
混合专家模型在大模型微调领域进展
前言:随着大规模语言模型(LLM)的快速发展,人工智能在自然语言处理领域取得了巨大的进步。在将大模型转化为实际生产力时,不免需要针对实际的任务对大模型进行微调。然而,随着模型规模的增长,微调这些模型的成本也大幅增加。因此,高效微调技术(PEFT)逐渐成为提升部署模型性能的关键手段。专家混合(MoE)技术通过动态激活大模型的部分参数,极大地减少了计算资源的消耗,在不显著增加推理和训练时间的情况下,大幅提升了模型的参数量,提升了模型的灵活性和性能。最近一年来,有一些工作将MoE技术和PEFT技术相结合,以期望复现MoE技术在预训练LLM时的优异表现。本文将探讨MoE在LLM微调中的应用,展示其在提升效率和性能方面的独特优势。
1 背景
1.1 大模型高效微调技术
大模型高效微调技术(LLM-PEFT)旨在在不修改模型全部参数的前提下,通过调整少量参数来实现模型的高效微调。由于LLM往往包含数十亿甚至上千亿参数,直接微调整个模型的计算成本极高且资源消耗巨大。PEFT通过引入诸如冻结大部分参数、仅微调特定层或模块等方法,有效降低了训练成本。常见的PEFT方法包括微调低秩矩阵(LoRA)、适应性前馈网络(Adapter)等技术,它们可以在保证模型性能的同时大幅减少计算和存储资源的需求。
1.2 混合专家技术
专家混合(MoE, Mixture of Experts)是一种用于提升模型计算效率的技术,通过动态路由机制,MoE模型只激活部分专家网络,而非让所有参数同时参与计算。每个“专家”是一个独立的子模型,模型在不同输入时有选择性地调用最适合的专家,从而减少计算负担。相比全参数激活的传统密集模型,MoE一般为稀疏模型,能够在保持模型规模和性能的同时,大幅减少计算资源消耗,尤其适合大规模语言模型的训练与推理。MoE的这种灵活性使其在处理复杂、多样化的任务时具备显著优势。
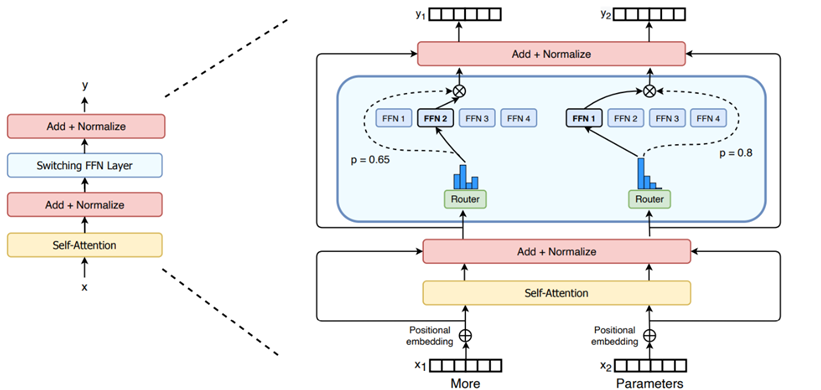
如上图所示,近些年来,有一些工作将MoE思想引入LLM中,将Transformer架构中的FFN模块作为专家网络组成MoE网络,在每一个Transformer子层中都以MoE层来替换FFN层。具体来说,MoE层通常由一个线性层(Linear Layer) 作为门函数(gate function),负责输出一个指导向量。指导向量的长度等于专家数量,其上每个值代表着对应专家的得分。我们选出得分最高的个值(Top-K)对应的专家进行激活,即将输入路由给这个专家。最后将个专家的输出按照先前的得分进行线性组合,得到MoE层的输出。 这种架构相比原始的Transformer架构,大量增加了可训练参数量,同时不显著增加训练及推理时间,成为了现在主流的大模型架构。
1.3 混合专家微调技术
随着微调技术的重要性逐渐显现,有人将MoE思想引入到大模型微调领域,以增强大模型的微调效果。
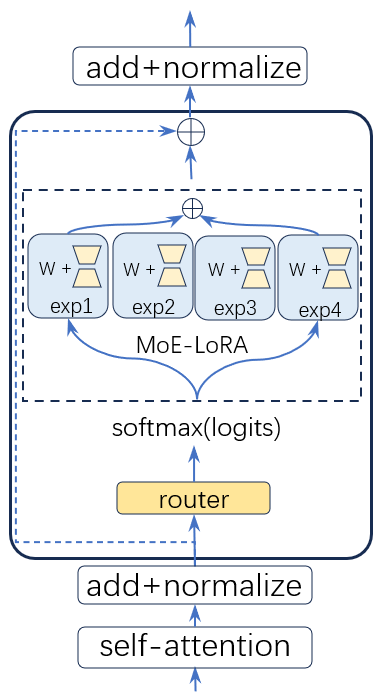
MoE微调方案与MoE大模型架构非常相似,同样是用MoE层替换FFN层。其中MoE-LoRA层对应于MoE大模型架构中的MoE层,将MoE层中的FFN专家替换为LoRA专家。为了保留大模型预训练参数,再将MoE层的输出加在预训练FFN模块的权重 上。如上图所示,近期也有工作认为,应该让每个LoRA专家共享预训练FFN模块的权重,这样可以获得更好的效果。
2 MoE微调技术的意义
在当今的大模型应用场景中,预训练微调体系依然是主流路线之一。因此,如何提高微调性能,就成为了十分重要的任务。MoE的本质,就是在一个共享的base上产生若干个专家分支,这些专家分支之间被严格的分隔,以形成不同的特征域。接下来本文将根据MoE的特性,介绍MoE对于微调技术的意义。
2.1 多模态及多任务学习
多模态任务是一类天然适合MoE来完成的任务。普通的LoRA技术,在面对多模态任务时,因为需要将多模态输入模块的,来自多个特征空间的数据进行对齐,因此会出现模型很难收敛的现象。针对这一难题,LLaVA-MoLE[1]给出了一种解决方案,引入MoE技术,用简单高效的方法一定程度上缓解了多模态任务难收敛的问题。MoCLE[2]也在视觉语言模型(VLM)问题上引入了MoE来缓解多模态数据对齐的难题。
2.2 提高参数规模
普通的微调中,对于LoRA秩的选择并不需要太大,因为并不是秩越大越好。换句话说,LoRA并不符合缩放定律(scaling law)。而MoE技术,为实现缩放定律带来了希望的曙光。因为MoE可以在不明显增加训练、推理时延的情况下大量扩张参数量,因此MoE技术带来的大量相互分隔的可训练参数,带来了参数量的提升,同时也在实验中被证明,是一种能提高微调后模型效果的方案。
2.3 解决灾难性遗忘问题
灾难性遗忘问题指的是模型在微调某一任务时可能会丢失之前学到的知识。MoE通过专家模块化的设计,可以让不同任务使用不同的专家,从而减轻灾难性遗忘的风险。例如,在微调过程中,可以为新任务引入新的专家模块,而保留原有的专家来处理旧任务。这样既能保持旧任务的性能,又能有效适应新任务。
3 MoE微调技术的挑战
3.1 MoE微调技术面临的问题
MoE微调模型面临着许多挑战,主要包括:模型收敛问题,模型稳定性问题和路由不均衡问题。 因为MoE微调模型,相比于LoRA模型,具有更复杂的专家、路由器协同训练,因此相对来说更难以收敛,同时收敛速度也会慢一些。由于线性层的简洁性,因此大部分MoE微调模型实际上需要在路由模块计算时,需要将计算精度提升到FP32,才能保证MoE微调模型的有效性。这是MoE微调模型的不稳定性导致的。MoE微调技术还继承了MoE技术所面临的另一个挑战:路由不均衡问题,并且在微调时,不均衡现象更甚。路由不均衡问题是指,路由模块总是激活若干个专家,而有些专家几乎不会被激活。这会导致参数的浪费,与我们增加参数量的初衷相悖。
3.2 MoE微调技术创新性上的挑战
MoE架构拆开来看,除了超参数上的调整,实际上只有两个地方是具有极大创新空间的:路由模块(Router Module)和损失函数(Loss Function)。 当前所有的MoE模型,都是针对超参数和损失函数来进行创新的。由此可以看出,对路由模块的创新是极具难度的。当前所有MoE模型的路由模块均由一个简单的线性层构成。作为从隐藏层空间映射到指导向量空间的重要模块,人们对其的创新大多无效,因此鲜有文章对路由模块进行创新。因此,人们普遍期望通过优化损失函数的方法,来解决上述挑战。 当前人们对MoE模型的创新性研究主要集中于损失函数上。因此,人们提出了多种损失函数,来尝试使其路由达到均衡的状态,以此来达成理论分析中,各个专家各司其职的效果。但各种新颖的损失函数虽然对模型效果略有提升,但并没有,也或许不需要使路由模块的路由结果真正达到均衡的状态。
3.3 MoE微调技术的损失函数
因为上述原因,人们在损失函数上的创新相比其他地方是百花齐放的。首先是路由均衡问题, OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER[3]提出了重要性损失(Importance Loss): 其中为门函数(Gate Function),也就是路由模块内的线性层;代表着异变系数(Coefficient of Variation);是一个超参数。重要性损失定义了专家重要性这一重要概念,以各个专家的得分为自变量,得到了一个收敛时会让专家保持平衡的损失函数。这是一个相对古老是平衡损失函数。在与接下来的损失函数做对比时,即可看出该损失函数的劣势所在。 另一篇文章Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity[4]中提出了辅助损失函数(Auxiliary Loss): 其中为超参数,N代表专家数量,B代表批量数,代表着专家所被分配的输入中,被分配权重最大为多少。所以代表着分配给专家i的令牌部分,可以被视为分配给专家i的令牌的数量,代表着分配给专家i部分的令牌的权重之和。由此可以看出,辅助损失函数综合考虑了专家被分配到的“重要性”,以及专家被激活的次数。尽管这个被激活次数并不是真的被激活次数的统计量,但是这里表现出了作者对路由均衡函数的思考:即需要综合考量专家的重要性以及被激活次数。这也是这个函数至今仍被广泛应用的原因之一。 除了辅助损失函数以外,还有一些只取等,只考虑专家重要性或者被激活次数作为损失函数的方法,但这些方法均没有被证明优于辅助损失函数。 针对模型不稳定的问题,ST-MOE: DESIGNING STABLE AND TRANSFERABLE SPARSE EXPERT MODELS[5]提出了: 其中B是批次(batch)中的令牌(token)数量,N是专家的数量,是门函数的输出。通过惩罚大权重,来使模型更稳定。这个损失作为一个古老的损失函数,现在也很少有人使用了。 近期还有工作提出了对比损失函数的思想,该思想认为专家之间应当相互对立,区别越大越好。因此,损失函数的设计逻辑为:对于当前令牌,被分配的K个专家之间的相似度应该更大,而这些专家与其他专家之间的相似度应该更低。
4 MoE微调技术展望
MoE微调技术如今还是一个非常年轻的技术路线,在理论上拥有着极高的上限,并且基于MoE的预训练模型的成功也代表着MoE理论在大模型时代会被越来越多的研究,而这些关于MoE的研究经验也会促进所有MoE相关技术的发展。具体来说,关于路由模块的研究尚且不足,关于路由模块路由原理、以及创新还都处于起步阶段;关于损失函数的设计,虽然百花齐放,也有经受住时间考验是损失函数的存在,但是损失函数作为调控路由模块的关键函数,是否可以根据路由模块的原理、特性,进一步精心设计,解决MoE微调技术的现有挑战?
参考文献
[1] Chen, S., Jie, Z., & Ma, L. (2024). Llava-mole: Sparse mixture of lora experts for mitigating data conflicts in instruction finetuning mllms. arXiv preprint arXiv:2401.16160. [2] Gou, Y., Liu, Z., Chen, K., Hong, L., Xu, H., Li, A., ... & Zhang, Y. (2023). Mixture of cluster-conditional lora experts for vision-language instruction tuning. arXiv preprint arXiv:2312.12379. [3] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538. [4] Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120), 1-39. [5] Zoph, B., Bello, I., Kumar, S., Du, N., Huang, Y., Dean, J., ... & Fedus, W. (2022). St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906.
