

人类通常可以通过少量的示例快速高效地解决复杂的新学习任务。相比之下,现代人工智能系统往往需要成千上万甚至数百万次观察才能解决最基本的任务。元学习旨在通过利用类似学习任务的过去经验,将适当的归纳偏差嵌入学习系统,从而解决这一问题。历史上,针对优化器、参数初始化等元学习组件的方法已显著提高了性能。本论文旨在通过对通常被忽视的损失函数组件进行研究,探讨元学习以提升性能的概念。损失函数是学习系统的重要组成部分,它代表了主要学习目标,系统优化该目标的能力决定并量化了学习的成功。 在本论文中,我们开发了用于深度神经网络的元学习损失函数的方法。首先,我们引入了一种称为进化模型无关损失函数(EvoMAL)的符号模型无关损失函数元学习方法。该方法整合了损失函数学习的最新进展,使得在普通硬件上开发可解释的损失函数成为可能。通过实证和理论分析,我们发现了学习损失函数中的模式,这激发了稀疏标签平滑正则化(SparseLSR)的开发,这是一种显著更快且内存效率更高的标签平滑正则化方法。其次,我们挑战了损失函数必须是静态函数的传统观念,开发了自适应损失函数学习(AdaLFL)方法,这是一种用于元学习自适应损失函数的方法。最后,我们开发了神经过程偏置元学习(NPBML),这是一种任务自适应的小样本学习方法,能够同时元学习参数初始化、优化器和损失函数。
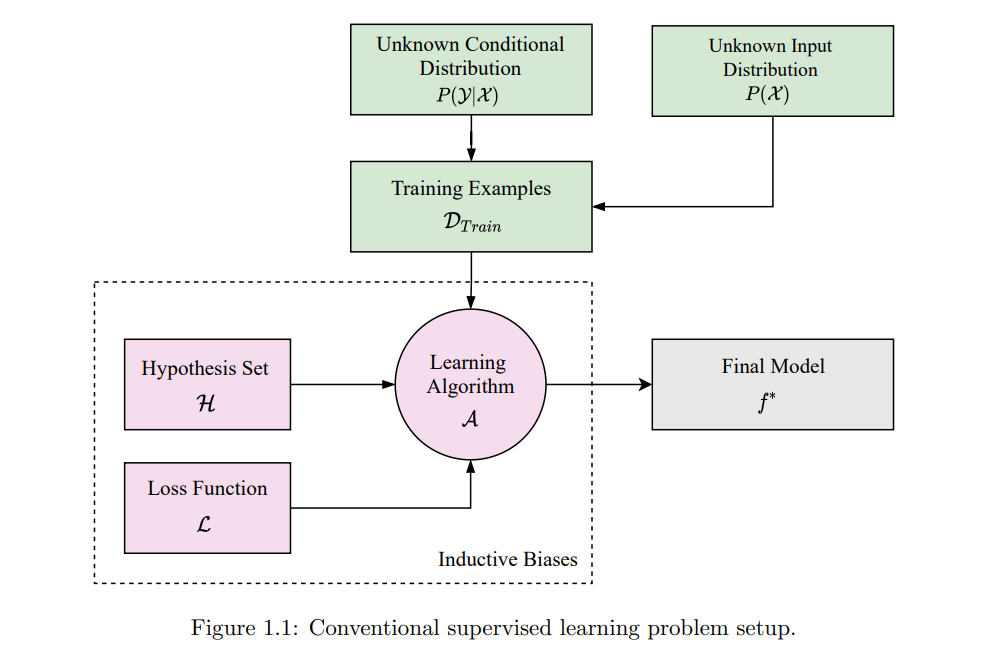
人类具备从极少量的观察中学习新任务的非凡能力。我们通常可以通过利用过去相关任务的经验,并结合关于目标领域的一小部分信息,快速适应新领域(Lake et al., 2015)。利用从过去经验中学到的共享任务规律,使人类能够在广泛的多样任务上表现出色,展示出一种相对普遍的智能形式。与此形成对比的是,现代人工智能和机器学习系统通常高度专业化,往往需要成千上万次的观察才能在单一任务上达到有竞争力的表现。这种样本效率低下的情况,是由于目前将从头开始的端到端学习视为学习的黄金标准(Collobert et al., 2011;Yi et al., 2014);其实际动机是能够在不需要嵌入大量人类知识和专业知识的情况下进行学习。 然而,正如Finn(2018)指出的那样,每次都要求系统从零开始学习每个任务,就像要求(人类)婴儿在没有掌握与语言、感知或推理相关的基本概念之前就学会编程一样,这显然是不合理的。为了缩小我们智能系统与人类之间的差距,显然需要重新考虑从零开始的学习方式,转而采用一种更具样本效率的学习方法。传统学习方法的另一个局限性是,它们通常需要预先假设一组归纳偏差,例如可搜索模型的类别,即表示偏差,或用于找到模型参数集合的学习规则,即程序偏差(Gordon & Desjardins, 1995)。然而,这种方法必然会导致次优性能,因为所选择的归纳偏差集合很少,甚至从未是任何特定学习问题的最佳选择。 因此,越来越多的研究开始探讨一种称为元学习的学习范式(Hospedales et al., 2022;Peng, 2020;Vanschoren, 2018;Vilalta & Drissi, 2002)。通常非正式地称为学习如何学习的范式。元学习旨在提供一种与传统AI方法相反的替代范式,即智能系统通过多次学习经历(通常但不限于覆盖一系列相关任务)利用过去的经验。元学习利用过去的经验来提高模型(通常是深度神经网络(LeCun et al., 2015;Goodfellow et al., 2016))未来的学习性能,通过自动选择适合于给定问题或相关问题族的归纳偏差集合(或其子集)(Hospedales et al., 2022)。 许多元学习方法已经被提出用于优化各种深度学习(DL)组件(Goodfellow et al., 2016)。例如,早期研究探索了使用元学习生成神经网络学习规则(Schmidhuber, 1987, 1992;Bengio et al., 1994),而更多的当代研究则扩展到了学习激活函数(Ramachandran et al., 2017)、共享参数初始化(Finn et al., 2017)和神经网络架构(Stanley et al., 2019)以及从头开始的整个学习算法(Real et al., 2020;Co-Reyes et al., 2021)等(Snell et al., 2017;Houthooft et al., 2018;Liu et al., 2020a;Alet et al., 2018;Franceschi et al., 2018)。






