
近日,中国科学院自动化研究所MMC团队高君宇等研究学者在具身智能视觉语言导航方面的论文被 ICML 2024 录用,论文提出了一种新的快-慢测试时自适应方法(FSTTA),有效解决具身智能中模型自适应更新的问题。论文是目前视觉-语言导航领域中第一篇被ICML接收的工作,值得关注!
国际机器学习大会(International Conference on Machine Learning,简称「ICML」)由国际机器学习协会主办。本届会议的投稿量达到了9473篇,相较于去年的6538篇增加了近3000篇,其中有2609篇论文被录用,录用率为 「27.5%」 。会议将于7月21日至27日在奥地利维也纳召开。

论文标题:Fast-Slow Test-Time Adaptation for Online Vision-and-Language Navigation 论文作者:Junyu Gao, Xuan Yao, Changsheng Xu 作者单位:中国科学院自动化研究所 论文链接:https://arxiv.org/abs/2311.13209 代码链接:https://github.com/Feliciaxyao/ICML2024-FSTTA
摘要视觉-语言导航作为实现具身智能的关键研究方向,专注于探索智能体如何准确理解自然语言指令并导航至目标位置。在实际中,智能体通常需要以在线的方式执行视觉-语言导航任务,即完成跨样本的在线指令执行和单样本内的多步动作决策。由于仅依赖预训练和固定的导航模型难以满足多样化的测试环境,这促使我们探索如何利用未标注的测试样本来实现有效的在线模型适应。然而,过于频繁的模型更新可能导致模型参数发生显著变化,而偶尔的更新又可能使模型难以适应动态变化的环境。为此,我们提出了一种新的快-慢测试时自适应方法(FSTTA),该方法在统一框架下对模型梯度和参数进行联合的分解与累积分析,以应对在线视觉语言导航任务的挑战。通过大量实验验证,我们的方法在四个流行的基准测试中均取得了显著的性能提升。值得注意的是,本文是目前视觉-语言导航领域中第一篇被ICML接收的工作。
- 引言
高效理解和执行人类指令在具身智能领域仍然是一个显著挑战。近年来,视觉与语言导航(Vision-and-Language Navigation, VLN)已经成为衡量智能体指令遵循能力的重要平台。 在实际应用中,如图1(a)所示,训练好的VLN智能体需要在多样化的时间和环境中,实时地、在线地执行用户指令。迄今为止,大多数现有的VLN任务并没有遵循在线设置。通常,它们遵循一个独立的训练-测试范式,其中模型在训练集上进行训练,然后将固定的模型在测试集上进行评估,而不在测试期间进行自适应模型更新。然而,由于在线测试期间环境因素的多样性(例如,不同的房间布局、物体种类和数量等),固定的预训练模型不可避免地会遇到数据分布差异[1-2],这一现象对智能体的性能构成了挑战,并不可避免地出发了一个关键性的探讨:**智能体是否能够在执行指令的过程中不断积累经验,从而动态地增强其理解和执行能力?**对于现有方法而言,由于在线测试环境中缺乏足够的标注信息,直接通过监督学习来实时更新模型是不可行的。此外,无监督域适应或半监督学习等其他学习范式在当前情境中也受限于执行效率以及用户隐私保护的问题。 测试时自适应(Test-Time Adaptation, TTA)作为近年来备受瞩目的在线模型更新方法,其通过利用未标记的测试样本对模型进行自适应调整以适应不同分布类型的测试数据,提高模型的泛化能力和实用性。然而,现有大多数TTA方法未能充分平衡模型的适应性和稳定性,难以直接集成应用于VLN任务中。不同于传统分类任务中每个测试样本仅执行一次TTA操作,在线VLN要求智能体在每一个测试样本内执行一系列动作,并依次处理各个样本(指令),如图1(a)所示。在这种情境下,一方面,在每个(或几个)动作步骤上进行TTA虽然可以使智能体快速适应动态环境,但频繁的模型更新可能带来显著的模型变化,导致累积误差和灾难性遗忘等问题[3-5],从而损害模型的稳定性。另一方面,在每个测试样本中初始化相同的模型来执行TTA可以保持模型的稳定性,但这种方式可能会阻碍模型从历史测试样本中自适应地学习经验,进而限制了其实现更高性能的潜力。如图1(b)所示,无论是过快还是过慢的模型更新策略,都难以实现显著的性能提升。
图1:在线视觉语言导航任务示例 为解决上述问题,我们提出了一种面向在线视觉-语言导航任务的快-慢测试时适应(Fast-Slow Test-Time Adaptation, FSTTA)方法。该方法基于统一的梯度-参数分解累积框架,通过结合快速和慢速在线更新两种策略,旨在实现模型适应性和稳定性的平衡。具体而言,在快速更新阶段,我们依据测试时期的训练目标(如熵最小化[6]),在每个动作步骤中来计算优化梯度。然而,由于TTA的无监督特性,这些梯度不可避免地包含噪声信息。若直接使用这些梯度进行更新,可能会损害模型的适应性,特别是在频繁执行更新的情况下。因此,我们构建了一个局部坐标系,通过周期性地分析最近多步导航过程中生成的梯度,以寻找更为可靠的优化方向,确保模型在该阶段能够稳定且有效地适应环境变化。随后,为了进一步缓解过于频繁的模型更新可能导致的累积误差和灾难性遗忘问题,我们引入慢速更新阶段,利用参数变化轨迹分析将模型恢复至一个稳定的状态,以实现更为精准和稳健的模型优化。这两个阶段在测试过程中交替进行,既保证了模型的稳定性,又实现了对动态环境的快速适应。如图1(b)所示,相较于其他更新策略,我们提出的FSTTA方法显著提升了模型性能。 总之,本文的贡献总结如下: * 鉴于跨样本在线指令执行和单样本内多步动作执行的特性,探索了在线视觉语言导航任务,并创新性地提出了一种用于高效导航和模型更新的快-慢测试时适应(FSTTA)方法。 * 提出了一种统一的梯度和参数分解-累积框架,以确保模型在短期快速更新阶段能迅速适应环境变化,同时在长期慢速更新阶段维持模型的稳健性。 * 在四个公开数据集上开展了大量的实验与分析,证明了FSTTA方法能够显著提升现有视觉语言导航模型的性能,且其有效性优于当前的SOTA测试时自适应方法。当应用于代表性的VLN方法DUET时,FSTTA在离散/连续基准数据集上REVERIE/R2R-CE实现了超过5%的性能提升。
**02. 问题表述 **
给定自然语言指令
,其中
表示可导航节点,
是当前时间步。特别地,图中添加了一个“STOP”节点来表示停止动作,并与所有其他节点连接。在每个时间步,智能体将接收到一个由36幅单张图像组成的全景图,并使用预训练的视觉模型ViT[7-8]来提取相应的图像特征
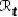
。基于所观测到的特征和执行动作的历史信息,智能体预测所有当前可导航节点的概率
,并选择最可能(即最大概率)的一个节点作为下一时刻动作决策。
- 方法概述
模型的整体架构如图2所示,包含快速更新和慢速优化自适应两个模块,并在测试期间以固定周期交替执行。在快速更新阶段,通过周期性分析短期内多个执行步所生成的梯度,寻找可靠的优化主方向,以避免梯度噪声和频繁更新所带来的干扰;在慢速优化阶段,通过类似的方法对先前的模型参数变化轨迹进行分解,基于历史信息直接调整模型参数,以缓解可能出现的灾难性遗忘等问题。另外,我们还利用不确定性信息和迭代更新的实时情况,动态调整自适应学习率,以实现有效可信的模型更新。 由于更新整个模型的计算代价过高,实际应用中难以实现。因此,我们仅针对模型参数中的一小部分进行梯度计算。由于归一化层中的仿射参数能够捕捉到数据分布的关键信息,大多数TTA方法[6, 9-10]选择更新这些参数以实现更好的适应性。在本文中,我们选择了VLN基础模型的后端LN层执行TTA操作,并冻结了其他参数。为便于表述,我们使用符号 来表示这些待更新的参数。
图2: 模型的整体架构
3.1 基于梯度分析的快速更新 视觉语言导航是一个连续的决策过程,每个时间步都需要基于历史信息和当前视觉感知做出合适的导航决策,而传统的测试时自适应方法在每个时间步仅仅根据当前样本独立进行更新,在一定程度上加剧了误差累积问题[4-5],本模块通过分解一定周期内记忆的梯度方向,寻找一个具有一致性的最优方向执行模型的迭代更新。 测试导航过程中每个时间步 ,模型需要依据预测分数
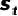
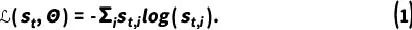
在当前样本的第 次更新中,所累积前
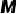
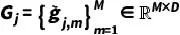
。这些梯度代表了测试期间视觉语言导航模型的学习方向,不可避免地存在着一些误导信息或噪声干扰。因此,我们首先通过SVD分解构建一个由
个正交单位向量
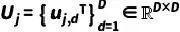
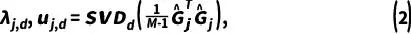
其中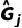
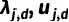
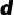
其中梯度累积自适应系数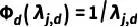
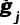
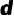
,以提升模型的性能和稳定性:
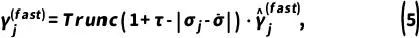
其中
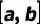
、
和
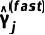
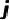
。 3.2 基于参数轨迹分析的慢速优化
为了避免频繁的快速更新导致的灾难性遗忘,保持测试期间视觉语言模型的稳定性,本模块采用不同样本测试期间所记录的历史状态,以快速更新阶段中类似的方法对参数变化轨迹进行分析,每隔 个测试样本优化模型参数。如图2,在当前测试阶段的第
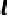
个历史样本的最后模型状态为
,其中
。同样的,由中心化参数变化轨迹矩阵
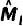
,并且较大特征值对应的单位向量
描述了历史参数变化的主要方向,较小特征值对应的向量往往包含更多噪声信息[11],因此为了寻找一个可靠的优化路径,需要更关注前者。本模块聚合
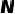
,辅助模型寻找局部最优解:
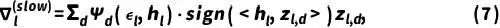
其中超参数 ,用于为不同的历史信息分配权重。具体来说,与当前样本执行时间越接近的模型状态将获得更大的权重,因为它们包含了更丰富的、值得参考的样本信息。另外,参数轨迹分析自适应系数
,用于自适应调整不同参数变化方向的权重,
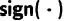
。 由于慢速更新阶段旨在实现稳定的模型学习且不会频繁调用,因此我们在此阶段采用固定学习率。更新后的参数
将用于随后的测试样本,继续执行新的快速更新。
04. 实验设置
4.1 数据集 实验选择了四个常用的标准视觉语言导航数据集:REVERIE[12],R2R[13],SOON[14]和R2R-CE[15],以研究在线视觉语言导航任务中的TTA方法。REVERIE数据集包含10,567张全景图像和21,702条高阶指令,除常规的导航任务外还要求智能体在90种不同建筑环境中完成目标物体定位任务。R2R数据集涵盖了10,800个全景视图和7,189条路径,并提供了导航任务的逐步分解指令。SOON数据集包含3,848组指令以及超过30,000条长距离轨迹,要求智能体根据详细的指令描述来精确定位目标对象。与前述在离散环境下构建的VLN数据集不同,R2R-CE数据集包含了基于连续环境的16,000个指令-轨迹对,其中智能体能够自由移动并与障碍物进行交互。 4.2 评估指标 我们遵循之前的方法[7, 12, 17-18],采用最常用的评估VLN智能体的指标,即TL(Trajectory Length):智能体平均路径长度;NE(Navigation Error):智能体最终位置与目标位置之间的平均距离;SR(Success Rate):成功执行指令(NE小于3米)的比例;SPL(Success weighted by Path Length):由路径长度加权的成功率;OSR(Oracle Success Rate):在Oracle停止策略指导下的成功率;RGS(Remote Grounding Success rate):目标物体定位任务成功执行指令(输出的边界框与真实值的IoU(交并比)≥ 0.5)的比例;RGSPL(RGS weighted by Path Length):由路径长度加权的RGS。其中,SR和SPL是最常用的评估指标。 4.3 实施细节
为了更符合实际在线VLN应用情境,我们在评估期间将批处理大小设置为1,且随机打乱每个数据集的测试样本,依次逐个输入智能体,其中每个样本(和每个动作步骤)仅进行一次前向传播,以模拟在线执行和适应优化过程。对于执行TTA策略的VLN模型,我们在随机样本上运行实验5次并报告平均结果。我们采用DUET[7]和HM3D[18]作为基础模型。由于HM3D没有提供R2R-CE的训练代码,我们采用其他SOTA方法,如WS-MGMap[19]和BEVBert[20],进行TTA。在我们的FSTTA中,我们仅利用基础模型的最后四层LN层进行模型更新,这些层的特征维度均为768。我们将快速和慢速更新周期分别设置为M = 3和N = 4,两阶段的学习率分别为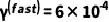
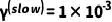
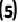
,更新动量
,截断区间为
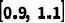
。所有实验均在RTX 3090 GPU上进行。
- 实验结果
另外,所有表格中的实验结果最佳值均用粗体突出显示。此外,为了更直观地展示我们方法的效果,从表5到表8中,我们使用了不同的字体颜色来指示我们的方法是否超越了相应的基线方法,其中红色表示优于基础模型的结果,蓝色表示表现不如基础模型的结果。 5.1 与其他现有TTA策略的比较 目前,多种TTA策略已被巧妙地集成用于动态模型更新,并取得了显著进展。尽管在视觉语言导航领域对TTA的探索相对较少,但将当前先进的TTA方法整合到VLN中仍然展现出巨大的潜力。鉴于效率是评估TTA方法的重要指标之一,我们提供了每种方法执行单条指令所需的平均时间以供比较。在对比的方法中,SAR[9]和TENT[6]是常见的基于熵最小化的模型,而NOTE[21]、CoTTA[3]、EATA[4]和ViDA[22]则代表最先进的连续TTA(Continual TTA)方法。如表1所示,FSTTA方法在模型性能和测试效率上均展现了出色的能力。具体而言,在Val Unseen数据集上,我们的方法在SR和SPL上分别比现有最先进的SAR方法提升了6.2%和2.5%,同时测试时间减少了7%。
从结果中可以看出,直接将现有的TTA方法应用于在线VLN任务并不能带来显著的性能提升。为了进一步研究TTA方法的效果,我们基于TENT方法探索了不同的更新频率以及稳定的更新方法。其中,“INT”代表更新间隔,即模型在特定间隔内平均梯度信息后进行一次更新。这些实验结果与图1(b)中的描述相一致,展示了我们的方法在时间成本略有增加的情况下,仍然优于其他策略。
表1:VLN基础模型在REVERIE数据集中采用不同TTA策略的结果
5.2 消融实验 为了验证FSTTA策略的有效性,我们将其快速更新Fast和慢速更新Slow两个阶段分别集成到基准模型DUET中。此外,我们还设计了一个基准变体,即将DUET与现有的TTA策略TENT相结合,并采用与FSTTA快速阶段相同的更新周期(即相同的M值),直接通过平均梯度实现模型优化。根据表2的实验结果,快速和慢速更新策略分别使基准模型在SR指标上实现了2.8%和4.3%的提升。此外,动态学习率调整模块DLR也有助于提升模型的导航能力。
表2:消融实验结果
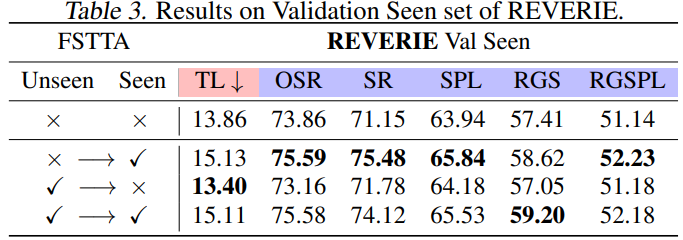
表3:历史遗忘评估实验结果
5.3 历史经验遗忘评估 在线VLN(视觉语言导航)智能体在持续执行新环境中的新指令时,尽管采用了TTA策略以增强其泛化能力,但仍不可避免地面临历史环境和指令的灾难性遗忘问题。为评估我们的方法是否存在这一问题,我们在REVERIE数据集的Val Seen部分重新评估了我们的方法。与基准模型相比,如表3所示,我们得出以下结论: (1) 采用FSTTA策略的基准模型直接在Val Seen集上进行测试时,其性能得到显著提升,这验证了FSTTA策略的有效性; (2) 基准模型在Val Unseen集上应用FSTTA策略后,直接在Val Seen集上进行测试,即便在没有执行自适应更新的情况下,该模型的性能也能与基准模型相当,这一发现证实了我们的方法有效避免了灾难性遗忘的问题; (3) 进一步地,我们将从Val Unseen集上更新后的模型应用于Val Seen集,并采用FSTTA策略,该结果与仅在Val Seen集上进行TTA的模型效果相当,这表明我们的方法在环境适应和经验积累方面均表现出色,能够有效地应对新环境和新指令的挑战. 5.4 泛化性分析 在实际应用中,智能体通常会面临先前遇见过的熟悉场景与全新的未知场景。前期实验中,我们分别利用REVERIE数据集中的Val Seen和Unseen部分进行了测试。为了深入验证模型的泛化能力,我们将Val Seen和Unseen两部分数据混合成一个统一的数据集进行在线VLN测试。如表4所示,FSTTA策略在该任务中表现优于其他TTA方法,能够更有效地处理各种测试场景,证明了其在不同环境条件下的稳定性和适应性。
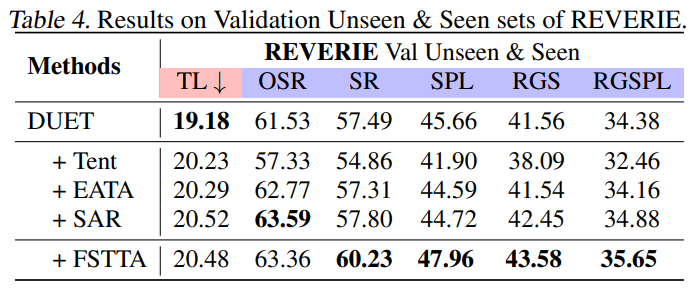
表4:泛化性分析实验结果
5.5 与其他现有VLN方法的比较 (1)** REVERIE数据集**:表5详尽展示了在REVERIE数据集上的对比结果。与不执行TTA的基础模型相比,所提出的方法在大多数评价指标上显示出显著的性能提升。具体来说,在验证集上,我们的方法相较于DUET展示了显著优势,SR提升了7.1%,SPL提升了2.7%。这些结果充分证明了FSTTA策略的有效性,同时也彰显了TTA在视觉语言导航领域的巨大潜力。 (2) R2R数据集:表6展示了在R2R数据集上的对比结果。我们的方法在多个关键指标上优于基础模型。例如,DUET的SR从72%提升到75%,HM3D的SPL从62%提升到63%。值得注意的是,从上述两个数据集的结果来看,我们的方法在提高VLN成功率的同时,也导致路径长度(TL)略有增加。我们推测可能的原因是:在线执行TTA可能增加智能体偏离其原始动作执行模式的可能性,导致更多的探索或回溯。这种情况也在表1的各种TTA策略分析中得到了证实。 (3) SOON数据集:表7展示了在SOON数据集上的对比结果。我们的方法在该数据集的大多数指标上均取得了显著的性能提升,并实现了新的最好结果。具体来说,在验证集的Val Unseen部分,HM3D-FSTTA在SR和SPL上分别达到了42.44%和31.03%,而之前的SOTA方法GridMM在这两项指标上的表现分别为37.46%和24.81%。此外,在测试集的Val Unseen部分,我们的方法也显著提升了DUET的性能,例如,将SPL从21.42%提升至23.23%。 (4) R2R-CE数据集:在连续环境中,FSTTA策略同样展现了良好的泛化能力。如表8所示,我们的方法在与其他方法的对比中,无论是性能还是稳定性,都表现出优越或相当的水平,进一步证明了FSTTA在应对连续环境变化时的有效性和可靠性。
表5:REVERIE数据集实验结果
表6:R2R数据集实验结果
表7:SOON数据集实验结果
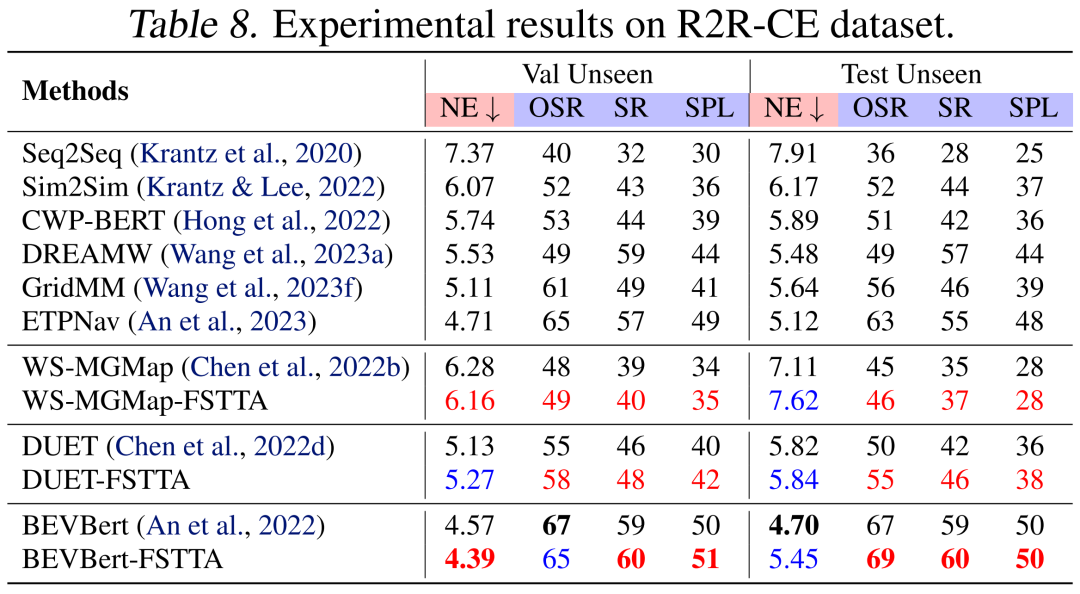
表8:R2R-CE数据集实验结果
5.6 可视化分析 图3详细展示了智能体执行指令的全过程,验证了我们提出的FSTTA方法能够在测试阶段动态地提升智能体的导航性能。图中,黄色点代表起始位置,而带有红色和绿色标记的有向线则分别指示了错误和正确的预测轨迹。通过应用FSTTA策略,基础模型DUET的探索能力展现显著增强,能够更有效地向正确的方向移动,并基于上下文信息和场景布局成功完成了导航任务。
图3:REVERIE数据集中智能体实际导航路径可视化
06. 结论
本文探讨了在线视觉语言导航任务中测试时自适应策略的可行性。我们提出了一种快速-慢速测试时自适应(FSTTA)方法,通过对梯度和参数进行分解-累积分析,实现了适应性和稳定性之间的平衡。在四个常用的标准视觉语言导航数据集上进行的实验验证了该方法的优异性能。未来我们将进一步优化和扩展该方法,以应对更多的应用场景和挑战。 尚有一些方面值得未来继续探讨。首先,我们的方法侧重于调整模型中的归一化层。尽管这些层在深度学习中被广泛使用,但仍有一些方法没有利用它们。解决这一问题的一种可行方法是在相应的模型中引入额外的归一化层,并使用训练数据重新训练模型。未来,我们还将探索如何更新其他类型的层。其次,在本文中,我们通过从测试集中顺序输入不同的样本数据来简单模拟在线VLN(视觉导航)设置。将来,我们的目标是构建一个更符合实际应用场景的现实在线学习VLN数据集,以更好地评估TTA(测试时训练)方法。第三,与基础模型相比,引入TTA不可避免地会增加额外的计算成本,这是未来改进的一个方向。最后,快速和慢速更新的频率是固定和周期性的。采用自适应更新调用策略也是一个值得研究的方向。
参考文献 [1] Gu, J., Stefani, E., Wu, Q., Thomason, J., and Wang, X. Vision-and-language navigation: A survey of tasks, methods, and future directions. In ACL, pp. 7606–7623, 2022. [2] Guhur, P.-L., Tapaswi, M., Chen, S., Laptev, I., and Schmid, C. Airbert: In-domain pretraining for vision-and-language navigation. In ICCV, pp. 1614–1623, 2021. [3] Wang, Q., Fink, O., Van Gool, L., and Dai, D. Continual test-time domain adaptation. In CVPR, pp. 7201–7211, 2022a. [4] Niu, S., Wu, J., Zhang, Y., Chen, Y., Zheng, S., Zhao, P., and Tan, M. Efficient test-time model adaptation without forgetting. In ICML, pp. 16888–16905, 2022. [5] Song, J., Lee, J., Kweon, I. S., and Choi, S. Ecotta: Memory-efficient continual test-time adaptation via self-distilled regularization. In CVPR, pp. 11920–11929, 2023. [6] Wang, D., Shelhamer, E., Liu, S., Olshausen, B., and Darrell, T. Tent: Fully test-time adaptation by entropy minimization. In ICLR, 2021. [7] Chen, S., Guhur, P.-L., Tapaswi, M., Schmid, C., and Laptev, I. Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In CVPR, pp. 16537–16547, 2022d. [8] Li, X., Wang, Z., Yang, J., Wang, Y., and Jiang, S. Kerm: Knowledge enhanced reasoning for vision-and-language navigation. In CVPR, pp. 2583–2592, 2023. [9] Niu, S., Wu, J., Zhang, Y., Wen, Z., Chen, Y., Zhao, P., and Tan, M. Towards stable test-time adaptation in dynamic wild world. In ICLR, 2023. [10] Liang, J., He, R., and Tan, T. A comprehensive survey on test-time adaptation under distribution shifts. arXiv preprint arXiv:2303.15361, 2023. [11] Wang, Z., Grigsby, J., and Qi, Y. Pgrad: Learning principal gradients for domain generalization. In ICLR, 2023e. [12] Qi, Y., Wu, Q., Anderson, P., Wang, X., Wang, W. Y., Shen, C., and Hengel, A. v. d. Reverie: Remote embodied visual referring expression in real indoor environments. In CVPR, pp. 9982–9991, 2020. [13] Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sunderhauf, N., Reid, I., Gould, S., and Van Den Hengel, A. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In CVPR, pp. 3674–3683, 2018. [14] Zhu, F., Liang, X., Zhu, Y., Yu, Q., Chang, X., and Liang, X. Soon: Scenario oriented object navigation with graph-based exploration. In CVPR, pp. 12689–12699, 2021. [15] Krantz, J., Wijmans, E., Majumdar, A., Batra, D., and Lee, S. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In ECCV, pp. 104–120, 2020. [16] Li, J., Tan, H., and Bansal, M. Envedit: Environment editing for vision-and-language navigation. In CVPR, pp. 6741–6749, 2022. [17] Wang, Z., Li, X., Yang, J., Liu, Y., and Jiang, S. Gridmm: Grid memory map for vision-and-language navigation. In ICCV, pp. 15625–15636, 2023f. [18] Chen, S., Guhur, P.-L., Tapaswi, M., Schmid, C., and Laptev, I. Learning from unlabeled 3d environments for vision-and-language navigation. In ECCV, pp. 638–655, 2022c. [19] Chen, P., Ji, D., Lin, K.-L. C., Zeng, R., Li, T. H., Tan, M., and Gan, C. Weakly-supervised multi-granularity map learning for vision-and-language navigation. In NeurIPS, pp. 38149–38161, 2022b. [20] An, D., Qi, Y., Li, Y., Huang, Y., Wang, L., Tan, T., and Shao, J. Bevbert: Topo-metric map pre-training for language-guided navigation. arXiv preprint arXiv:2212.04385, 2022. [21] Gong, T., Jeong, J., Kim, T., Kim, Y., Shin, J., and Lee, S.-J. Note: Robust continual test-time adaptation against temporal correlation. In NeurIPS, pp. 27253–27266, 2022. [22] Liu, J., Yang, S., Jia, P., Lu, M., Guo, Y., Xue, W., and Zhang, S. Vida: Homeostatic visual domain adapter for continual test time adaptation. In ICLR, 2024.
