

遗忘指的是以前获得的信息或知识的丧失或退化。尽管现有的关于遗忘的调查主要集中在持续学习上,但在深度学习的各种其他研究领域中都观察到了遗忘这一普遍现象。遗忘在诸如生成模型(由于生成器的变化)和联合学习(由于客户端之间的异质数据分布)等研究领域中都有表现。解决遗忘涉及多个挑战,包括平衡保留旧任务知识与快速学习新任务的能力、管理具有冲突目标的任务干扰以及防止隐私泄漏等。此外,大多数关于持续学习的现有调查都暗示遗忘始终是有害的。与此相反,我们的调研认为遗忘是一把双刃剑,在某些情况下,如保护隐私的场景中,遗忘可能是有益的和可取的。通过在更广泛的背景下探索遗忘,我们旨在呈现对这一现象的更为细致的理解,并突出其潜在的优势。通过这一全面的综述,我们希望通过吸取各领域处理遗忘的思路和方法来发掘潜在的解决方案。通过超越其传统界限来检查遗忘,我们希望在未来的工作中鼓励开发新策略,以减轻、利用或甚至在真实应用中接受遗忘。关于各研究领域中遗忘的论文的全面列表可在https://github.com/EnnengYang/Awesome-Forgetting-in-Deep-Learning 上找到。
遗忘[1] 是指机器学习系统中以前获得的信息或知识随着时间的推移而退化的现象。在神经网络的早期,人们主要关注的是在静态数据集上训练模型。在这些设置中,遗忘并不是一个重大的关注点,因为这些模型是在固定的数据集上进行训练和评估的。McCloskey 和 Cohen [1] 首次正式介绍了灾难性遗忘的概念。他们证明了神经网络在连续对不同任务进行训练时,当学习新任务时,往往会忘记之前学到的任务。这一观察突显了在连续学习情境中处理遗忘的必要性。后来,解决遗忘的问题被正式定义为持续学习(CL)。如今,遗忘不仅在CL领域受到了极大的关注,而且在更广泛的机器学习社区中也引起了极大的关注,它已经演变成为整个机器学习领域的一个基本问题。
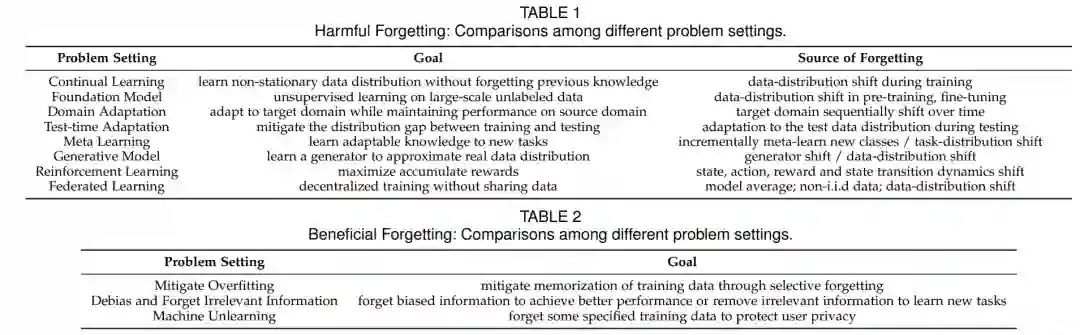
现有关于遗忘的调查主要集中在CL上[2]、[3]、[4]、[5]、[6]、[7]、[8]、[9]。然而,这些调查往往只关注遗忘的有害效果,而缺乏对该话题的全面讨论。与此相反,我们的调查旨在提供对遗忘的更全面的理解。我们强调了它作为双刃剑的双重性质,强调其益处和害处。此外,我们的调查超出了CL的范围,涵盖了其他各个领域中的遗忘问题,包括基础模型、领域适应、元学习、测试时适应、生成模型、强化学习和联邦学习。通过这样做,我们提供了一个全面的遗忘检查,涵盖了更广泛的背景和应用范围。在这次调查中,我们将机器学习中的遗忘分为两类:有害遗忘和有益遗忘,具体取决于特定的应用场景。当我们希望机器学习模型在适应新任务、领域或环境时保留以前学到的知识时,就会发生有害的遗忘。在这种情况下,防止和减轻知识的遗忘是很重要的。相反,当模型包含可能导致隐私泄露的私有信息,或者当无关的信息妨碍新任务的学习时,就会出现有益的遗忘。在这些情况下,遗忘变得是可取的,因为它有助于保护隐私,并通过丢弃不必要的信息来促进有效的学习。
1.1 有害遗忘
不仅在CL中,还在包括基础模型、领域适应、元学习、测试时适应、生成模型、强化学习和联邦学习在内的各种其他研究领域都观察到了有害遗忘。虽然现有的调查主要集中在CL背景下的遗忘,但它们经常忽视对这些其他相关研究领域的全面检查。本调查旨在通过提供一个关于不同学习场景中遗忘的概述,涵盖上述研究领域,来填补这一空白。
在这些研究领域中的遗忘可以归因于各种因素。在持续学习的背景下,由于不同任务之间数据分布的变化,遗忘发生。在元学习中,遗忘是任务分布变化的结果。在联邦学习中,遗忘是由于不同客户之间的数据分布异质性导致的,这通常被称为客户端漂移。在领域适应中,由于领域的变化,遗忘发生。在测试时适应中,遗忘是由于在测试中适应测试数据分布的结果。在生成模型中,由于生成器随时间的变化或在学习非平稳数据分布时,遗忘发生。在强化学习中,由于状态、行动、奖励和状态转移动态随时间的变化,遗忘可能发生。这些环境基础因素的变化可能导致在强化学习过程中先前学到的知识的丧失或改变。在基础模型的情况下,遗忘可以归因于三个不同的原因:微调遗忘、增量流数据预训练,以及利用基础模型进行下游CL任务。为了促进对与遗忘相关的各种设置的清晰性和比较,我们在表1中呈现了有害遗忘的全面分析,突出了不同设置之间的区别。
1.2 有益的遗忘
尽管在大多数现有的工作中普遍认为遗忘是有害的,但我们已经认识到遗忘是一把双刃剑。在学习的神经网络中有许多情况下忘记某些知识是有利的。有意的遗忘在两个主要场景中证明是有益的:(1)选择性遗忘,有助于减轻过拟合并丢弃不有用的信息以提高模型的泛化能力;和(2)机器反学习,防止数据隐私泄露。 首先,过拟合长期以来一直是机器学习中的一个基本问题,当一个模型记住了训练数据但难以泛化到新的、未见过的测试数据时就会发生。为了增强泛化能力,模型避免记忆而专注于学习输入数据和标签之间的真正关系是有利的。此外,先前获得的知识可能对于提高新信息的未来学习并不相关或有益。在这种情况下,丢弃模型记忆中保留的无关信息变得很有必要。通过释放模型内的容量,它变得更容易获取新知识。 另一方面,机器学习模型的用户可能要求从数据库中删除他们的训练数据,而不仅仅是预训练模型本身的任何痕迹,行使他们的“被遗忘权”[10]。为了解决这个问题,研究人员探索了机器反学习的概念,允许有意忘记不希望的私人训练数据。此外,某些隐私攻击利用机器学习模型的记忆效应从预训练模型中提取私人信息。例如,成员推断攻击[11]可以确定一个数据点是否属于与预训练模型相关的训练数据。由于神经网络的记忆效应,这些隐私攻击在实践中可能是成功的。在这种情况下,有意地忘记私人知识在保护隐私和防止信息泄露上是有益的。 为了便于比较,我们还提供了一个关于有益遗忘的比较分析,涵盖上述提到的多种设置作为参考,见表2。
1.3 应对遗忘的挑战
应对遗忘面临众多挑战,这些挑战在不同的研究领域之间有所不同。这些挑战包括:
数据可用性:在各种情境中,数据可用性都是一个重大挑战,并且大大复杂化了解决遗忘的任务。一方面,由于存储限制或在学习新任务时的数据隐私关切,之前任务的数据可用性可能受到限制。这个挑战在持续学习、元学习、域适应、生成模型和强化学习中尤为常见,因为在这些领域中,访问过去任务数据对于减轻遗忘和利用以前的知识至关重要。另一方面,某些情境禁止使用原始数据。例如,在联邦学习中,只有预训练模型的参数被传输到中央服务器,而不共享底层的训练数据。
资源限制:如那些对内存和计算有限制的环境,资源受限的环境呈现出有效应对遗忘的挑战。在在线连续学习和元学习中,数据或任务通常只处理一次,这些挑战尤为突出。此外,学习代理对过去的数据和经验的访问有限,这限制了加强之前学习任务的机会。对过去数据的有限接触使保持知识和有效减轻遗忘变得困难。此外,在线学习通常在资源受限的环境中运行,拥有有限的内存或计算能力。这些约束为在线环境中应对遗忘带来了额外的障碍。
适应新环境/分布:在连续学习、基础模型、强化学习、域适应、测试时适应、元学习和生成模型等多个领域,目标环境或数据分布可能会随时间变化。学习代理需要适应这些新环境或情境。这种适应可以在训练阶段或测试阶段发生。但是,当学习代理适应新的情境和环境时,遗忘的挑战就会出现。由于数据分布的变化,代理往往会失去之前获得的知识或在早期任务上的表现。
任务干扰/不一致:不同任务之间的冲突和不兼容目标可能导致任务干扰,这在防止遗忘时构成了挑战。这个问题在连续学习和联邦学习等不同的背景下都有观察到。在连续学习中,连续观察到的任务可能具有冲突的目标,使得网络难以在多个任务上平衡其表现。随着网络学习新任务,这些冲突目标的干扰可能加剧了遗忘问题。同样,在联邦学习中,由于客户端之间的数据分布不均匀,不同客户端上训练的模型可能表现出不一致[12]。这些不一致可能导致任务或客户端干扰,进一步加剧了遗忘问题。
防止隐私泄露:在某些情境中,保留旧知识可能会引起隐私问题,因为它可能无意中暴露私人信息。因此,解决这些隐私风险并防止敏感数据的意外披露至关重要。在这个背景下,目标转向忘记或擦除训练数据的痕迹,而不是记忆它们,从而保护用户隐私。这个特定的挑战出现在机器遗忘[13]领域,该领域专注于开发有效忘记或从机器学习模型中删除训练数据痕迹的技术。
1.4 调查范围、贡献和组织结构
调查范围
我们的主要目标是为上述领域中的主要研究方向提供一个全面的关于遗忘的概述。这些领域被选为代表性的研究方向,其中遗忘起到了重要的作用。通过涵盖这些领域,我们旨在揭示遗忘在这些研究领域中的存在和影响。
贡献
我们的贡献可以总结为三点: • 与现有的调查相比,我们对CL提供了更为系统的调查。我们的调查包括了更为系统的CL问题设置和方法的分类,为该领域提供了更为深入的概述。 • 除了CL,我们的调查范围还扩展到其他研究领域,如基础模型、元学习、领域适应、测试时适应、生成模型、联邦学习、强化学习和机器遗忘。这更广泛的覆盖提供了对遗忘在各种研究领域的全面理解。 • 与现有的关于CL和遗忘的调查相比,我们的调查揭示了遗忘可以被视为一把双刃剑。虽然它经常被视为一种挑战,但我们强调在保护隐私的场景中,遗忘也具有可取之处。
组织结构
本文的结构如下:在第2-9节中,我们对各种机器学习领域中的有害遗忘现象进行了全面的调查。这些包括连续学习、基础模型、领域适应、测试时适应、元学习、生成模型、强化学习和联邦学习。每一节都探讨了在这些特定领域内遗忘的发生和影响。在第10节中,我们深入探讨了有益的遗忘及其在增强模型泛化性能和促进机器遗忘中的作用。这一节突出了遗忘在特定学习场景中的积极方面。在第11节中,我们介绍了当前的研究趋势,并提供了对该领域未来可能的发展的见解。

