尽管深度神经网络(DNNs)在许多领域已经显示出解决大规模问题的强大能力,但由于其庞大的参数,这些DNNs很难在实际系统中部署。
为了解决这个问题,提出了教师-学生架构,其中参数较少的简单学生网络可以达到与参数众多的深度教师网络相当的性能。最近,教师-学生架构在各种知识蒸馏(KD)目标上得到了有效且广泛的应用,包括知识压缩、知识扩展、知识适应和知识增强。
在教师-学生架构的帮助下,当前的研究能够通过轻量级和泛化的学生网络实现多种蒸馏目标。
与主要关注知识压缩的现有KD综述不同,本综述首先探讨了在多种蒸馏目标下的教师-学生架构。本综述介绍了各种知识表示及其相应的优化目标。此外,我们提供了教师-学生架构的系统概述,包括代表性的学习算法和有效的蒸馏方案。此外,本综述还总结了教师-学生架构在多种目的上的最近应用,包括分类、识别、生成、排名和回归。
最后,本综述探讨了KD的潜在研究方向,重点是架构设计、知识质量,以及基于回归的学习的理论研究。通过这个全面的综述,工业界从业者和学术界可以获得宝贵的见解和指导方针,有效地设计、学习和应用教师-学生架构在各种蒸馏目标上。
知识蒸馏的教师-学生架构
深度神经网络(DNNs)在多个领域取得了很大的成功,如计算机视觉[1](CV)、通信系统[2]和自然语言处理(NLP)[3]等。特别地,为了满足大规模任务的稳健性能,DNNs通常具有复杂的架构,并进行了过度参数化。然而,这种繁重的模型同时需要大量的训练时间并带来巨大的计算成本,这给这些模型在边缘设备上的部署以及在实时系统中的应用带来了重大挑战。
为了加速训练过程,Hinton等人[4]首次提出了知识蒸馏(KD)技术,用于训练轻量级模型以达到与深度模型相当的性能。这是通过将一个大型且计算昂贵的模型(即教师模型)的有用知识压缩到一个小型且计算高效的模型(即学生模型)来实现的。有了这样的教师-学生架构,学生模型可以在教师模型的监督下进行训练。在学生模型的训练过程中,学生模型不仅应尽可能接近地预测出真实的标签,还应匹配教师模型的软化标签分布。因此,压缩后的学生模型能够获得与笨重的教师模型相当的性能,并且可以高效地部署在实时应用和边缘设备中。
除了知识压缩外,教师-学生架构同时也在其他的KD目标上得到了有效且广泛的应用,包括知识扩展、知识适应和知识增强。在教师-学生架构的帮助下,我们能够通过有效且泛化的学生网络实现多种蒸馏目标。 在知识扩展中,由于模型的强大容量和复杂的学习任务,学生网络可以从教师网络中学习扩展的知识,这样学生在更复杂的任务中能够展现出比教师更好的性能和泛化能力[5, 6, 7]。为了实现知识适应的目标,学生网络可以在一个或多个目标域上进行训练,其中教师网络的适应知识是基于源域构建的[8, 9]。在知识增强中,学生网络可以在专门的教师网络的监督下学习更通用的特征表示,这样的通用学生网络可以在多个任务中有效地泛化[10, 11]。
随着教师-学生架构的最近进展,一些研究已经总结了教师-学生架构下各种蒸馏技术的最近进展。具体来说,Gou等人[12]主要从以下几个角度提供了一个全面的KD综述:知识表示、蒸馏方案和算法。Wang等人[13]为视觉领域的教师-学生架构中的模型压缩提供了一个系统的概述和深入的见解。Alkhulaifi等人[14]总结了多种度量标准,以评估蒸馏方法在模型大小减少和性能方面的效果。
然而,现有的KD综述[12, 13, 14]主要关注于知识压缩目标的教师-学生架构,因此需要对所有的蒸馏目标进行全面的综述。此外,知识类型可以归纳为三个类别:基于响应的、中间的、基于关系的和基于互信息的表示。知识优化目标可能会根据具体的知识表示而有所不同。然而,现有的综述[12, 13, 14]最多只提供了三种知识表示的审查,缺乏对不同表示下的知识优化的全面介绍。此外,现有的工作[12, 13, 14]主要解释了在视觉识别和NLP领域的教师-学生架构的应用,这表明其他任务(如生成、排名和回归)也在被讨论。
然而,现有的KD综述[12, 13, 14]主要关注于知识压缩目标的教师-学生架构,因此需要对所有的蒸馏目标进行全面的综述。此外,知识类型可以归纳为三个类别:基于响应的、中间的、基于关系的和基于互信息的表示。知识优化目标可能会根据具体的知识表示而有所不同。然而,现有的综述[12, 13, 14]最多只提供了三种知识表示的审查,缺乏对不同表示下的知识优化的全面介绍。此外,现有的工作[12, 13, 14]主要解释了在视觉识别和NLP领域的教师-学生架构的应用,这表明其他任务(如生成、排名和回归)也在被讨论。
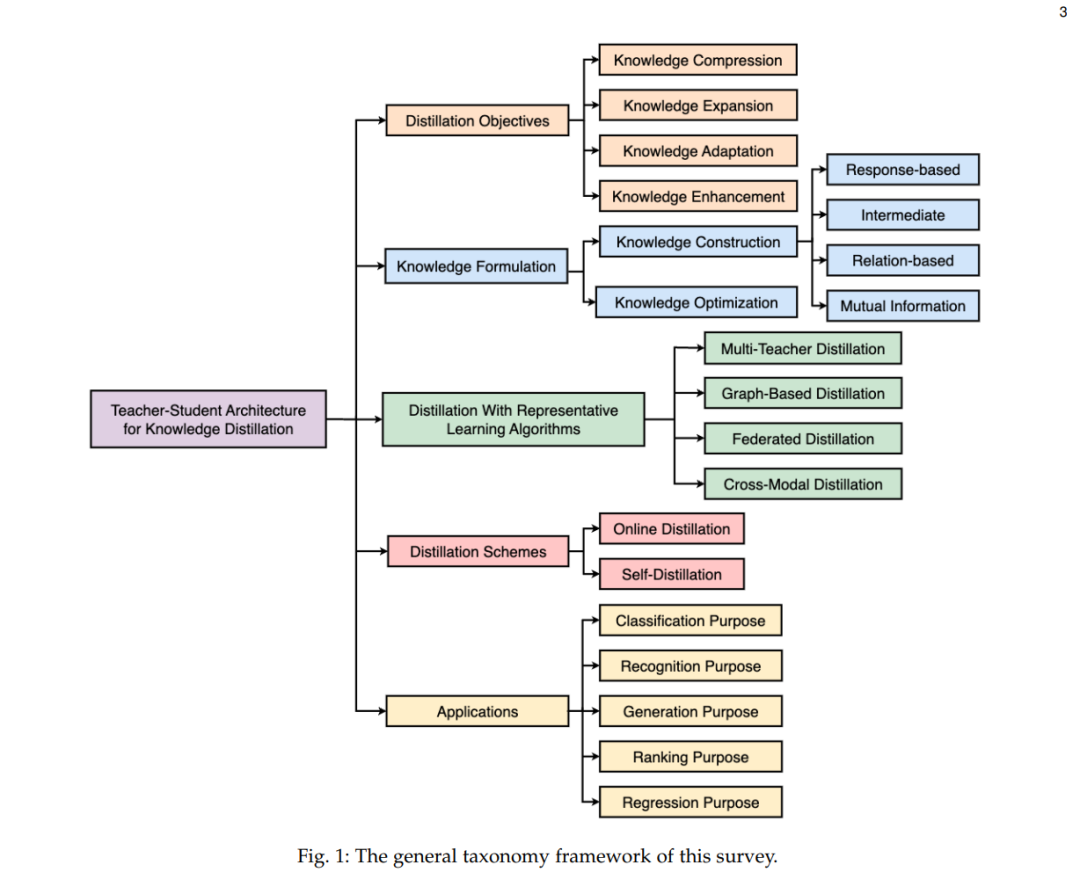
为此,这篇综述为KD的教师-学生架构提供了一个全面而深入的指南。如图1所示,我们综述的一般分类框架,首先讨论了基于多个KD目标的教师-学生架构,包括知识压缩、知识扩展、知识适应和知识增强。本综述为多种知识表示(即基于响应的、中间的、基于关系的和基于互信息的表示)提供了详细的概述,并探讨了与每种特定表示相关的知识优化目标。此外,我们系统地总结了具有多种代表性学习算法的教师-学生架构(例如,多教师、基于图的、联邦的和跨模态蒸馏),同时在教师-学生架构的框架下介绍在线蒸馏和自蒸馏方案。还介绍了教师-学生架构的最新应用,从各种角度提供了见解:分类、识别、生成、排名和回归目的。最后,我们分别研究了基于教师-学生架构设计、知识质量和基于回归的学习理论研究的KD的潜在研究方向。
表1与我们的调查对比了之前的作品[12, 13, 14],总结了此调查的主要贡献: • 我们为多个蒸馏目标介绍了教师-学生架构的全面审查,包括知识压缩、知识扩展、知识适应和知识增强。 • 我们为多种知识表示提供了深入的审查,并探讨了与每种特定表示相关的优化目标。 • 我们总结了跨多种目的的教师-学生架构的最近应用,包括分类、识别、生成、排名和回归。 • 我们讨论了关于KD的有前景的研究方向,包括教师-学生架构设计、知识质量和基于回归的学习的理论研究。
本调查的其余部分组织如下:第2节描述了跨多个蒸馏目标的教师-学生架构。第3节介绍了知识表示和优化目标。第4节和第5节分别讨论了具有代表性学习算法和蒸馏方案的教师-学生架构。第6节总结了跨多种目的的教师-学生架构的最近应用。未来的工作和结论分别在第7节和第8节中得出。