近年来,机器学习在许多应用中证明了其极高的用途性。然而,这些成功故事很多都源于在与训练数据非常相似的数据上评估算法。当应用于新的数据分布时,机器学习算法已被证明会失败。鉴于现实世界数据的非平稳和异构性质,我们需要更好地掌握算法在分布外(out-of-distribution)的泛化能力,以便算法能被广泛部署和信任。我的论文提出了三个研究课题,旨在调查和发展分布外泛化的领域。这些研究努力的中心目标是产生新的工具,如算法、理论结果、实验结果和数据集,以提高在数据分布发生变化时机器学习方法的理解和性能。贯穿这三个机器学习场景的高级思想是模块性——由组合在一起形成一个整体的独立部分的质量。模块化方法被假设为引导机器学习方法远离僵化的记忆示例,走向更灵活和“更智能”的支持泛化的学习。
在我的第一项贡献中,我从多个训练分布的学习角度来接近论文目标。对这一研究方向的贡献有两方面。首先,我呈现了一组新的标准化任务,用于评估和比较分布外泛化算法。其次,我陈述了一系列新的理论结果,填补了数据中心和算法方法之间在分布外泛化方面的现有差距。这些理论发现引导了一组关于如何采用算法方法的新的实用建议。
在第二项贡献中,我处理了监督图像识别中的泛化问题。在这一背景下,我首先调查了多级特征聚合对泛化的影响,并证明了使用其中一种考虑的方法进行增强可以持续提高性能。其次,我提出了一组简单的图像数据集,可作为评估和比较图像分类方法在分布外泛化方面的垫脚石。最后,我深入研究了多个神经网络通信以解决共享任务的学习场景。这项工作以两种方式支持论文目标。首先,我提出了一个新的环境,图引用游戏(graph referential games),并在数据表示和相应的数据表示学习方法对分布外泛化的影响上提出了结果。这些结果连接了之前不相连的图表示学习和新兴通信领域。其次,我解决了基于现实图像的群体通信这一具有挑战性的领域。这篇论文中的数据集、算法、定理和实验结果代表了在机器学习中理解和改进分布外泛化方面的几个步骤。它们为研究人员提供了旨在促进这一领域研究的新工具和结果,其中一些已被证明对研究社群有用。最后,这项工作提出了机器学习的多个分布学习、图像分类和多代理通信子领域中重要的未来方向。
https://www.repository.cam.ac.uk/items/8680585b-87ca-4196-987f-c4d379259092
记忆与学习是否相同?阿根廷作家豪尔赫·路易斯·博尔赫斯(Jorge Luis Borges)的短篇小说《记忆者富内斯》(Funes the Memorious,由James E. Irby翻译成英文[71,第59–66页])描述了一个名叫富内斯的男孩,在头部受伤后获得了完美的记忆。他开始详细地记住他一生的每一个时刻。同时,他失去了泛化的能力:他的记忆彼此是孤立的。例如,他从不同的角度看到同一只狗,却只把同一只狗的不同侧面视为独立的信息。他甚至不了解自己的身体是什么样的(‘每次看到镜中的自己的脸,看到自己的手,都让他感到惊讶’),这导致了一个结论:‘思考就是忘记一个差异,进行泛化,进行抽象。在富内斯过于充实的世界里,只有细节。’""与富内斯相似,具有数百万参数的现代神经网络已被证明会记住训练样本,这可能导致一系列问题,例如:(1)对噪声数据的高度敏感性[150, 221],(2)易受对抗性攻击的影响[271, 87, 269, 287],(3)与人类学习相比样本效率低[302, 303, 275],以及(4)对新数据的泛化能力差[62],即使新数据样本直观地与模型已经训练过的数据有相似之处[61, 251]。这些问题可能出现在应用现代机器学习的任何领域。它们可能导致机器学习系统在使用过程中产生不透明的故障模式,从而导致对机器学习系统的信任度下降[297]。"
"标准机器学习方法中缺少对分布外泛化(Out-of-distribution generalisation)的能力。这些方法得到了统计学习理论[279]的支持,该理论证明了使用基于平均值的优化(经验风险最小化[279])以及使用测试集估计泛化误差的做法是合理的。然而,这一理论假设训练(过去)和测试(未来)数据是独立同分布的。在应用机器学习的许多实际领域中,这一假设是不正确的:现实世界的数据是异构的,其分布通常会随时间变化。分布变化的实际来源包括机器学习系统用户特性的变化,或一个有实体的代理(embodied agent)所处环境的变化。另一个常见的分布变化例子是由于语言(包括在线使用的语言)动态性而产生的。自然语言的不断演变已被证明会改变语言模型的困惑度(perplexity),当这些模型在数月内多次应用时[164]。背景章节的第2.4节更多地涵盖了分布变化的类型和相应的例子。由于这些变化,即使在常用的分布内测试集上达到接近100%的准确率也不总是能预示未来的性能,这一点已被众多论文所证明[137, 15, 61, 235, 204, 62]。"
"在机器学习领域,关于分布外泛化(OOD generalisation)的主题实质上与机器学习本身一样广泛和复杂,并且在研究社群中同样容易受到瞬息万变的趋势和不同观点的影响。在我看来,面对分布变化提高泛化能力是必要的,原因如下: • 工程原因 — 提高样本效率,并在没有数千个训练样本的低资源领域提高性能[110]; • 科学原因 — 深入了解神经网络是如何学习的,并可能让机器学习更接近人类学习; • 商业原因 — 在目前由人类执行的越来越复杂的任务中使用神经网络; • 社会原因 — 通过控制简单性偏见[246]来消除机器学习系统的偏见。
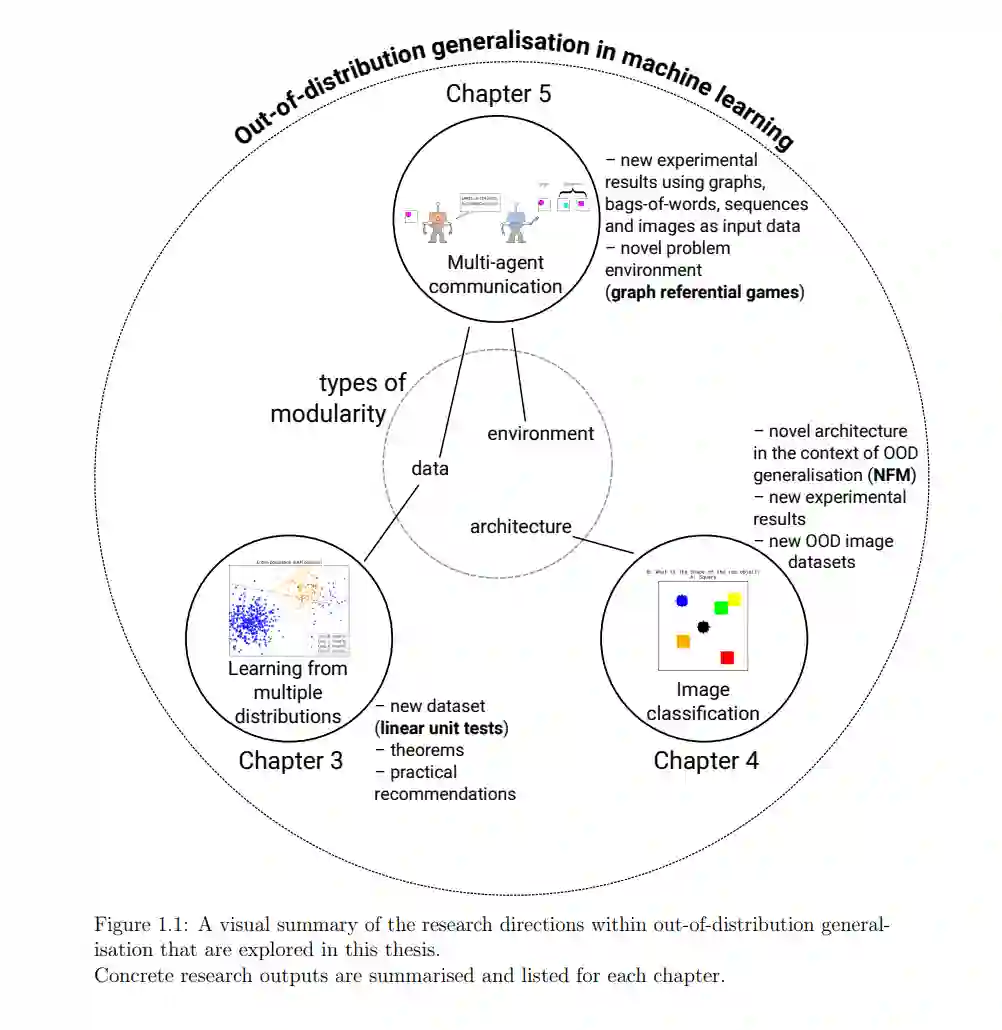
利用数据中的‘捷径’可能会导致不公平的解决方案(例如,这可以在招聘工具中利用性别信息时看到[59])。在我的博士研究期间,我一直在问自己:致力于分布外泛化的机器学习研究社群最需要什么样的工具?这篇论文旨在以新数据集、新理论结果、新测试平台、新实验结果和新算法的形式提供这样的工具。这些研究努力的具体成果总结在图1.1中。"
导致这篇论文的研究工作涉及机器学习的三个子领域:多分布学习(第3章)、图像分类(第4章)和多智能体通信(第5章)。这种广泛的视角使我能够收集更多证据来支持中心假设,并探讨研究问题(第1.2节)。同时,本论文中介绍的工具旨在对我在博士研究期间有幸与之合作和学习的几个机器学习社群有所用处:(1)不变学习和群体鲁棒性社群(第3章),(2)视觉社群(第4章),以及(3)新兴通信社群(第5章)。所有这些社群都在独立地研究机器学习中的分布外泛化,正如我在背景章节(第2章)以及各自贡献章节中所回顾的。本论文联系了我在研究中涉足的之前是分离的社群,例如图神经网络[141]与新兴通信[43](第5章),以及面向群体鲁棒性的数据导向方法[36]与分布鲁棒优化[21](第3章)。"