视觉问题回答要求系统在给定图像和自然语言问题的情况下提供准确的自然语言答案。然而,众所周知,先前的通用VQA方法往往表现出倾向于记忆训练数据中存在的偏见,而不是学习适当的行为,例如在预测答案之前定位图像。因此,这些方法通常在分布内表现良好,但在分布外表现不佳。近年来,已经提出了各种数据集和去偏方法,分别用于评估和增强VQA的鲁棒性。本文是第一个全面关注这一新兴领域的综述。具体来说,我们首先从分布内和分布外的角度提供数据集的发展过程概述。然后,我们检查这些数据集使用的评估指标。第三,我们提出了一个分类学,展示了现有去偏方法的发展过程、相似性和差异性、鲁棒性比较和技术特性。此外,我们分析并讨论了VQA上代表性的视觉-语言预训练模型的鲁棒性。最后,通过对现有文献的深入审查和实验分析,我们从各种视角讨论了未来研究的关键领域。
https://www.zhuanzhi.ai/paper/30fd48189b534294b85cf1544485e5d1
1. 引言
视觉问题回答(VQA)的目标是构建智能机器,使其能够在给定图像和关于该图像的自然语言问题的情况下准确地提供自然语言答案[1]。VQA的目标是教机器像人类一样同时看和读,它桥接了计算机视觉和自然语言处理。这个任务具有多种应用,涵盖了为盲人和视觉受损者提供关于周围世界的信息、在缺乏元数据的情况下促进图像检索[2]、增强智能虚拟助理[3]、开启视觉推荐系统[4]以及为自动驾驶做出贡献[5]等领域。例如,我们可以使用VQA方法在所有候选图像中查询“图片中有熊猫吗?”以识别包含熊猫的图像。在过去的几年里,VQA在研究界引起了广泛关注[6],[7],[8],[9],[10],[11],这可以归因于两个关键的发展。首先,已经构建了一些数据集,如VQA v1[1]、VQA v2[12],用于细粒度检测和识别,FVQA[13]、OK-VQA[14]用于基于外部知识的推理,以及GQA用于组合推理[15],这些数据集被用来从不同的角度评估方法的能力。其次,提出了各种VQA方法,可以分为三类[2]:联合嵌入、注意机制和外部知识。特别是基于联合嵌入的方法[1]、[16]、[17]将图像和问题的表示投影到一个公共空间以预测答案。这些方法通常学习粗粒度的多模态表示,这可能在预测阶段带来噪声或不相关的信息。为了解决这个问题,基于注意机制的方法[18]、[19]、[20]、[21]通常根据对象和单词的学习重要性融合问题和图像的表示。在实际场景中,VQA通常要求机器不仅要理解图像内容,还要理解从常识到百科知识的外部先验信息。例如,考虑问题“图片中有多少真菌植物?”,机器应该理解“真菌”这个词,并知道哪些植物属于这一类别。为此,基于外部知识的方法[22]、[23]、[24]将从大型知识库如DBpedia[25]、Freebase[26]和YAGO[27]中提取的知识链接到多模态学习[28]中。

然而,与上述工作并行,有几项研究[29]、[30]、[31]、[32]、[33]发现前述的通用方法更倾向于记忆训练数据中的统计规律或偏见,而不是对图像进行定位以预测答案。例如,在Fig. 1的第四列中间的条形图中,我们可以看到“网球”是最频繁的答案。这些方法主要是通过利用问题中关键词“what”和“sports”与“tennis”之间的关联来回答第二列的问题。这将导致这些方法在具有与训练分割相似的答案分布的In-Distribution (ID) 测试场景中表现良好,如第四列中间的条形图中的分布,但在具有不同或甚至相反答案分布的Out-Of-Distribution (OOD) 测试情况下表现不佳,如底部条形图中的分布。为了解决这个问题,近年来出现了大量关于VQA的文献,特别是关注消除偏见[29]、[34]、[35]和评估鲁棒性[29]、[36]、[37]。
本文的目的是为鲁棒性VQA领域的方法、数据集和未来挑战提供一个全面和系统的概述。据我们所知,这篇文章是关于这个话题的第一篇综述。在第2部分,我们为通用和鲁棒性VQA建立初步概念。第3部分从各种角度讨论了数据集,包括建设、图像来源、图像和问题的数量以及重点。它们基于ID和OOD设置被分类为两类。第4部分回顾了上述数据集中使用的评估指标,包括单一和复合指标。在第5部分,我们对去偏方法进行了关键性分析,将它们分类为四类:集成学习、数据增强、自监督对比学习和答案重新排序。第6部分回顾了代表性的视觉和语言预训练方法的发展,并根据文本编码器、图像编码器和模态交互模块的相对计算大小将它们划分为四类。我们还讨论了这些方法在最常用的VQA v2 [12] (ID) 和 VQA-CP (OOD) [29] 数据集上的鲁棒性。此外,在第7部分,我们从注释质量的改进、数据集创建的持续发展、评估指标的进步、方法鲁棒性和鲁棒性评估的角度进行了深入的未来挑战讨论,基于我们的实验结果和文献概述。最后,我们在第8部分提出了我们的结论性意见。
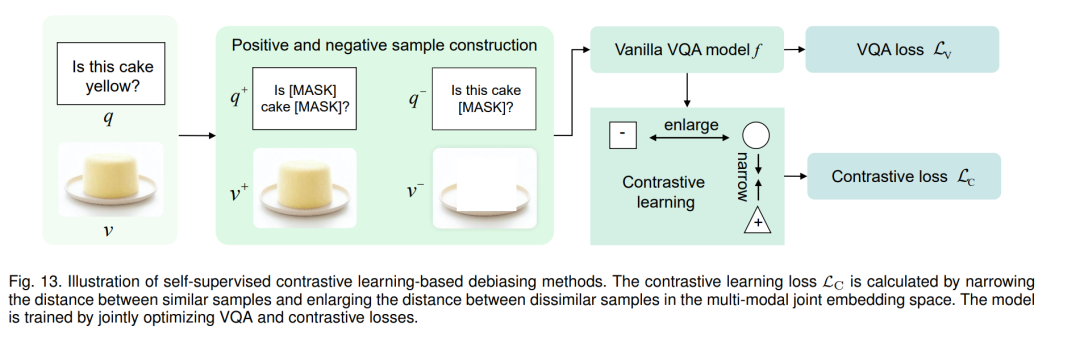
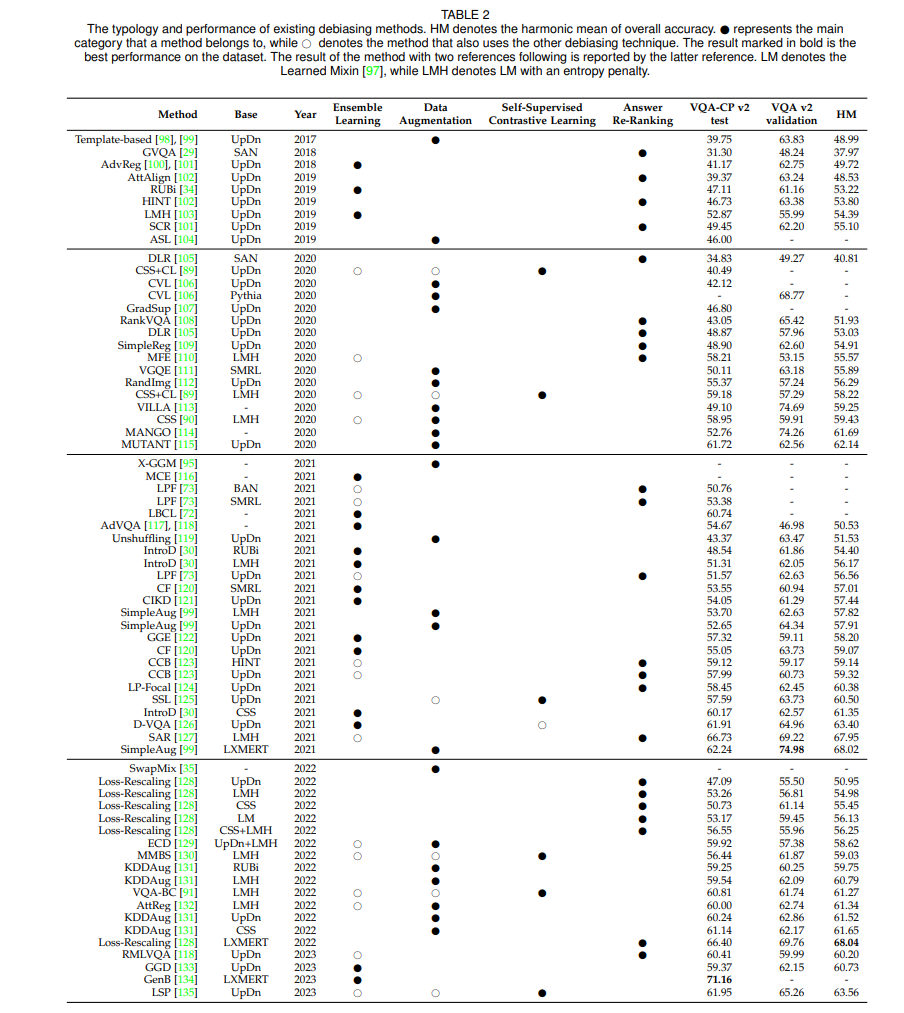
近年来,基于通用方法如 UpDn [19]、BAN [94]、SMRL [20] 和 LXMERT [81],提出了各种 VQA 去偏见方法 [33]、[95]、[96] 以增强鲁棒性。我们根据去偏见技术将这些方法分为四类:集成学习、数据增强、自监督对比学习和答案重新排序。表2展示了它们的类型以及它们在 VQA-CP v2 [29] 测试分割和 VQA v2 [12] 验证分割上的性能。
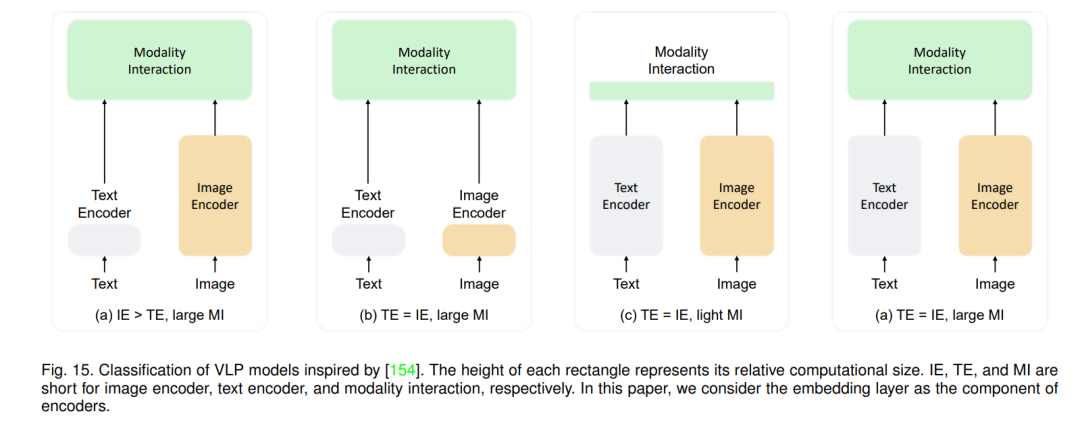
视觉-语言预训练方法 大多数先前概述的方法都是任务特定模型,它们在有限的数据上进行训练。然而,还有其他值得探索的途径,例如在大量数据上训练的任务不可知模型。尤其在近年来,视觉-语言预训练 (VLP) [47]、[48]、[81]、[154]、[160]、[161]、[162]、[163]、[164]、[165]、[166]、[167]、[168]、[169]、[170]、[171] 在使用大规模图像-文本对的多模态表示学习领域取得了显著进展。VLP模型在预训练期间通常采用图像-文本匹配 (ITM) 和掩蔽语言模型 (MLM) 目标在图像及其相应的标题上,然后在下游任务,如VQA上进行微调。众所周知,VLP模型通常比在有限数据上训练的模型更为鲁棒 [114]、[172]、[173]。通常,VLP模型由文本编码器、图像编码器和模态交互模块组成。受[154]启发,我们根据文本编码器、图像编码器和模态交互模块的相对计算大小,将当前的VLP模型分类为四种类型,如图15所示。在本文中,我们将嵌入层视为编码器的组成部分。共识是,图像通常包含比文本更丰富的信息,因此直观地说,视觉端的编码器应该比文本端的编码器大。此外,作为一种多模态任务,VLP中模态之间的交互也很重要,模态交互模块的计算成本不应该被牺牲。因此,第三种类型的模型在实验上的性能比其他类型的模型差[154]。