自然语言处理(NLP)允许在越来越多的应用中自动分析文本数据,包括新的任务、新的领域和新的语言。在这些情况下,NLP模型通过识别文本的含义来提升埋藏在文本库中的知识价值。基于神经网络的NLP模型擅长从大量的标记数据中学习。标记数据由输入和相应的输出组成,它们被注释为机器学习模型学习或预测的结果。基于神经模型,数据资源丰富的NLP任务性能得到提高。同时,在数据资源匮乏的情况下,如特定领域的应用,大规模数据的短缺使得特定领域数据的处理成为NLP中最具挑战性的问题之一。基于神经网络的模型在数据资源匮乏的情况下往往是不充分的,在特定领域的应用中容易遗漏重要知识。由于数据短缺,再加上人工准备可靠训练数据的高成本,这种不足是具有挑战性的。为了提高神经模型在低资源情况下的学习能力,利用该领域完善的辅助数据资源实现自动数据准备,促进神经结构学习将是非常重要的。
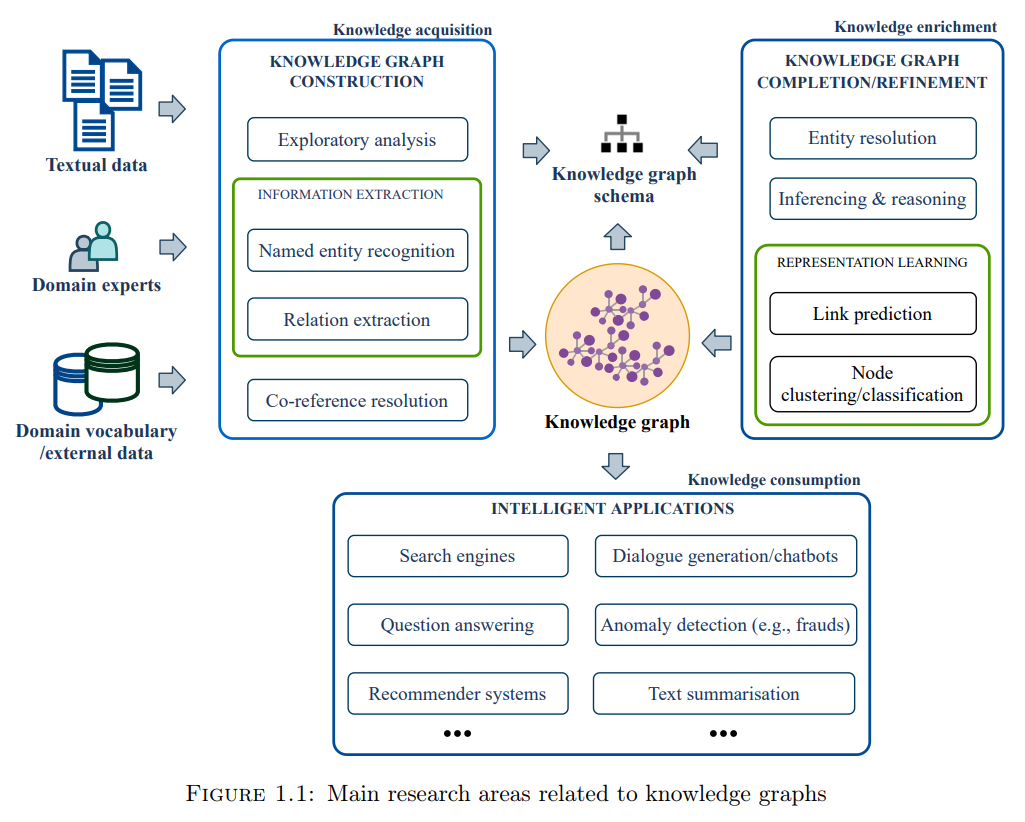
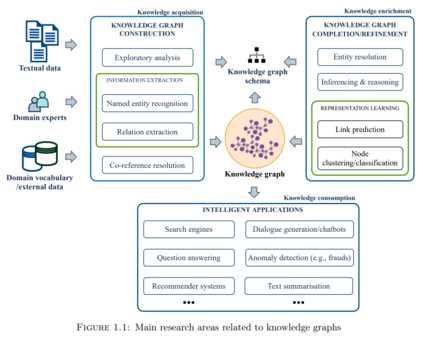
本论文基于两个学科的研究:计算机科学和地质学。重点是地质学中矿产勘探报告中的知识发现,这是一个低数据资源领域。目的是研究和开发构建地质知识图的方法,通过从矿产勘探报告中提取与矿床环境条件相关的地质细节,其中包括可公开获得的特定领域的文本数据。例如,像谷歌和微软这样的组织将从文本数据中提取的信息存储在他们的知识图谱中,这些信息可以被各种智能应用所访问,例如为给定关键词寻找和推荐相关信息的搜索引擎,以及进行在线聊天对话的聊天机器人。
本论文的主要贡献是建立一个地质知识图谱的工作流程,解决了在特定领域、低数据资源环境下应用基于机器学习的NLP模型的挑战。机器学习算法,利用成熟的辅助数据资源,如采矿地点、地质时间尺度或矿物类型的数据库,能够解决训练数据的稀缺性,并提高进一步NLP任务的下游性能:
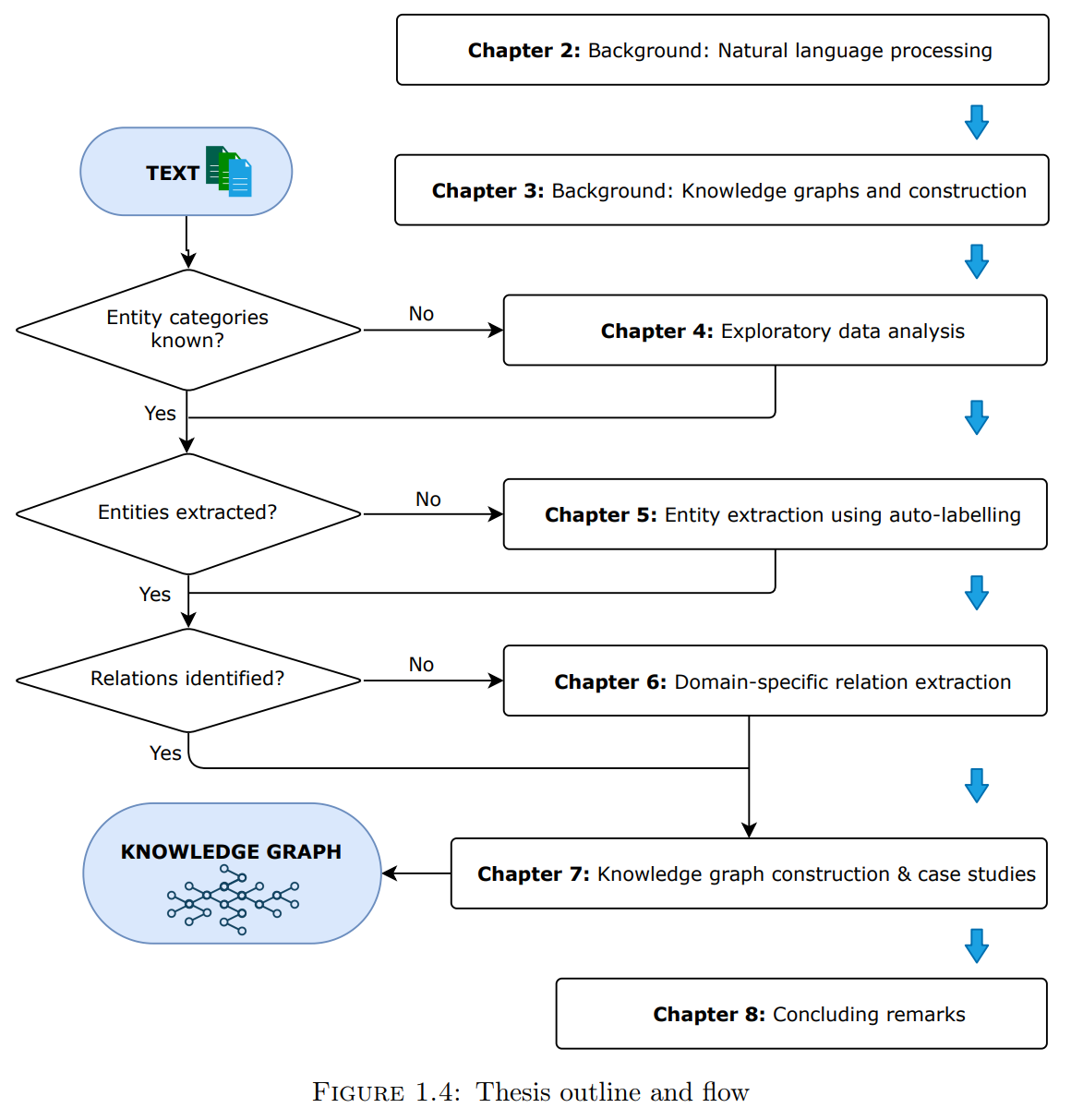
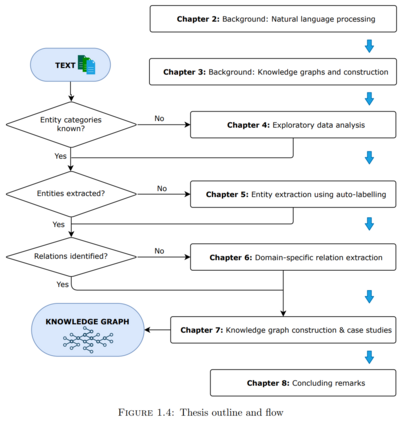
1.使用探索性数据分析技术来自动检测未知文本语料中的相关关键概念,以建立一个包含文本领域综合术语的领域词典。
2.提出了一个框架,以改善特定领域的命名实体识别,使用深度学习和领域词典。结果产生了一个自动标记的地质数据集,包含六个地质实体。
3.使用语义分析和无监督机器学习,提出了一个提取实体间关系的框架。14种关系类型被确认为矿物勘探报告中的重要关系。
4.构建了地质知识图谱,并对矿产勘探领域进行了验证。
5.最后,讨论了所提方法的可行性和实用性。
在这篇论文中,为了处理训练数据的稀缺性和提高下游NLP任务在低资源文本中的性能,提出了将机器学习算法与成熟的数据资源相结合。虽然所提出的方法主要是针对矿产勘探领域的,但这些方法也适用于其他行业相关的语料库,在这些语料库中没有标记数据或没有足够的数据来训练神经模型,但在该行业中却有明确的词汇或术语资源。