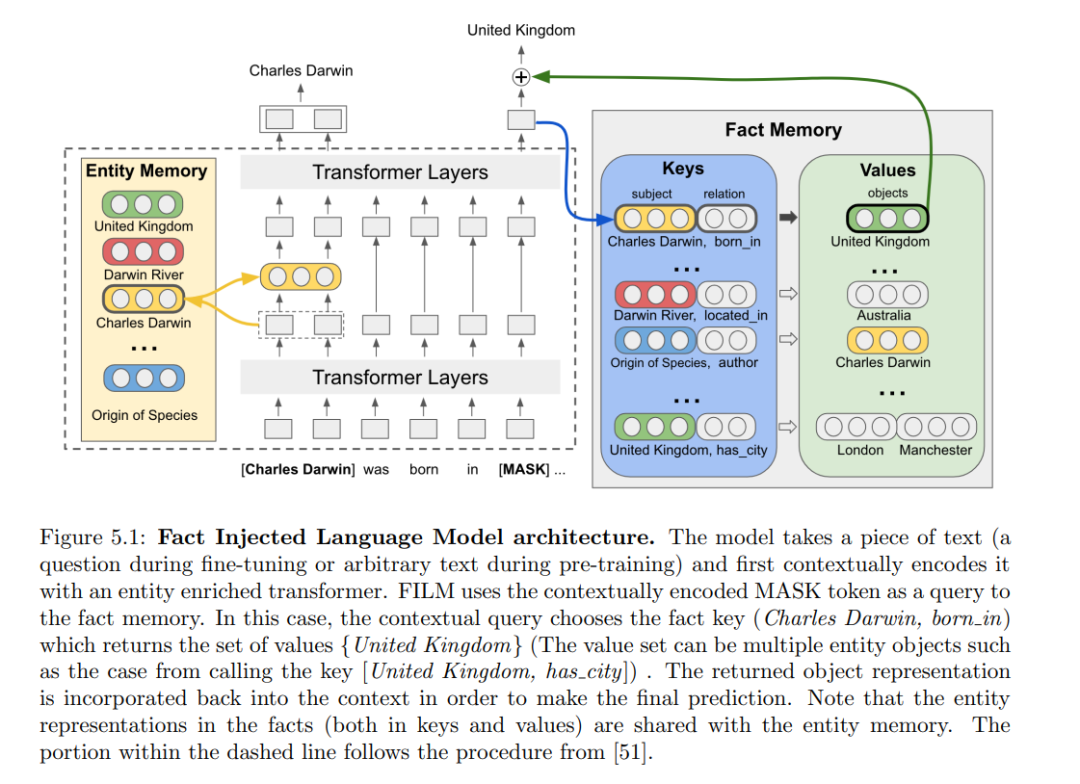
问题回答(QA)在自然语言处理(NLP)中是一个非常具有挑战性的任务,因为它需要理解问题,找到与问题相关的信息,并执行各种推理步骤以预测答案。人们每天提出的问题与许多类型的推理相关。在这篇论文中,我们讨论了在问题回答(QA)中处理具有挑战性的推理任务的几种方法。在问题回答(QA)中常见的推理任务包括单跳和多跳关系跟踪、交集和并集、否定和约束验证。在论文的第一部分,我们使用结构化或半结构化查询研究了在符号知识库(KBs)上的这些推理任务。我们首先提出了一种用于符号空间推理的神经查询语言,然后讨论了将其扩展到嵌入空间以实现更好泛化的可能性。由于符号KBs通常不完整,我们还提出了一种从文本构建虚拟KBs(VKBs)的方法,该方法支持大多数作为符号KBs的推理任务。由于大多数NLP系统都是基于语言模型(LMs)构建的,所以在论文的下一部分,我们提出了将推理方法整合到语言模型(LMs)中的方法,以提高LMs在执行更具挑战性的QA任务的推理步骤的能力。整合改进了LMs对事实知识的忠实性,也使得可以更新LMs学习的知识,以进行无需任何额外训练或微调的更新预测。这些提出的方法适用于符号KBs和虚拟KBs。然而,前面讨论的推理任务主要关注精确定义的问题,即存在单一正确答案的问题。
在论文的最后一部分,我们研究了带有模糊问题的QA任务,即从问题中缺少重要信息,根据问题的解释可能有多个答案。我们为这个任务开发了一个新的数据集,并展示了它对当前的QA系统的挑战。我们为新的数据集提出了改进的方法,该方法根据对回答问题的文档的分析,确定哪些条件可以消除问题的歧义。最后,我们考虑了这个任务的“开放”版本,即未提供答案文档。
构建理解自然语言的智能系统是自然语言处理(NLP)社区长期以来的目标。自然语言在日常生活中被用于交流和储存关于世界的知识。然而,由于词汇和语法的多样性以及自然语言中丰富的语义信息,开发理解自然语言的机器学习技术是具有挑战性的。完全理解自然语言可能还需要对文档的语义进行推理,或者对文档的问题进行推理。我们专注于NLP中的知识密集型任务,如信息检索(IR)和问题回答(QA),这些任务需要理解关于世界的事实知识。知识密集型任务测试NLP系统从大量知识中找到相关信息并据此进行预测的能力。例如,可以从维基百科的一段文字中找到“CMU的位置”的答案,例如“卡内基梅隆大学(CMU)是位于宾夕法尼亚州匹兹堡的一所私立研究型大学”。一些其他的查询可能需要多于一份的信息,例如“CMU附近的科技公司”,这需要首先找到CMU的位置,然后在同一个城市找到公司,再通过“科技”公司的限制进行筛选。我们将理解查询的意图,定位相关信息,并聚合多份信息来预测答案的能力称为“推理”。在知识密集型NLP任务中涉及到各种类型的推理程序。
在这篇论文中,我们考虑了在问题回答(QA)任务中常见的几种推理类型: 1. 关系追踪。关系追踪,如“CMU的部门”,是QA中最常见的问题类型。它从一个主题实体x开始,如“CMU”,然后跟踪一个关系r,如“有部门”,以找到答案。我们可以用一阶逻辑来写关系追踪问题,如Y = {y | has department(CMU, y)},其中has department(·, ·)是一个谓词,关系为“X的部门”和“CMU”是主题实体。Y是那些可以用提供或检索的信息来验证has department(CMU, y)的答案y的集合,如Y = {MLD, LTI, CSD, . . . }。 1. 多跳关系追踪。如果问题需要多于一步的推理,关系追踪可以被链接。例如,“CMU的部门授予的学位”需要找到CMU的学术部门,然后找到这些部门授予的学位,即Y = {y | ∃ z, has department(CMU, z) ∧ degree(z, y)},其中最终答案y ∈ Y取决于中间输出z。 1. 交集和并集。另外两种常见的推理类型是交集和并集,例如“有CMU或UPitt校区的城市”。为了回答这个问题,我们联合了CMU的位置和UPitt的位置,即Y = {y | locate(CMU, y) ∨ locate(UPitt, y)}。 1. 约束。有些问题需要满足一些指定约束的答案,例如“有CMU校区提供金融学位的城市”。我们通过约束过滤位置集合,即Y = {y | locate(CMU, y) ∧ filter(y, “finance degrees”)}。 1. 归纳推理。在归纳中,推理过程是根据一些预先确定的规则对一组观察结果进行解释。解释只得到了观察结果的部分支持,因此,它做出了一些假设。我们考虑在回答模糊问题的情境中的归纳推理任务,其中问题提供的信息(有时与提问的场景配对)被视为观察。由于问题是模糊的,即回答问题的重要信息缺失,规则只被部分满足。因此,可能有多个答案,有些答案在某些条件下才是正确的。我们说,给定提供的信息,可能的答案和它们的条件的组合是解释。
回答模糊问题的任务是找到一组关于用户意图的合理假设,以解决歧义,即如果将假设作为约束添加到问题中,问题将有唯一的答案。例如,如果我们假设“校园”意味着“主校园”,那么“CMU的校园”这个问题的答案就是“匹兹堡”。