

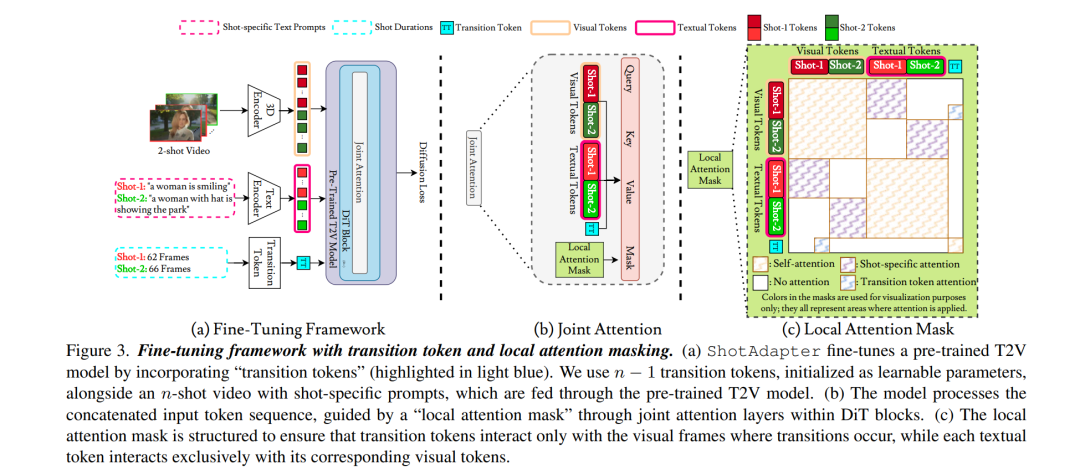
当前基于扩散模型的文本生成视频方法仅限于生成单一镜头的短视频片段,尚不具备生成包含多个镜头转换的视频能力,尤其是在保持同一角色在相同或不同背景下执行不同动作的一致性方面存在显著限制。为了解决这一问题,我们提出了一个新的框架,该框架包括一个数据集构建流程和对现有视频扩散模型的结构扩展,从而实现文本生成多镜头视频(text-to-multi-shot video generation)。 我们的方法能够将多镜头视频作为一个整体进行生成,并在所有镜头的所有帧之间实现全局注意力机制(full attention),从而确保角色和背景的一致性。此外,用户可以通过**镜头级条件控制(shot-specific conditioning)**自由设定视频中镜头的数量、时长和内容。 该能力的实现依赖于两个关键技术创新: 1. **过渡标记(transition token)**的引入,用于控制新镜头在视频中何时开始; 1. 局部注意力遮蔽策略(local attention masking strategy),用于控制过渡标记的作用范围,并支持镜头级文本提示。
为获得训练所需的数据,我们还提出了一种新颖的数据构建流程,可从现有的单镜头视频数据集中构建一个多镜头视频数据集。 大量实验证明,仅需对一个预训练的文本生成视频模型微调几千步,即可使其具备生成具备镜头控制能力的多镜头视频的能力,并在多个基线方法上取得更优表现。
成为VIP会员查看完整内容
相关内容
Arxiv
39+阅读 · 2023年4月19日
Arxiv
209+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
142+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
39+阅读 · 2023年4月19日
Arxiv
209+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
142+阅读 · 2023年3月29日