,算法与数据之间的依赖性通常通过相对熵来衡量。我们建立了Seeger–Langford界限和Catoni界限之间的联系,揭示了前者通过Gibbs后验进行优化。此外,我们为各种类型的损失函数引入了新的、更紧的界限,包括那些具有有界范围、累积生成函数、矩或方差的损失函数。为此,我们引入了一种新的技术来优化概率陈述中的参数。我们还研究了这些方法的局限性。我们提出了一个反例,其中大多数现有的(基于相对熵的)信息论界限失败,而传统方法则不会。最后,我们探讨了隐私与泛化之间的关系。我们表明,具有有界最大泄露的算法可以泛化。此外,对于离散数据,我们为差分隐私算法导出了新的界限,这些界限随着样本数量的增加而消失,从而保证了它们即使在隐私参数保持不变的情况下也能泛化。这与文献中要求隐私参数随样本数量减少以确保泛化的先前界限形成对比。
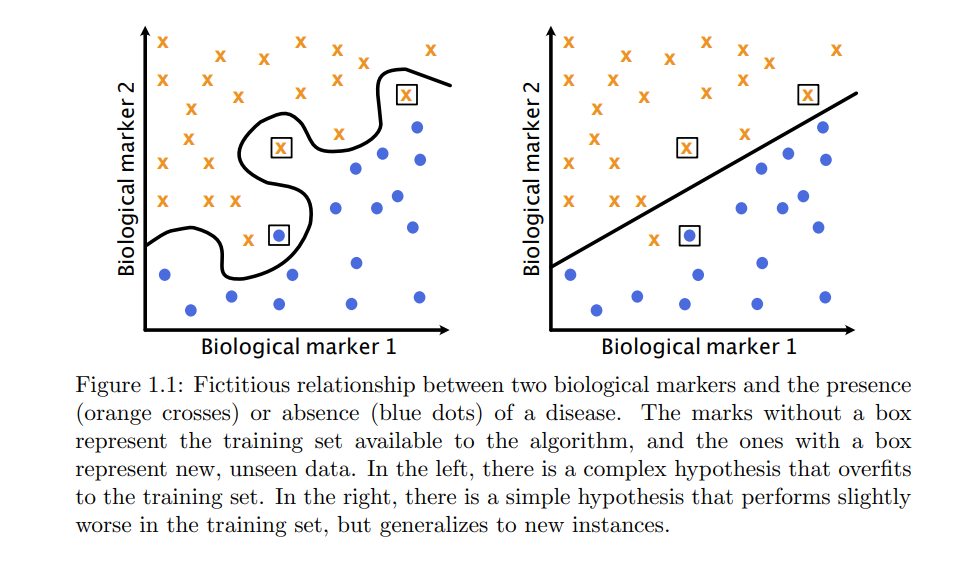
当前,机器学习在默默地塑造着我们周围的世界:从我们在社交媒体上看到的定制内容,到医疗、金融或自动驾驶等高风险行业【16-19】。机器学习算法被用来分析数据,用于早期疾病检测、防止欺诈或控制自动驾驶汽车的转向、制动和加速。因此,对于何时以及为什么这些算法在关键情况下能够适当地表现,拥有一个坚实的理论理解是至关重要的。 机器学习算法(或简称为学习算法)是一种机制,它观察问题实例的序列(通常被称为训练集)并返回针对该问题的假设。例如,给定一个包含两个生物标记和一个标签(标明一个人是否患有某种疾病)的医疗记录训练集,学习算法会返回一个模型,该模型从医疗记录中预测该疾病的存在。在这种情况下,假设是医疗记录与疾病存在之间的映射,这种映射由预测模型表征,如图1.1所示。算法返回的假设在训练集上可能表现得非常好。然而,这并不一定意味着它在新的、未见过的数据上也会表现良好。例如,考虑图1.1中的复杂假设,尽管它可以完美地解释医疗标记与疾病存在之间的关系,对于训练数据中的所有实例都是如此,但当它用来描述同一分布下的未见数据时就会失败。泛化理论领域专注于寻找数学保证,保证学习算法返回的假设在新的、未见过的数据上的性能。我们通常通过损失函数来描述算法的性能。在上述例子中,如果算法正确判断出一个人从其医疗记录中是否患病,则损失函数返回0,否则返回1。因此,损失函数的较小值意味着更好的性能。上述的泛化保证通常是对问题分布样本上损失函数期望值的上界形式,也称为人群风险。或者,保证以泛化误差的上界形式出现,泛化误差定义为人群风险与训练集实例上平均损失函数之差,或称为经验风险。在研究学习算法的泛化时,我们可能会考虑新数据来自相同分布(在分布内泛化)或接近但不同的分布(在分布外泛化)。例如,同一医院按照相同协议收集的同一人群统计的医疗记录可以被认为是来自同一分布。然而,来自不同人群统计的医疗记录通常被认为是来自不同的分布。例如,居住在高海拔城市的人的血氧水平低于居住在海平面的人。这种分布的变化通常被称为分布偏移。在本论文中,以及接下来的文本中,我们将仅关注在分布内泛化。泛化保证有两种主要类型: * 期望中的保证。这些保证是两者中较不具体的。它们确保算法返回的假设的平均性能永远不会小于某个量。 * 高概率保证。这些保证确保,以高概率,算法返回的假设的性能永远不会小于某个量。在信息论泛化的背景下,这种保证被称为PAC-Bayesian保证。研究学习算法泛化的经典方法侧重于算法考虑的假设类的复杂性。这指的是算法可以选择的可能假设的丰富性。这些方法背后的思想是,来自更复杂类的假设可以很好地适应训练集,但它们可能过度拟合,即它们可能适应它们观察到的特定数据的采样噪声,这可能与未来的实例不同。另一方面,来自更简单类的假设不能适应采样噪声,并需要关注数据中的高信号模式,代表数据分布。更简单类的缺点是它们缺乏丰富性,可能意味着它们的假设无法很好地描述训练集中的模式。然而,它们仍然具有小的泛化误差,它们在训练集中的表现不佳预示着在新的、未见过的数据上的表现也不佳。请参见图1.1,了解这种二分法的示例。像基于均匀收敛或Rademacher复杂性的经典方法的一个重要特征是,它们为算法考虑的整个假设类提供泛化保证。这可能太限制性了,因为在一个复杂的假设类中,仍可能有假设能够很好地泛化。脱离这种限制的一种方法是算法稳定性框架,它为稳定的算法提供泛化保证,即在呈现类似训练集时返回相似假设的算法。通过这种方式,算法稳定性可以保证考虑复杂假设的算法的泛化,只要它们在类似的训练集上一致地返回这些假设。通常,“类似训练集”的概念只考虑观察到的数据的每个可能值,无论多不可能,使得框架对某些情况过于限制性。最后,信息论泛化框架提供了针对算法和数据分布特定的保证。其思想是使用信息度量来捕捉算法返回的假设与训练集之间的依赖性。直观地说,假设对它看到的特定实例的依赖越多,它就越过度拟合,泛化性就越差。这种个性化的方法虽然更细致,但在之前的方法失败的情况下允许更强的理论结果。信息论泛化框架阐明了隐私和泛化之间的联系。如果算法返回的假设不泄露或不依赖于用于训练的实例的太多信息,那么算法是私密的。因此,算法越私密,算法返回的假设与训练集之间的依赖性就越小,它的泛化性就越好。