Sonalysts 正在开展一项计划,通过开发该领域的原创性研究,将我们目前在团队合作方面的专业知识扩展到人类-人工智能(AI)团队。为了给这项研究奠定基础,Sonalysts 正在调查合成任务环境 (STE) 的开发情况。在上一份报告中,我们记录了最近一次外联工作的结果,在这次外联工作中,我们请军方主题专家(SME)和人类-人工智能团队领域的其他研究人员确定他们最看重的测试平台的品质。这次外联活动的一个惊人发现是,一些受访者建议我们的团队研究现有的人类-人工智能协同测试平台,而不是创建新的测试平台。根据这一建议,我们对相关情况进行了系统调查。在本报告中,我们将介绍调查的结果。在调查结果的基础上,我们制定了测试平台评估标准,确定了潜在的测试平台,并对候选测试平台进行了定性和定量评估。在评估过程中,我们提出了五个候选测试平台供研究团队考虑。在接下来的几个月中,我们将评估各种备选方案的可行性,并开始执行我们的研究计划。
背景
美国国家科学、工程和数学研究院(National Academies of Sciences, Engineering, and Mathematics)为空军研究实验室(Air Force Research Laboratory,AFRL)编写的一份共识报告记录了各军种对支持人类-人工智能团队合作的普遍和日益增长的愿望(NASEM,2021 年)。Sonalysts 已经开始了一项内部计划,探索如何最大限度地提高人类-人工智能团队的性能。为了给我们的研究奠定基础,Sonalysts 正在探索可作为测试平台的合成任务环境 (STE) 选项。
基于最近对主题专家(SMEs;McCarthy & Asiala,2023a)和人类-人工智能团队领域研究人员(McCarthy & Asiala,2023b)的调查结果,我们将在本报告中探讨我们将重点关注的测试平台质量,确定潜在的 STE,并对候选 STE 进行定量比较。
理想试验台的特征
在本节中,我们将概述研究人员在选择 STE 时可能需要考虑的一系列特性,并确定我们的计划将重点关注的特性。首先,我们将介绍研究人员可用于组织各种测试平台的概念分类法,然后探讨可能需要的特定 STE 功能。最后,我们将简要讨论我们将重点支持该计划的科技教育维度和特征。
2.1 试验台分类法
通过与该领域的多位研究人员讨论(例如,M. Steinberg,2023 年),我们创建了图 1 所示的 STE 分类法。在该分类法的概念中,维度包括团队成员(人类和智能体)之间的相互依赖程度、测试平台内任务的相关性以及填充测试平台的智能体的复杂性。
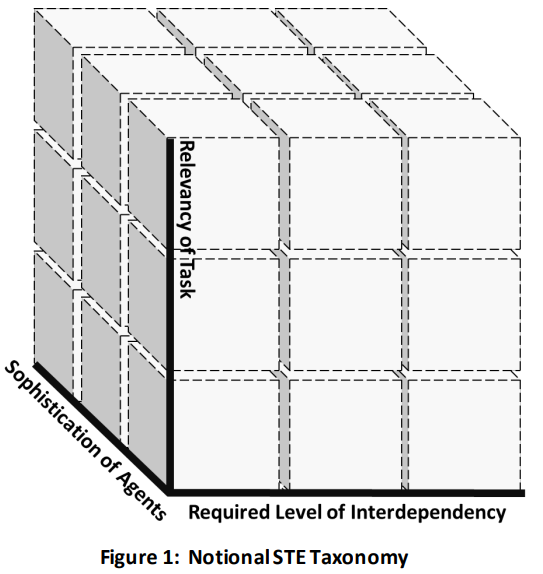
其中,相互依赖程度可能是最重要的维度。相互依赖程度反映了团队成员在完成集体任务时对他人的依赖程度。幸运的是,我们可以通过早期的研究来操作这一维度。首先,请看 Saavedra、Early 和 Van Dyne(1993 年)的研究。在以商业为重点的 "小组工作 "领域,这些研究人员引用了汤普森(1967 年)和范德文等人(1976 年)的早期研究成果,讨论了图 2 所示的相互依赖范围。在一个极端(集合工作流)中,几乎不存在相互依赖关系;每个人都独立完成分配的任务,"团队产品 "是个人努力的总和(例如,某个呼叫中心的工作人员)。在顺序工作流程中,个人负责生产自己的工作产品,并将其交给下一个团队成员进一步处理(即典型的 "流水线 "流程)。在这种配置中,信息、资源、工作成果等都是单向流动的。其余两种情况的相互依赖程度更高。在互惠模式中,"相邻 "工人之间存在双向流动。与顺序模式中的单向流动相比,这种 "取与舍 "需要更高水平的协调与合作。最后,在团队模式中,信息、资源、工作成果等是多向共享的。团队中的每个成员都可以与团队中的任何其他成员一起参与 "取与舍"(另见,Singh, Sonenber, & Miller, 2017)。
2.2 理想特征
在开发主题专家和研究人员调查问卷之前,Sonalysts 进行了相当广泛的文献综述。结合我们在一系列建模和仿真工作中积累的经验,我们预测出了一系列我们认为可能有用的任务领域特征。在调查中,我们要求受访者指出他们在多大程度上同意或不同意我们的假设,即哪些具体特征在 STE 中会很重要。我们还通过开放式问题对李克特项目进行了补充,使调查对象能够就 STE 中可能有用的其他功能提出建议。
为了支持这项工作,研究小组重新审视了调查结果,以确定我们可以用来描述和区分候选环境的特征。我们首先将研究人员的调查回复作为确定试验台特征的基础。在对调查回复进行初步分析期间,我们对开放式问题的回复进行了专题分析。我们的目标是识别所有答案中重复出现的观点,而不管受访者使用了什么术语或措辞。我们将主题分析结果合并成一份针对每个问题的主题共识列表,然后由研究团队将各个回复与列表中的条目进行映射。为了创建 STE 特征主列表,我们将共识列表中的条目与假设的特征相结合,假设的特征以李克特(Likert)风格的条目形式呈现,以获得一致评分。这一分析得出了 289 个条目。
然后,我们将候选特征排序为上位特征描述。我们这样做是为了识别和解释开放式问题回答中提到的特征与李克特式问题中的特征之间的重叠。例如,有一个李克特式问题要求参与者对 "STE 应作为'开源'工具实施 "这句话的同意程度进行评分。除了普遍同意这一条外,还有六位受访者在回答调查中的其他问题时提到 STE 应具有 "开源架构"。我们将这些条目归入了 "STE 应该是'开源'的 "这一上位特征类别。
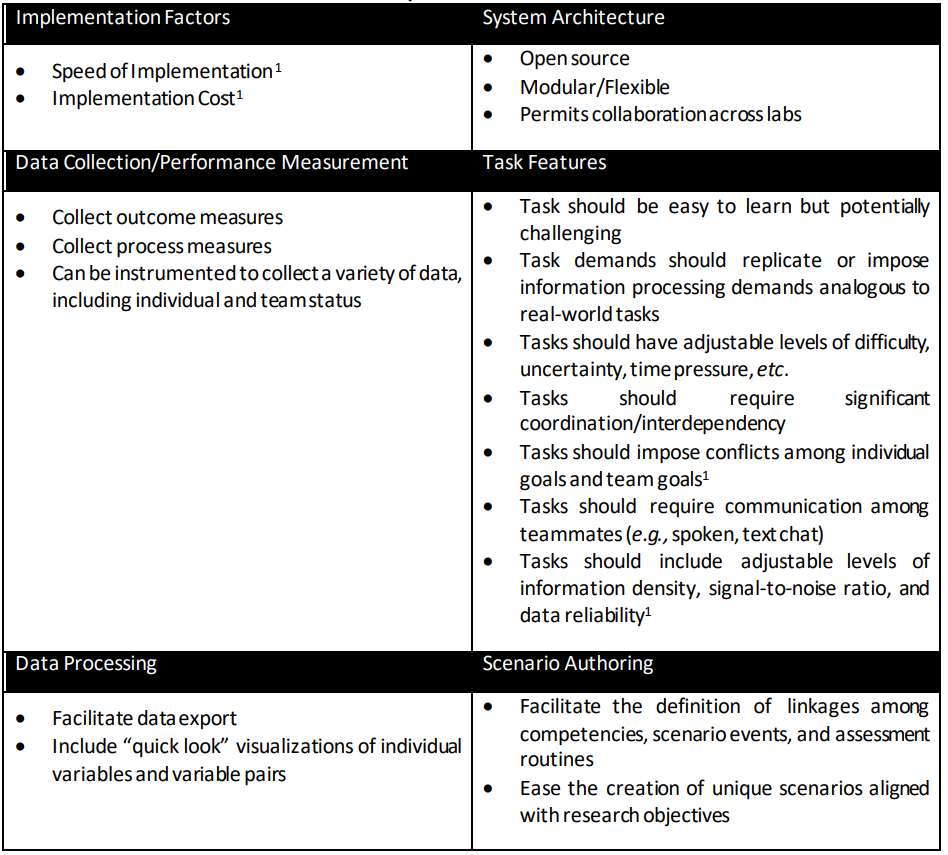
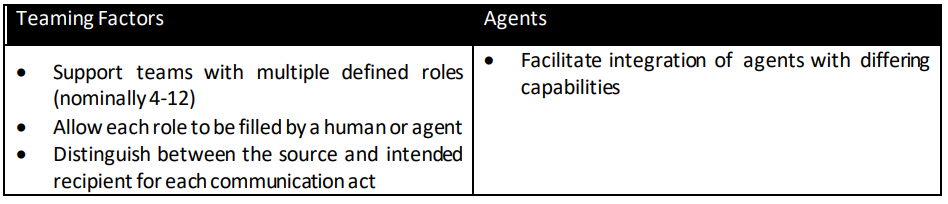
上位特征分类过程产生了一百多个上位特征类别。为了创建一个更合理的特征集,我们删除了开放式回答和李克特风格项目合并少于三个的类别,并合并了几个概念高度重合的类别。这样,特征列表就缩小到了 23 个。由于用于评估和比较测试平台的单个标准仍有 23 个之多,因此我们进一步将上位类别合并为表 1 中列出的八大标准。与每项标准相关的小标题反映了相关的细粒度特征。我们将在第 4 节介绍这些标准对测试平台量化评估工具的贡献。
表 1:重要的 STE 特征