面部表情识别(FER)旨在从静态图像和动态序列中分析情感状态,这在利用AI技术增强人类、机器人和数字化身之间的拟人化交流中起着关键作用。随着FER领域从受控实验室环境向更加复杂的现实场景发展,先进的方法迅速涌现,并且遇到了现有FER综述中尚未充分解决的新挑战和新方法。本文对基于图像的静态FER(SFER)和基于视频的动态FER(DFER)方法进行了全面综述,分析了从模型导向的发展到以挑战为中心的分类。我们首先对近期的综述进行批判性比较,介绍了常见的数据集和评估标准,并深入探讨了FER的工作流程,以建立坚实的研究基础。接下来,我们系统地回顾了应对SFER八大主要挑战(如表情干扰、不确定性、复合情感和跨领域不一致性)以及DFER七大主要挑战(如关键帧采样、表情强度变化和跨模态对齐)的代表性方法。此外,我们还分析了近期的进展、基准性能、主要应用及伦理考量。最后,我们提出了五个有前景的未来方向和发展趋势,以指导正在进行的研究。本文的项目页面可在https://github.com/wangyanckxx/SurveyFER上找到。
关键词——情感计算、面部表情识别、静态与动态情感、挑战与进展。
1 引言
情感计算[1]在关键国家领域中具有深远的影响和重要性。英国的创新机构Innovate UK将“人工智能(AI)情感与表情识别”列为2024年对英国经济和社会产生深远影响的50项新兴技术中的首位。中国科学技术协会隆重发布了2024年的重大科学问题,其中情感与情感智能数字人和机器人的研究被选为十大前沿科学问题之一[2]。显然,AI情感与表情识别技术的发展已经成为通用AI、数字计算和多学科研究的必然要求[3]。面部表情[4]是人类情感表达的主要和直接手段,在人际互动中经常使用并具有极其重要的意义。与其他形式的信息如声音、手势和身体姿势相比,面部表情以非语言的方式传达了更丰富的情感信息[5]。面部情感的概念最早由达尔文在其著作《人类和动物的表情》一书(1872年)中提出。他指出,表情在本质上是先天的,是动物和人类在进化和生存过程中适应性运动的遗留物。Ekman和Friesen[6]提出了六种基本情感:快乐、愤怒、悲伤、惊讶、恐惧和厌恶,并发现特定的面部肌肉模式与情感类型之间存在跨文化的一致性。近年来,随着AI技术的发展,面部情感识别(FER)方法迅速发展,并在心理研究[7]、医学诊断[8]和智能人机交互[9]中得到了广泛应用。
FER旨在通过分析面部表情识别个体的情感状态[10]。根据捕捉表情的数据类型,FER可以分为两部分:基于图像的静态FER(SFER)[11]和基于视频的动态FER(DFER)[12]。SFER致力于解决姿态遮挡、跨领域不一致、标签不确定性、数据量不足和跨模态问题等挑战。研究人员还采用各种数据增强技术和正则化方法来缓解数据量不足和标签不确定性的问题。此外,通过跨模态信息融合,提高了表情识别的鲁棒性和准确性。SFER关注瞬时表情,而DFER则专注于面部表情的时间变化,以准确描述和理解情感变化的整个过程。处理视频序列中的表情识别,DFER的主要挑战在于关键帧提取、时空特征提取、表情强度变化和跨模态融合。为了捕捉动态表情信息,DFER模型不仅关注单帧中的静态特征,还结合了连续帧之间的时间关系。
1.1 分类概述
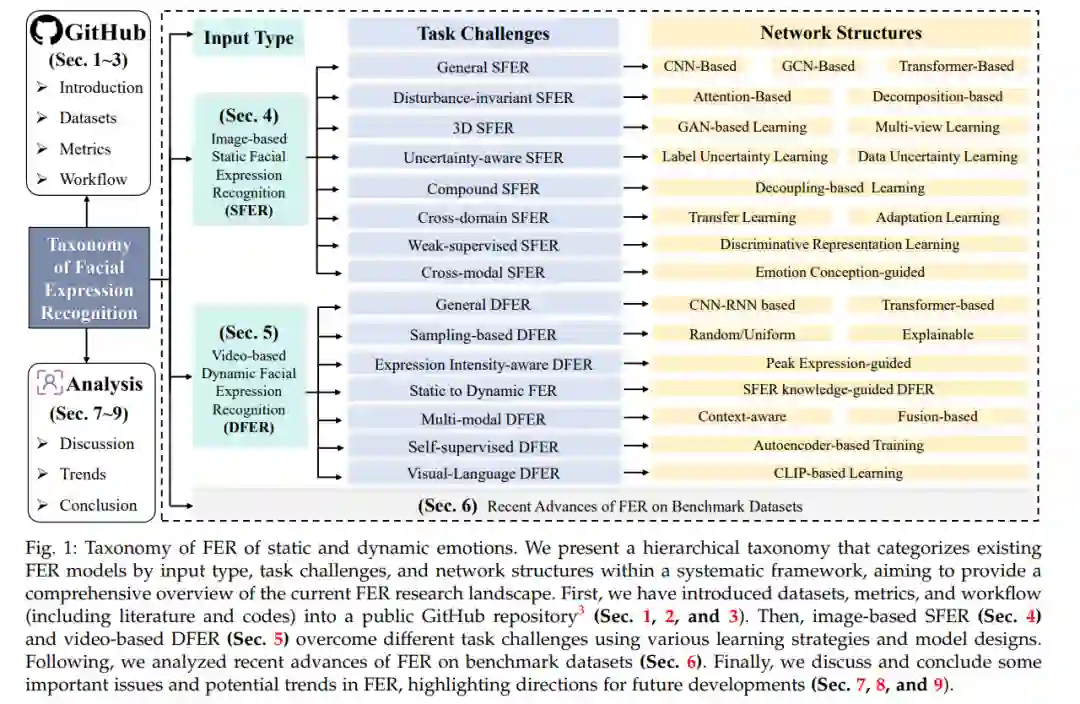
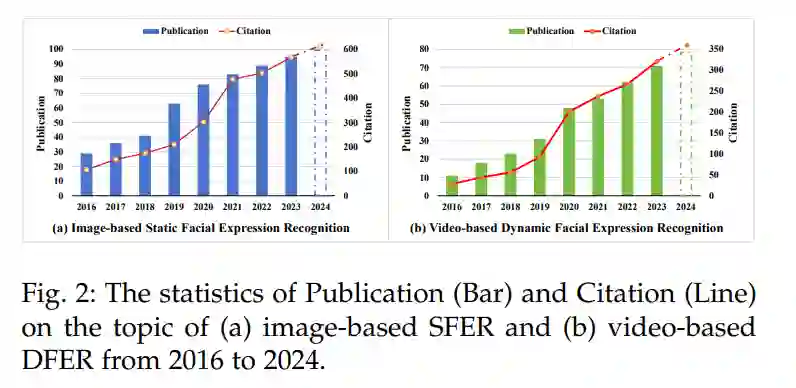
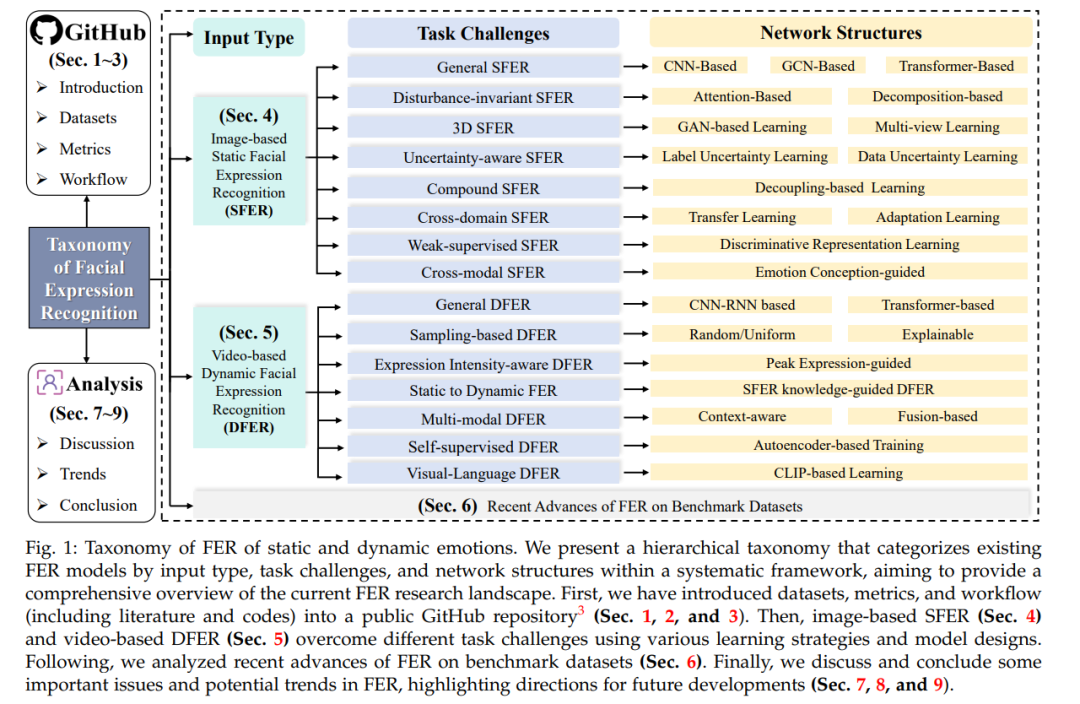
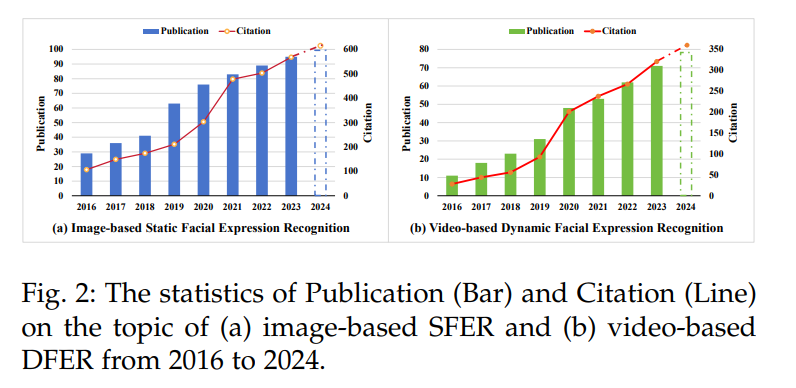
在本文中,我们系统地总结了当前FER研究的现状,并提供了一个分层分类体系来组织现有的FER工作,按照输入类型(基于图像的SFER和基于视频的DFER)、任务挑战和网络结构进行分类,如图1所示。对于SFER,我们识别了八个关键挑战,如干扰、不确定性、复合标签、跨领域适应性和跨模态问题,并总结了现有方法中常用于解决相应挑战的模型结构。对于DFER,我们则纳入了七个额外的考量,如关键帧提取、表情强度变化、静态到动态一致性、半监督学习和跨领域对齐,以及现有方法的解决方案。我们进一步分析和讨论了典型审查方法在基准数据集上的最新进展。此外,我们还总结了基准数据集、评估指标、文献、代码、工作流程和讨论,放在了GitHub仓库中。为了开发这个分类体系,我们广泛回顾了从2016年到2024年大量的研究论文。图2追踪了2016年至2024年与基于图像的SFER和基于视频的DFER相关的出版物和引用趋势。自2019年左右开始,出版物和引用的数量显著增加,并持续上升至2023年,并预计在2024年继续增长。这反映了对SFER和DFER领域日益增长的兴趣和进展。
1.2 相关综述
在过去五年中,一些综述[13]、[14]、[15]、[16]覆盖了FER的工作,并生成了各种分类系统。为了突出我们综述的独特贡献,我们与几篇现有的重要综述进行了比较,并在表1中总结了它们。综述研究[13]、[14]、[15]主要介绍和分析了从实验室控制环境到现实环境的各种基于深度学习的FER技术。我们的综述不仅深入分析了FER系统的标准流程和实际部署中的挑战,如姿态遮挡、跨领域不一致和标签不确定性,还讨论了基于图像的SFER和基于视频的DFER中的不同方法和技术进展,提供了更全面的视角。[16]主要关注视觉情感识别中的最流行技术和当前趋势。然而,我们的工作进一步细化了对单一模态(面部表情)的研究,深入探讨了静态和动态FER的最新方法和技术挑战。近期的FER综述工作[17]、[18]、[19]、[20]主要关注3D FER、基于图的或多视角的面部表情分析,并讨论了FER数据集中的人口统计偏差。我们的综述涵盖了更广泛的深度学习技术,不限于图方法和多视角问题,还进一步涵盖了跨领域学习、跨模态融合和自监督学习的最新进展。[21]主要关注通过面部表情在教育环境中检测疼痛或情感模仿的应用。我们的综述涵盖了FER在不同领域的更多应用场景和潜力,同时讨论了技术和伦理问题。

1.3 贡献总结
为了澄清FER的发展并激发未来的研究,本综述涵盖了研究背景、数据集、通用工作流程、任务挑战、方法、性能评估、应用、伦理问题和发展趋势。总结来说,本工作的主要贡献如下: 据我们所知,这是首个将FER研究分为基于图像的SFER和基于视频的DFER的全面综述,从模型导向的发展扩展到挑战导向的分类,并对现实中的挑战和解决方案进行了深入分析。 我们系统地回顾了SFER中针对八大主要挑战(如表情干扰、不确定性、跨领域不一致)和DFER中针对七大主要挑战(如关键帧提取、表情强度变化、跨模态对齐)的最新代表性方法。 我们总结、分析并讨论了在实验室环境中的FER、现实环境中的SFER和现实环境中的DFER的多样化基准数据集上的最新进展和技术挑战。 本综述总结了三大领域应用和伦理问题,并讨论了发展趋势(如零样本FER和具体现代表情生成),旨在提供FER系统的新视角和指导。