
以高速机动目标拦截为问题背景,基于深度强化学习提出了一种不依赖目标加速度估计的逆轨拦截最优控制指令生成 方法 ,并通过仿真实验进行了有效性验证。从仿真实验结果看,提出的方法实现了三维空间高速机动目标逆轨拦截并大幅削减了对带有强不确定性目标估计的要求,相比最优控制方法具有更强的适用性。 随着科学技术的不断进步,现代化战争正逐步演化为体系化攻防对抗,作为其中的重要火力打击手段之一,战术弹道导弹[1](tactical ballistic missile, TBM)再入大气层时,通常远高于防御武器的速度,为成功拦截防御带来了一定的困难。
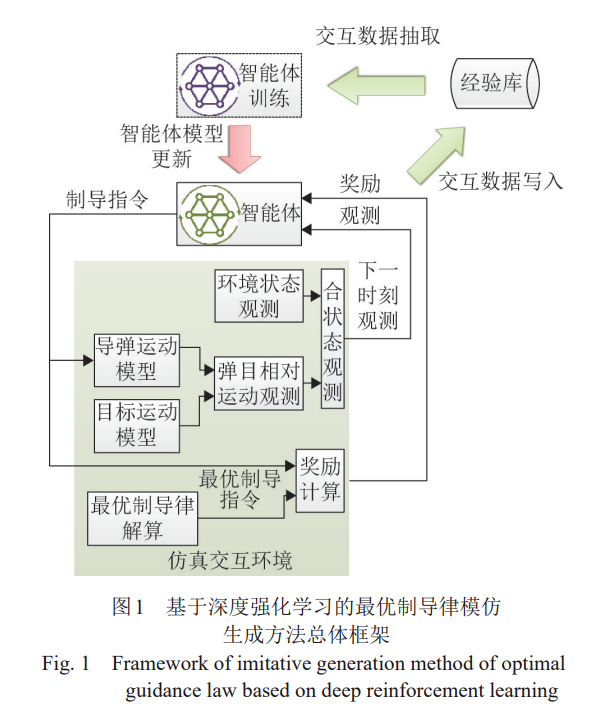
针对以TBM目标为代表的高速机动目标再入速度高、机动能力强的特点,为有效对目标进行打击,需要采用带有较强末端角度约束的逆轨拦截方式。逆轨拦截是指防御武器接近目标时以反目标速度的方向迎击目标。这种打击方式一方面便于导引头截获和稳定跟踪目标,对于提高引战配合效率和战斗部杀伤概率极为有利;另一方面能够通过将导弹引入良好的弹目相对位置,形成良好的拦截态势,削减高速目标机动拉开的防御武器能量需求缺口,降低低速导弹打击高速目标难度,达到更好的作战效果。 目前,已有针对高速目标打击的制导律生成方法问题的大部分研究是围绕比例制导[2-6]、滑模制导[5-6]和最优制导[7-10]等方法进行制导律设计。在这些研究中,研究人员均对弹目交会时刻的期望角度约束进行了考虑,并通过虚拟目标导引[2]、指令反馈[4]、寻优约束条件[7-9, 11-12]等手段对制导过程终点的交会角度限制进行了约束,进而实现在弹目交会时对目标的逆轨拦截,达到较好的打击效果。 上述研究大多从理论分析出发,均显式或隐式地引入了前提假设,从而在其方法的应用上带来了不同程度的限制,特别是对目标与导弹运动能力的限制。例如,部分文献假设打击的目标为固定目标[2, 3, 5]或匀速运动目标[7],或者假设导弹运动速度不变[2-5]。这为所设计的制导律带来了较大的限制约束。文献[5-6]均考虑了对高速机动目标打击问题,但均围绕二维平面内的制导律生成问题开展研究。文献[8-9]在三维空间对高速机动目标的逆轨拦截问题进行了研究,分别采用最优制导与高斯伪谱法进行制导律设计,得到了较好的逆轨拦截效果。然而在制导律设计中,文献[8-9]均引入了目标运动加速度作为设计输入。面向目标机动样式和探测信息均存在不确定性的场景,上述方法对探测与估计部分提出了更高的要求。 近年来,由深度学习[13-14]崛起助推的新一代人工智能技术掀起了新一轮智能化浪潮,相继攻克视频游戏[15]、围棋[16]、星际争霸II[17]等,揭示了其在复杂问题求解方面的巨大潜力,也为解决上述问题的求解带来新的契机。当前,基于深度强化学习的智能制导律生成方法方面已有部分研究[6,18-20],但是,一方面现有研究中较多所采用的拦截导弹模型较为简化,一些研究甚至未考虑气动部分的模型[20-21];另一方面,现有研究也鲜有聚焦于高速目标逆轨拦截问题。 针对此,本文提出一种基于深度强化学习的最优控制律模仿生成方法,以弹目相对运动及导弹自身动力学状态为输入,以模仿最优导弹导引控制(即最优制导)过程为奖励生成函数,借助深度神经网络强非线性拟合能力,构建面向三维空间高速机动目标逆轨拦截的导弹导引控制指令(即制导指令)生成。该方法具有如下特点:①可实现在三维空间中对目标的逆轨拦截;②可实现对高速机动目标的逆轨拦截;③制导指令生成过程不再需要以目标加速度作为决策输入,从而大幅削减了对带有强不确定性目标估计的要求,具有更好的适用性。

