

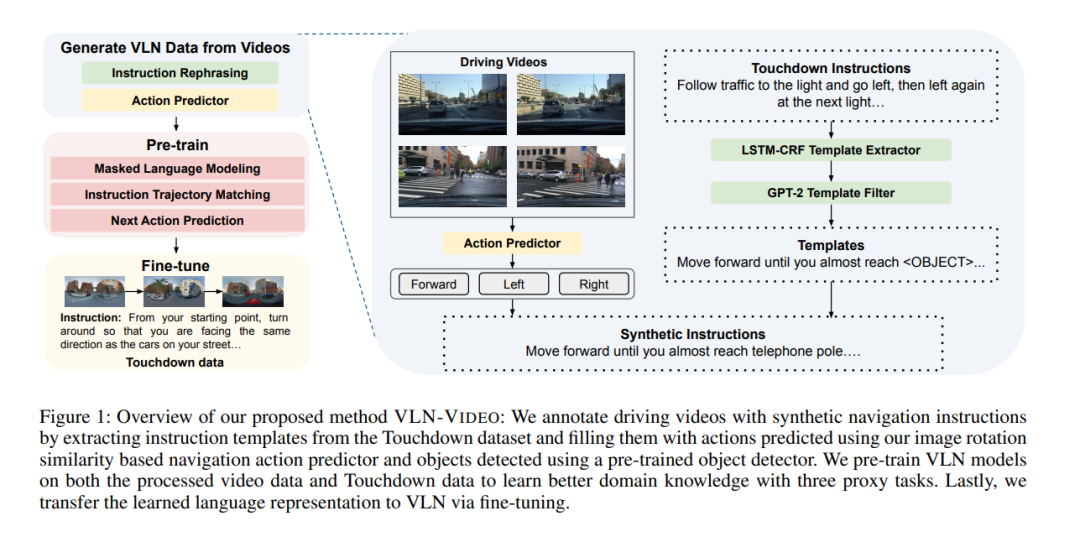
户外视觉语言导航(VLN)要求一个智能体基于自然语言指令,在真实的3D户外环境中进行导航。现有的VLN方法性能受限于导航环境的多样性不足和训练数据有限。为了解决这些问题,我们提出了VLN-VIDEO,它利用了美国多个城市驾驶视频中存在的多样化户外环境,并增强了自动生成的导航指令和行动,以提高户外VLN的性能。VLN-VIDEO结合了直观的经典方法和现代深度学习技术的最佳特性,使用模板填充来生成基于地面的导航指令,结合基于图像旋转相似性的导航行为预测器,从驾驶视频中获得VLN风格的数据,用于深度学习VLN模型的预训练。我们在Touchdown数据集及我们从驾驶视频中创建的视频增强数据集上预训练模型,通过三个代理任务进行预训练:掩码语言建模、指令与轨迹匹配以及下一步行动预测,以此学习时序感知和视觉对齐的指令表示。在微调Touchdown数据集时,将学到的指令表示适应到最先进的导航器中。实证结果表明,VLN-VIDEO在任务完成率上显著超过了之前的最先进模型2.1%,在Touchdown数据集上达到了新的最高水平。 https://www.zhuanzhi.ai/paper/65d220be694f2bda68254ad8fe413cd5
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日