

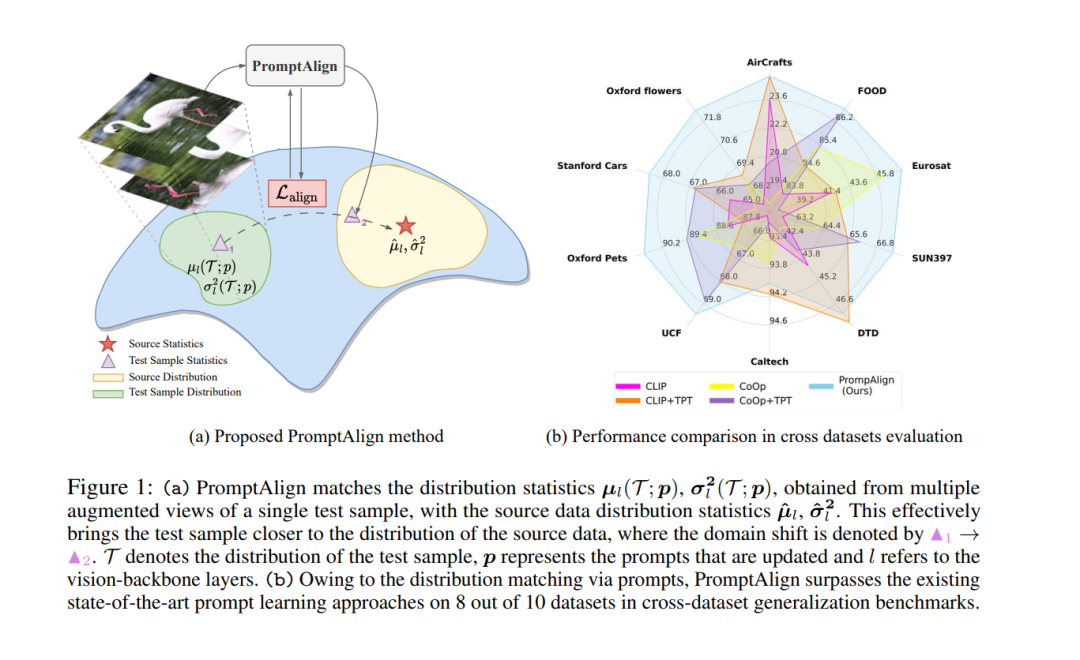
视觉语言模型(如CLIP)的零样本泛化很有前途,这导致了它们在许多下游任务中使用提示学习。以前的工作已经表明,使用熵最小化进行测试时提示调优,以适应未见过的领域中的文本提示。虽然有效,但这忽略了未见过的领域性能下降的关键原因——分布偏移。在这项工作中,我们通过使用提示调优将分布外(OOD)测试样本统计与源数据的统计进行对齐,明确地处理了这个问题。我们使用单个测试样本在测试时通过最小化特征分布偏移来适应多模态提示,以弥合测试领域的差距。根据领域泛化基准进行评估,我们的方法比现有的提示学习技术提高了零样本top1准确性,比基线MaPLe提高了3.08%。在跨10个数据集的未见类别的跨数据集泛化中,与现有的最先进技术相比,我们的方法在所有数据集上都取得了一致的改进。我们的源代码和模型可以在https://jameelhassan.github.io/promptalign/上找到。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日