

大规模多模态模型(LMMs)的快速发展已经彻底改变了深度学习领域,使得在文本、图像和音频等多种模态上的复杂理解与生成成为可能。随着这些强大模型在从资源受限的边缘设备到大规模云环境的各种现实场景中的部署需求日益增长,对LMMs进行大小扩展的研究变得愈发必要。小型模型满足了效率的需求,尤其在边缘设备上部署多模态系统时尤为重要,而大型模型则强调了扩展性的追求,即利用不断增长的计算能力和数据以实现更高的准确性。
在本论文中,我们将探讨对LMMs进行上下扩展的技术,重点关注三个关键领域:推理效率、训练可扩展性以及多模态增强。我们首先研究诸如量化和剪枝等方法,以减少LMMs的计算和内存占用,使其适合在资源受限的设备上部署。随后,我们深入探讨了如专家混合(MoE)和分阶段扩展等技术,以实现对拥有海量参数的LMMs的高效训练,从而能够充分利用大规模数据和计算资源。通过采用整体化的方法,我们重新审视了LMMs的高效训练与推理范式,策略性地通过扩展训练规模以实现高效训练,再通过缩减规模优化推理。最后,我们研究了针对LMMs的领域特定优化,包括改进的视觉编码器以实现LMMs更广泛的应用迁移、通过知识增强数据进行高效的LMM预训练,以及通过事实性驱动的强化学习与人类反馈(RLHF)进行的数据中心化LMM对齐。
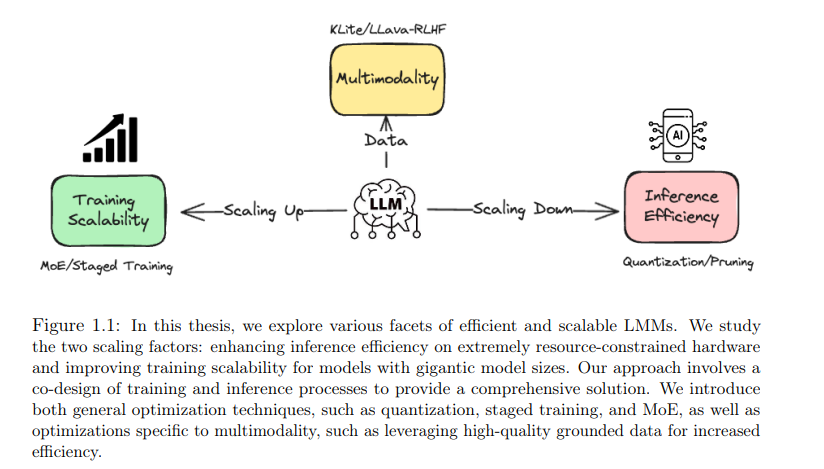
动机
深度学习在多个领域中取得了显著进展,包括计算机视觉【205, 192, 132, 81】、自然语言处理【392, 77, 38】、图像生成【116, 137】和语音识别【444, 23】。深度学习技术的有效性在过去几年中迅速提升,这得益于创新算法的推动以及模型和数据规模的持续扩展。例如,标志着2012年深度学习革命开端的AlexNet【192】模型包含了6000万参数——在当时被认为是一个相当大的数字。而到了2020年,GPT-3模型【38】已经拥有1750亿参数,并且到2024年,LLaMA-3模型的参数数量达到了惊人的4050亿【84】。这意味着在不到十年的时间里,参数数量从6000万增长到4050亿,增长了超过600万倍。值得注意的是,这种扩展趋势还在加速,即使在这些庞大的规模下也没有放缓的迹象【171, 453】。
效率与模型的缩减相关,同时保留足够的能力,以便能够在边缘设备上快速运行。当前的先进模型通常需要使用先进的GPU集群进行大规模并行训练。与模型规模、内存消耗和计算操作相关的高昂成本可能严重阻碍其在资源受限设备(如手机)上的部署。开发提高模型效率的方法对于更广泛的应用至关重要。研究人员已经探索了各种策略来实现这一目标,包括设计适合移动设备的新架构【145, 336】、实施权重的低秩近似【158】、网络剪枝【101, 475】、权重量化【150, 451, 469, 233】、自适应计算【470】和知识蒸馏【372, 383】。随着预训练大型模型的资源需求增加,使它们更紧凑和更快速变得越来越关键。
可扩展性则解决了模型在扩展到拥有大量参数并在大规模数据集上训练时的表现问题。如果设计不当,随着数据和计算资源的增加,网络性能可能会出现瓶颈【480】。理想情况下,模型的准确性应随着系统扩展而逐步提高【171】。一个成功扩展的典型例子是Transformer模型【392】的引入,它超越了之前的LSTM模型【138】的性能。在LSTM中,增加网络容量可能导致梯度不稳定,导致更高的训练损失。然而,确定如何在数据、参数和训练算法等不同组件之间最佳分配计算资源是一个复杂的问题,通常与架构密切相关,无论是专家混合(MoE)【353】还是Dense架构【38】。因此,可扩展性的研究不仅涉及设计创新的架构【81, 471】,还包括制定扩展定律【171】,改进分布式训练的算法【175, 117, 441, 442】,以及优化数据或优化算法【78, 21, 125】以解决超大规模模型扩展中的不稳定性问题。
多模态性指的是整合多种形式的数据(如文本、图像和音频),以增强模型的学习能力。这种方法利用各种数据类型的不同优势,以提高模型在不同任务中的整体性能和适用性。随着模型变得越来越多模态化,它们能够更好地理解和解释复杂的现实世界数据,通过从多种数据源中获取更全面的见解来实现这一点。开发强大的多模态模型需要应对诸如数据对齐、融合策略以及在不同模态之间保持平衡等挑战。研究人员通过创新技术,如跨模态注意力机制【2, 221, 407】、模态特定编码器【316, 244, 215, 71】和统一的训练框架【53, 449, 417, 409, 182, 383, 446, 293】,不断推动这一领域的发展。这些方法不仅确保模型学习共享表示,还保留并利用了每种模态的独特特性。随着对复杂、上下文感知AI系统需求的增长,增强多模态性仍然是研究的关键领域。这包括探索更高效的方式来整合和处理多模态数据【234, 456, 26, 203】,提高对齐精度【371, 275, 3】,并开发可扩展的解决方案以适应各种应用和更大规模的数据集【453, 51, 50, 240, 382】。
在上述三个领域的研究进展令人鼓舞,特别是在将复杂的大型模型【84, 383, 382, 292, 9, 293】部署到从移动设备到计算资源稀缺的边缘计算环境中的现实场景中的需求日益增加【383, 382】。在本论文中,除了介绍高效推理的新框架【308】和可扩展训练算法【171】外,我们还从批判性角度对高效扩展范式进行了实证研究,考虑了训练和推理计算的各个方面。我们的研究结果表明,先扩大模型规模然后压缩它们可以产生出乎意料的更好效果。这种方法为与大型语言模型(LLMs)相关的整体计算因素提供了更深的洞察,并有助于更准确和公平地分配扩展组件。
除了针对LLMs的一般优化技术,如剪枝【337】、量化【233】、蒸馏【383】和扩展定律【171, 62】之外,探索多模态特定的优化机会,以进一步减少冗余并提升操作能力也是至关重要的。一个相关的例子是大规模多模态语言模型(LMMs),它包含一个LLM、一个视觉编码器和一个多模态集成模块。盲目地扩展集成模块可能会导致效果下降【244】。相反,扩展视觉编码器模块【354】在各种多模态应用(如字幕生成、视觉问答或导航)中展示了可迁移的性能,这种性能还可以通过训练数据增强进一步提升【355】。此外,在对齐阶段使用高质量数据【371】可以提高数据效率,并增强模型的能力和可靠性。这些优化针对应用的特定属性,超越了普通模型优化技术所能实现的效果。
论文大纲
在本论文中,我们探讨了对大规模多模态模型(LMMs)进行上下扩展的方法,重点关注三个主要方面:推理效率、训练可扩展性,以及通过创新的集成技术和高质量数据的使用来改进多模态性。在第一部分中,我们在第2章介绍了我们的量化工作,并在第3章讨论了剪枝算法,这些算法旨在减少不必要的内存使用,从而促进LMMs的实际应用。在第二部分中,我们概述了增强LMMs可扩展性的策略,以确保模型在扩展时性能得到提升。这包括在第4章中讨论的高质量指令数据的后训练,以及在第5章中从小到大的分阶段扩展预训练。通过采用整体化方法,我们在第6章重新审视了LMMs的高效训练和推理实践,处理了扩展和缩减的问题。随后,我们深入探讨了针对LMMs的领域特定增强(第三部分),其中包括促进LMMs更广泛应用的增强视觉编码器(第7章)、通过知识增强数据进行高效预训练(第8章)以及通过事实性驱动的RLHF进行的数据中心化LMM对齐(第9章)。最后,第10章总结了本论文的关键发现,并讨论了进一步提高LMMs效率和可扩展性的潜在未来研究方向。



