

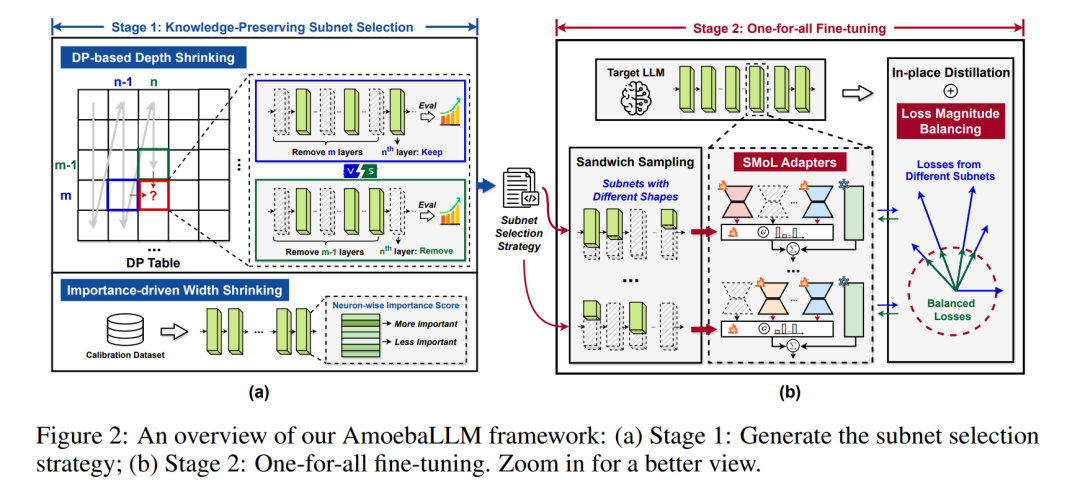
受大型语言模型(LLMs)在各种自然语言任务中的变革性能力的启发,针对多样化的现实世界应用和平台有效部署这些模型的需求日益增长。然而,由于应用场景特定的性能需求不同,以及计算平台快速演进带来的资源限制和部署流程差异,LLMs的高效部署面临越来越显著的挑战。这些多样化的需求促使研究者开发能够根据不同平台和应用需求调整其结构(深度和宽度)的LLMs,以实现最佳效率。 为了解决这一关键问题,我们提出了 AmoebaLLM,一个创新的框架,旨在支持即时生成任意形状的LLM子网络。这些子网络不仅能够达到准确性和效率的前沿,还可以在一次性微调后立即提取。通过这种方式,AmoebaLLM大大简化了针对不同平台和应用的快速部署过程。 具体来说,AmoebaLLM集成了以下三项创新组件: 1. 知识保留的子网络选择策略,包括用于深度压缩的动态规划方法和基于重要性驱动的宽度压缩方法; 1. 形状感知的LoRA混合策略,以缓解微调过程中子网络之间的梯度冲突; 1. 就地蒸馏机制,采用平衡损失幅度作为微调目标。
广泛的实验验证表明,AmoebaLLM不仅在LLM的适应性方面设定了新标准,还能够成功提供在准确性和效率之间实现最新权衡的子网络。我们的代码已开源,访问地址为 https://github.com/GATECH-EIC/AmoebaLLM。
成为VIP会员查看完整内容
相关内容
Arxiv
36+阅读 · 2023年4月19日
Arxiv
173+阅读 · 2023年4月7日
Arxiv
123+阅读 · 2023年3月29日
Arxiv
75+阅读 · 2023年3月21日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
173+阅读 · 2023年4月7日
Arxiv
123+阅读 · 2023年3月29日
Arxiv
75+阅读 · 2023年3月21日