
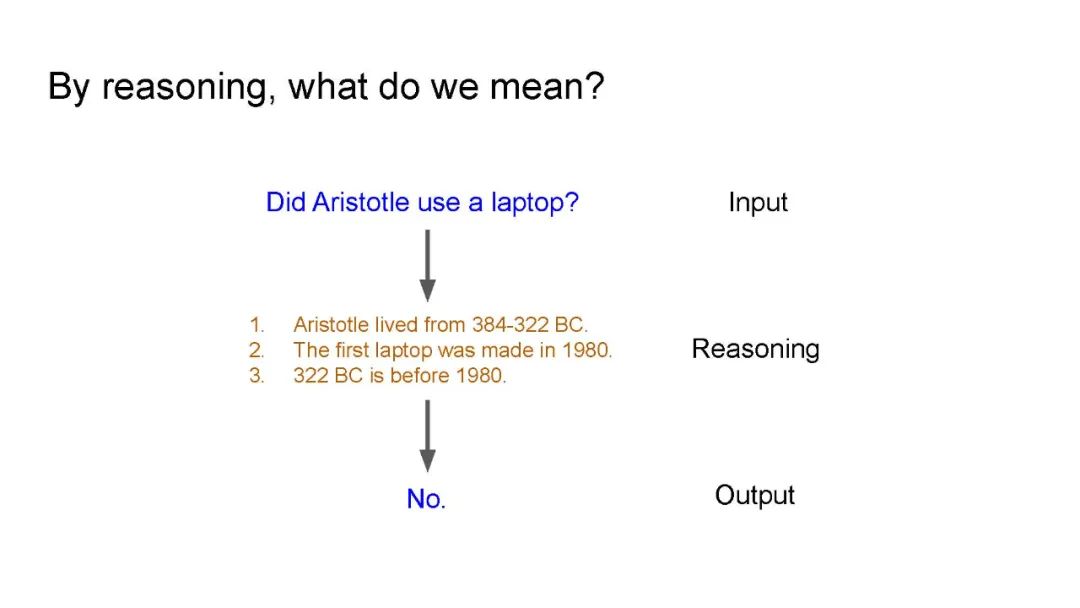
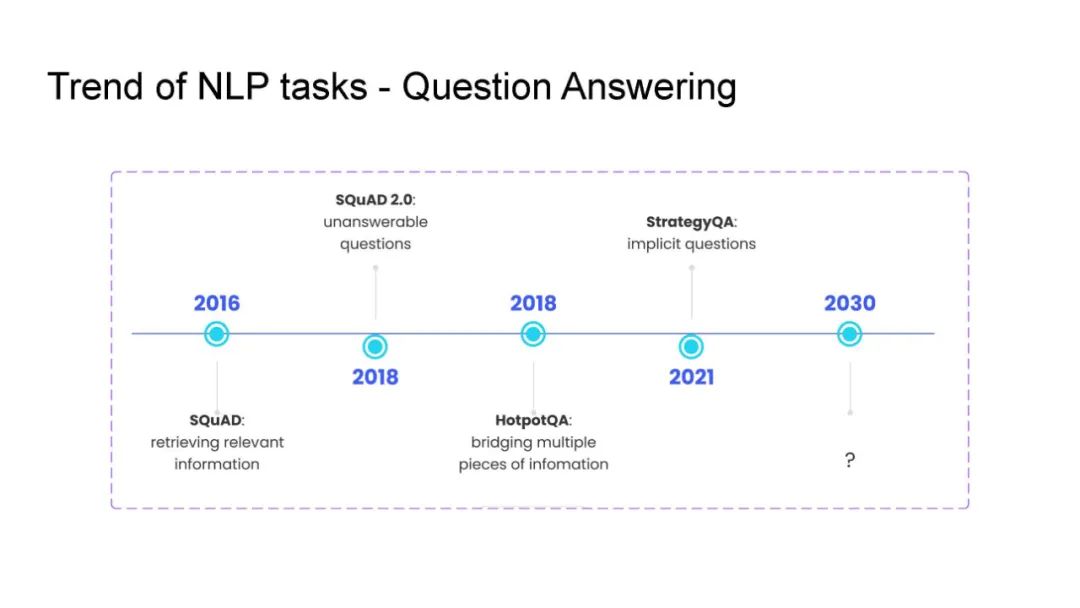
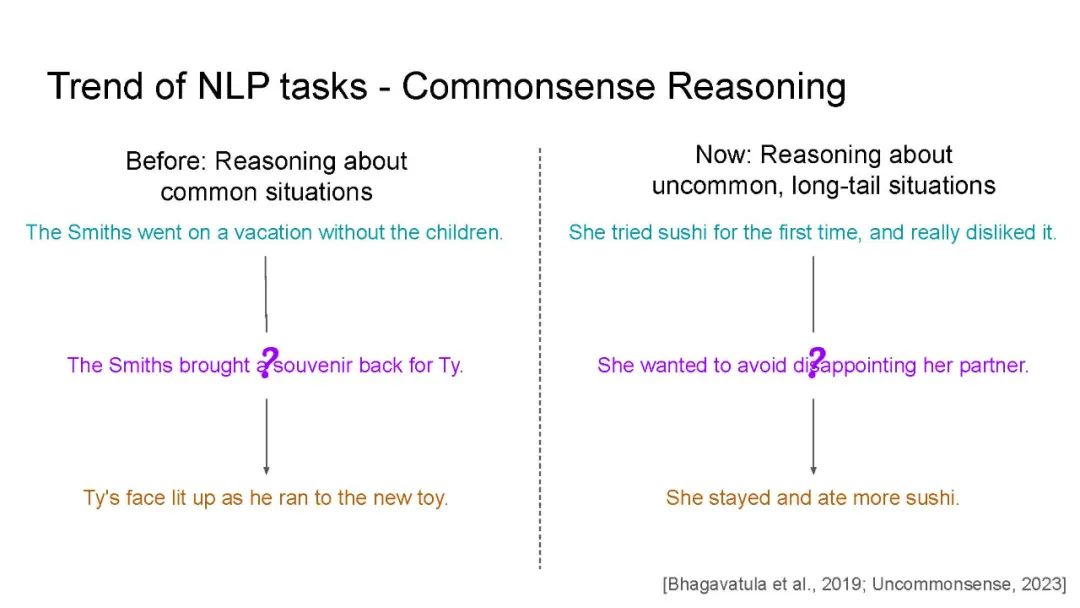
教导机器对文本进行推理一直是自然语言处理(NLP)的长期目标。为此,研究人员设计了一系列复杂的推理任务,涉及组合推理、知识检索、基础理解、常识推理等多个方面。
构建能执行所需类型推理的系统的标准选择是在特定下游任务上对语言模型(LM)进行微调或提示。然而,最近的研究表明,这种简单的方法往往容易出现问题,这些模型的推理能力仅限于表面层面,即仅仅利用数据模式。因此,通过技术手段增强LM的鲁棒性和有效性成为一个活跃的研究领域。
本教程概述了标准预训练语言模型在复杂推理任务中的失败之处。随后,本教程回顾了近期有前景的解决这些任务的方法。具体而言,我们关注以下几种明确考虑问题结构的方法:(1)知识增强方法,在微调或预训练过程中将知识加入模型;(2)少样本提示方法,有效地指导模型按照指令进行推理;(3)神经符号方法,生成明确的中间表示;以及(4)基于理由的方法,这是神经符号方法中最受欢迎的形式之一,用于将输入的子集作为对个体模型预测的解释。
通过探索这些不同方法,研究人员旨在克服标准微调和提示方法的局限性,开发出能够更有效地进行文本推理的模型。本教程概述了这些领域的当前研究现状,重点介绍了最新进展和未来研究的有前景的方向。

讲者:





成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日