Long-CoT 推理的发展显著提升了大型语言模型(LLMs)在多种任务中的表现,包括语言理解、复杂问题求解和代码生成。该范式使模型能够生成中间推理步骤,从而提升了准确性和可解释性。然而,尽管取得了这些进展,对于基于 CoT 的推理如何影响语言模型的可信性,仍缺乏系统性理解。本文综述了近期关于推理模型和 CoT 技术的研究,重点围绕可信推理的五个核心维度:真实性、安全性、鲁棒性、公平性和隐私性。针对每个方面,我们按照时间顺序提供了清晰且结构化的研究综述,并对其方法、发现及局限性进行详细分析。文末还附加了未来研究方向,以供参考与讨论。总体而言,尽管推理技术在通过缓解幻觉、检测有害内容以及提升鲁棒性方面展现出增强模型可信性的潜力,但前沿推理模型自身在安全性、鲁棒性和隐私性上往往存在相当甚至更为严重的脆弱性。通过综合这些洞见,我们希望本工作能为人工智能安全社区提供一个有价值且及时的资源,帮助其及时掌握关于推理可信性的最新进展。完整的相关论文列表可见:https://github.com/ybwang119/Awesome-reasoning-safety

1 引言
随着大型语言模型(LLMs)的发展,链式思维(Chain-of-Thought, CoT)技术已成为提升模型在多种下游任务(尤其是数学和代码生成)表现的重要手段。在 OpenAI 的 o1 系列模型以及 DeepSeek-R1 发布之后,具备系统-2 思维的推理模型的研发引起了全球研究者的广泛关注,随之带来了在强化学习算法、训练数据生成以及其他任务适配方法方面的一系列创新。 尽管取得了这些进展,CoT 技术及推理模型的可信性仍然缺乏深入探索。直观来看,或许可以合理推测推理能力能够推广至可信性领域,从而产生更安全、更可靠的模型。然而,近期的研究 [1, 2, 3] 并未支持这一理想化假设。此外,已有关于 LLM 安全性的综述 [4, 5, 6] 对推理作为模型可信性因素的讨论也极为有限。这一差距引出了核心问题:推理能力为语言模型的可信性带来了什么?
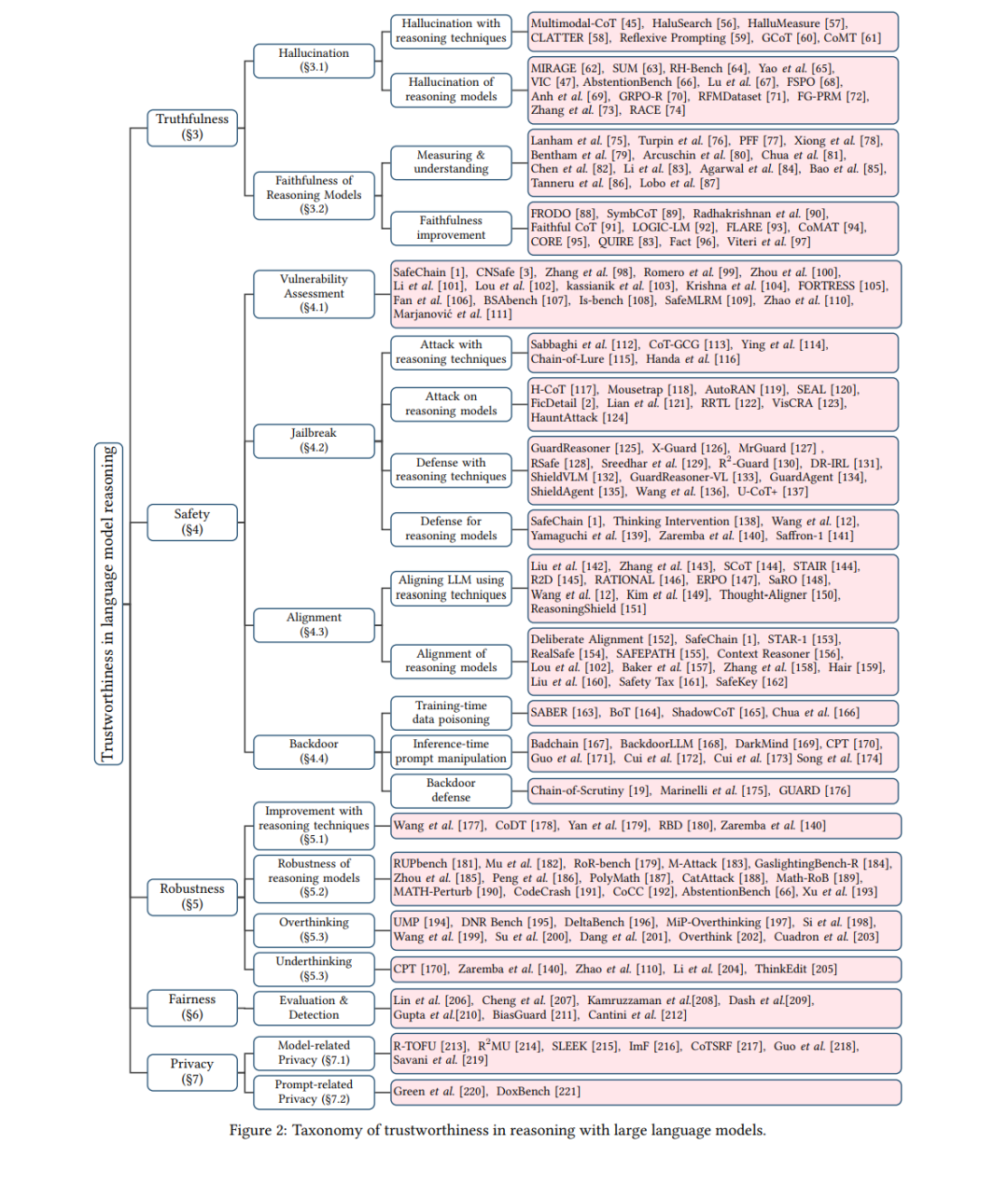
为解答这一问题,我们提出了首个全面综述,以系统回顾可信推理的最新进展。本文的综述围绕五个主要方面展开:真实性、安全性、鲁棒性、公平性和隐私性。在真实性部分,我们聚焦于模型可靠性,涵盖幻觉与推理忠实性,包括利用 CoT 技术的幻觉检测与缓解方法、推理模型中的幻觉分析、推理忠实性度量、忠实性理解,以及提升推理忠实性的方法。在安全性部分,我们旨在理解生成内容的无害性,主要考虑脆弱性评估、越狱、对齐与后门问题。为提高可读性,我们特别区分了针对推理模型的越狱攻击与推理技术在攻击与防御中的应用,并分别成段讨论相关文献。在鲁棒性部分,我们主要关注推理时由对抗性输入噪声引发的错误回答。当语言模型具备推理能力时,“过度思考”(overthinking)与“不足思 考”(underthinking)问题被强调为特殊案例。之后,在公平性部分,我们主要涵盖偏差检测的最新评估与方法。而在隐私部分,我们将相关研究分为模型相关隐私与提示相关隐私,讨论的主题包括模型遗忘、知识产权保护、水印技术以及隐私推断。
尽管已有综述探讨了推理技术 [7, 8] 与推理效率 [9, 10, 11],但对大型语言模型中推理的可信性关注相对较少。一项相关综述 [12] 对安全性相关方面进行了有价值的讨论。相比之下,我们的工作从更全面的角度审视可信性。总体而言,本文为推理中的模型可信性提供了清晰的分类体系,涵盖早期的 CoT 技术与端到端推理模型。通过对现有工作的回顾,我们指出:推理技术不仅有助于开发更具可解释性和更可信赖的模型,同时也引入了新的脆弱性。随着模型获得更高级的推理能力,其攻击面相应扩大,从而可能催生更复杂、更具针对性的对抗性策略。我们希望本文所综述的文献与提出的分类体系能够作为 AI 安全社区的及时参考,助力持续理解和改进语言模型推理的可信性。