

利用有限的数据进行学习是深度学习的最大问题之一。目前,解决这个问题的流行方法是在大量数据上训练模型,无论是否标记,然后在同一模态的感兴趣的较小数据集上重新训练模型。直观地说,这种技术允许模型首先学习某种数据(如图像)的一般表示。然后,学习这种特定模态的特定任务应该需要更少的数据。虽然这种被称为“迁移学习”的方法在计算机视觉或自然语言处理等领域非常有效,但它不能解决深度学习的常见问题,如模型可解释性或对数据的总体需求。本文探索了在数据约束设置中学习表达模型问题的不同答案。我们不再依赖大数据集来学习神经网络的参数,而是用反映数据结构的已知函数来代替其中的一些参数。这些函数通常都是从内核方法的丰富文献中提取出来的。实际上,许多核函数都可以解释,并且/或允许使用少量数据进行学习。所提出方法属于"归纳偏差"的范畴,可以定义为对手头数据的假设,限制了学习过程中模型探索的空间。在本文的前两章中,我们在序列(如自然语言中的句子或蛋白质序列)和图(如分子)的上下文中证明了该方法的有效性。本文还强调了工作与深度学习最新进展之间的关系。本文的最后一章重点研究凸机器学习模型。这里,我们不是提出新的模型,而是想知道学习一个“好的”模型真正需要数据集中的哪些样本比例。更准确地说,研究了安全样本筛选的问题,即在拟合机器学习模型之前,执行简单测试以丢弃数据集中没有信息的样本,而不影响最优模型。此类技术可用于压缩数据集或挖掘稀有样本。

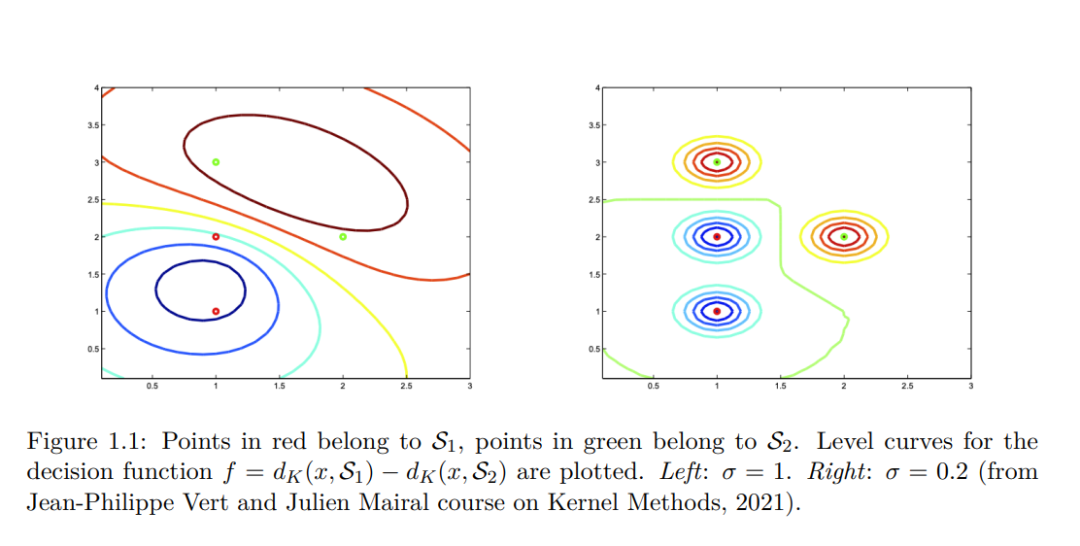
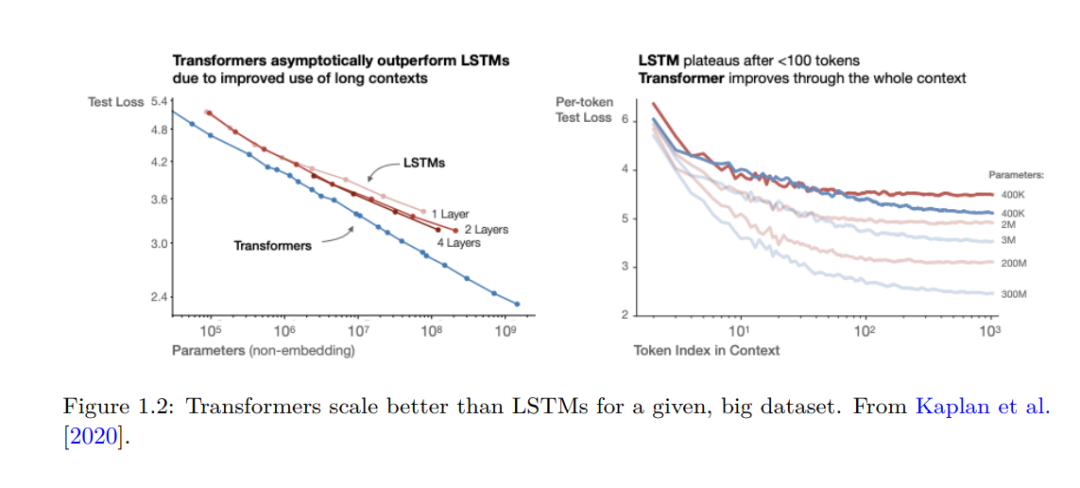
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年4月7日
Arxiv
12+阅读 · 2021年10月4日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年4月7日
Arxiv
12+阅读 · 2021年10月4日