

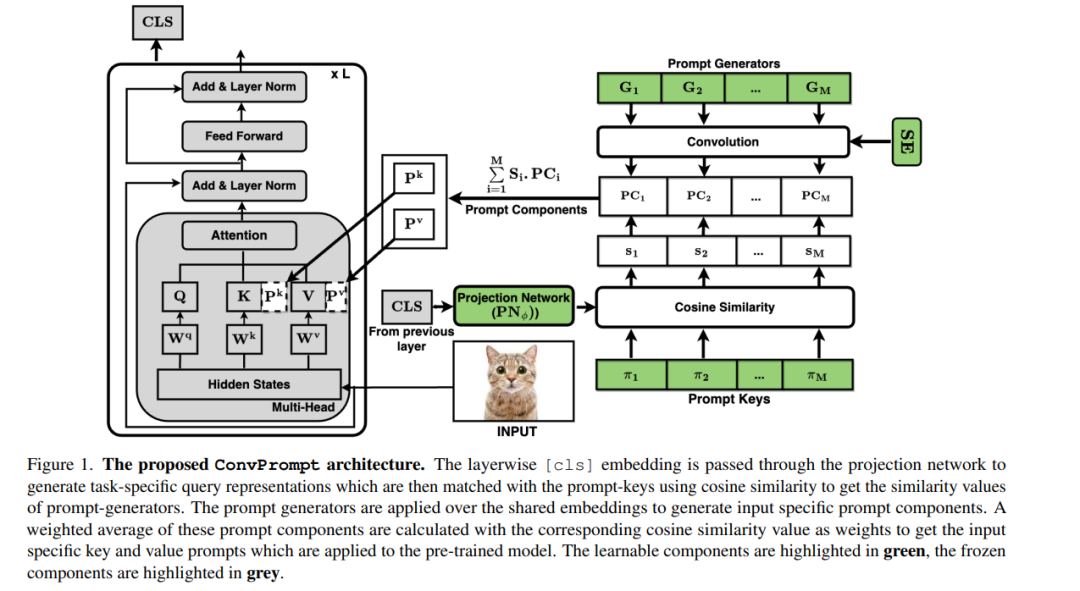
持续学习(CL)使得机器学习模型能够在缺乏旧任务数据的情况下,从不断变化的新训练数据中学习。最近,预训练的视觉Transformers结合提示微调已经显示出克服CL中的灾难性遗忘的希望。这些方法依赖于一池可学习的提示,这在跨任务共享知识时可能效率低下,导致性能较差。此外,缺乏细粒度层特定提示不允许这些方法充分表达提示对CL的强度。我们通过提出ConvPrompt,一种新颖的卷积提示创建机制来解决这些限制,该机制保持层次共享嵌入,使得层特定学习和跨任务更好的概念转移成为可能。智能地使用卷积使我们能够在不影响性能的情况下保持低参数开销。我们进一步利用大型语言模型生成每个类别的细粒度文本描述,这些描述用于获取任务相似性,并动态决定要学习的提示数量。广泛的实验表明,ConvPrompt的优越性,并且以显著更少的参数开销提高了SOTA约3%。我们还对各种模块进行了强大的消融实验,以解析不同组件的重要性。
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
204+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年3月21日


相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
204+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年3月21日