
[北邮浙大南洋理工四川电信CVPR 2024论文] 视频异常事件因果关系理解数据集、评价基准和多模态大模型 基本信息 标题:Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly 作者:Hang Du, Sicheng Zhang, Binzhu Xie, Guoshun Nan*, Hehe Fan, Sicong Leng, Daqiu Huang, Jing Feng, Linli Chen, Qimei Cui, Xiaofen Tao et al. 作者所在机构:北邮、浙大、四川电信、南洋理工 发表会议:计算机视觉国际顶级会议CVPR 简介:该论文构建了面向多模态大语言模型的视频异常事件检测及因果描述的数据集和测试基准,提出一种基于提示词的视频多模态大模型微调方法,该成果为首个面向视频大语言模型异常事件理解的测试基准,所设计的微调方法可以在几乎所有多模态开源大模型中应用,如Video-ChatGPT、Video-LLaMA等,可以将这些开源视频模型的异常事件理解性能指标平均提升15%以上,论文、代码以及测试基准已开源。 论文链接:https://arxiv.org/pdf/2405.00181 代码及数据集:https://github.com/fesvhtr/CUVA 研究背景 异常代表了偏离规范、违背预期和偏离常规条件的事件或情景,其典型特征表现为独特性、突发性或罕见性,因此往往需要对其进行特殊的关注或干预。现有的UAV基准和方法主要集中于上述异常检测和异常定位任务,但这些异常事件发生的根本原因和可能造成的相应后果,在很大程度上仍然有待我们探索,它们对我们感知异常并基于人类感知解释做出相关决定发挥着至关重要的作用。如图1展示了一个涉及多车辆的交通事故场景——“事故的发生是因为一辆白色轿车停在路边,而一辆深灰色轿车高速行驶时突然转向与旁边的黑色轿车发生了追尾。”
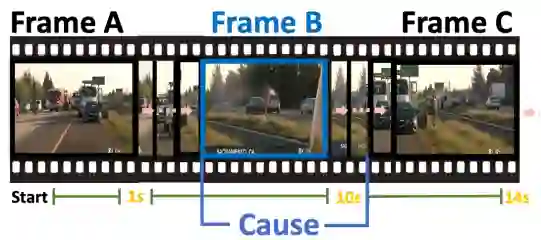
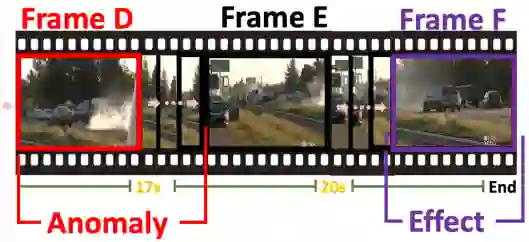
要理解这场事故发生的原因,有以下两个挑战:1)捕捉长视频中的关键线索:事故发生在视频第7秒的帧D时刻,而模型需要识别出事故发生前帧B时刻的白色轿车。捕捉此类远距离相关性对于模型来说是一个挑战。2)建立因果关系的逻辑链:为了建立异常因果关系的逻辑链,模型还需要进一步学习帧B、C、D中包含的丰富相互作用,以便生成解释和结果。上述两种挑战促使我们设计一种专门针对视频异常以上特点的因果关系理解方法。
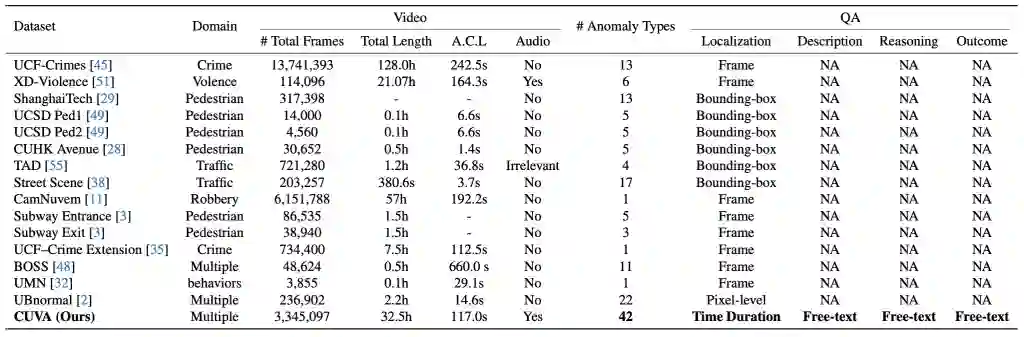
那么对于这两种挑战,以往的VAU基准存在哪些局限性呢?我们发现,虽然以往的VAU基准利用大规模、高质量、挑战性基准可以较好地发展和评估最先进的深度学习VAU方法,但在更加实际的现实应用场景,它们普遍存在以下三种局限性:1)缺乏因果关系解释:现有的注释方法只包含异常发生的时期,而不包括对原因和后果的解释,也不包括对目标异常对描述。2)缺乏合适的评估指标:BLEU和ROUGE分数通常被用来评估视频异常的文本解释/描述,但它们是专门针对文本模态的,并不适合用于评估涉及多种模态的VAU任务。3)对视频长度的限制:在现实世界场景中,很多视频超过了1.5分钟,然而现在的VAU方法通常只针对少于30秒的视频,大大简化了VAU存在的现实挑战。
针对以上局限性,我们提出了一个全面的视频异常因果理解基准CUVA,包含1000个对真实世界视频的高质量注释,其中涵盖10个主要异常类型和42个子类型,每个类型平均包含一个117秒的视频以及覆盖4.3个句子的65.7个token。具体来说,我们手动编写自由文本注释来详细说明异常发生的原因和相应效果、对这些事件的描述以及它们之间对关系。此外,我们还提出了一种全新的评估指标MMEval来评估CUVA基准上各种方法的性能,并进一步提出了一种全新的基于prompt的多模态大模型VLM。实验结果表明我们提出的评估指标和相应方法的先进性。综上所述,此工作的主要贡献可以概括为以下几点:
l我们提出了CUVA,一个全新的因果关系理解基准。据我们所致,CUVA是第一个专注于视频异常因果关系的大规模基准。与以往的数据集相比,我们提出的数据集对于更高质量的注释表现得更加全面并更具挑战性。 l我们提出了一个全新的性能指标,以人类感知角度评估CUVA;还介绍了一个基于prompt的方法来捕捉异常关键线索并建立因果关系逻辑链。 l我们对所提出的CUVA进行了广泛的实验,实验结果表明CUVA能够帮助我们开发和评估各种VLM方法,用于理解现实世界场景中各种视频异常的因果关系。 CUVA基准 下面我们将介绍一些CUVA子任务,并展示我们是如何收集和注释数据的。我们也会给出一些对于基准的定量分析。CUVA基准的概览图如图2所示,与现有数据集的对比如表1所示。

(一)任务定义 发生了什么异常:这个任务包含两个目标,分别是异常分类和异常描述。异常分类包含视频中发生的各种异常类型,类型取自于我们数据库中预先定义的异常种类;异常时刻描述包括异常发生的时间戳以及一段对于异常事件的详细描述。 为什么发生这个异常:这个任务旨在描述视频中包含的异常因果关系。异常原因描述的是视频中各种异常现象发生的原因,这就需要模型基于视频内容对异常原因进行推理并用自然语言进行描述,考验模型对理解和推理能力;异常结果描述了视频中异常事件早场对后果,主要考验模型对于异常事件细节的处理能力。 这个异常的严重程度:这个任务的目的是反应视频中异常严重程度的变化趋势,因此我们提出了一个叫做重要性曲线的注释方法,细节如图3所示。这个方法包含以下三个优势:1)提供了视频中异常严重程度的时间变化的直观表示;2)提供了视频各异常事件之间存在的内在因果关系更加直观的描述;3)这种方法使我们能够在同一个框架下统一各种视频时间基础标记和任务(如时刻检索、亮点检测、视频摘要)。
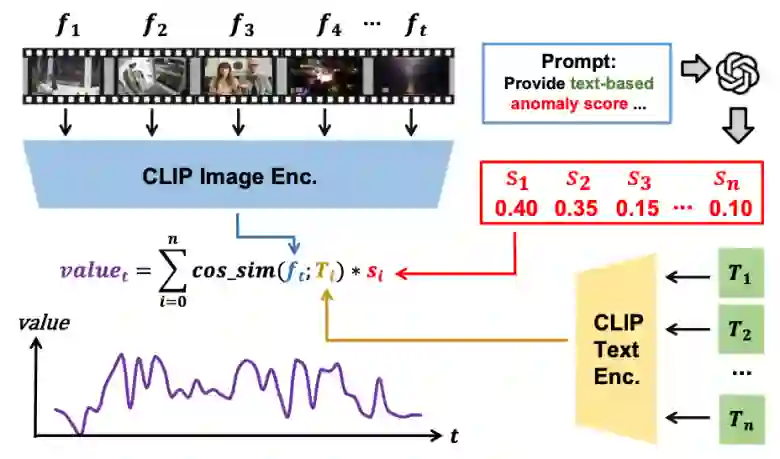
注释者同时考虑之前的任务(如逻辑描述、时刻描述)和视频内容,生成3~6句对视频中所有事件的简短描述。我们通过ChatGPT对这些句子所描述的异常严重性进行排名并获得异常分数。同时我们采样视频帧并使用CLIP来测量句子和帧之间的相似性,由此产生的相似性分数与每个句子的异常分数相乘,即获得每帧的重要性数值。 (二)数据集收集 我们从Bilibili和YouTube等知名视频平台抓取数据,并从中去掉了涉及色情、政治等敏感主题的视频。在整个数据收集过程中,我们对每个类别视频的数量和质量进行了全面分析,最终筛选出了11个类别的异常视频。这些视频被分为11个主要类别,如抢劫、交通事故和火灾。而每个主要类别又进一步细分为子类别,例如我们将火灾类别划分为商业建筑火灾、森林火灾、工厂火灾和住宅火灾这些子类别。按照这种方式,我们总共得到了42个子类别。CUVA数据集的相关统计数据如图4所示。 (三)注释生成方法 我们的注释生成方法包括三个阶段:预处理、人工注释和重要性曲线处理。整个过程需要超过20个注释者花费约150个小时。 预处理:我们首先从Bilibili和YouTube爬取视频数据,然后对收集到的视频进行分割来保证视频内容的质量,并通过人工筛选去掉违背道德的内容以及敏感信息。在整个数据集收集和注释过程中,我们严格遵守网站道德要求,最终得到1000个异常视频片段。 人工注释:我们根据设计的注释文档对视频进行英文注释,注释分为两轮。我们采用了类似kappa的机制对注释者进行筛选和培训,以确保注释内容的一致性。在第一轮中,我们要求注释者根据任务定义对所有视频进行注释,在第二轮中我们要求这些注释者对第一轮的注释结果进行回顾和补充。 重要性曲线后处理:由于CLIP模型能力和采样间隔的局限性,初始曲线可能无法准确地反映异常的时间周期,从而显著影响下游任务的有效性。因此,我们通过以下三个任务来优化重要曲线——视频字幕、视频附件和视频基准。基于这些任务,我们采用了投票机制来精确确定与给定关键句对应的视频时间段。
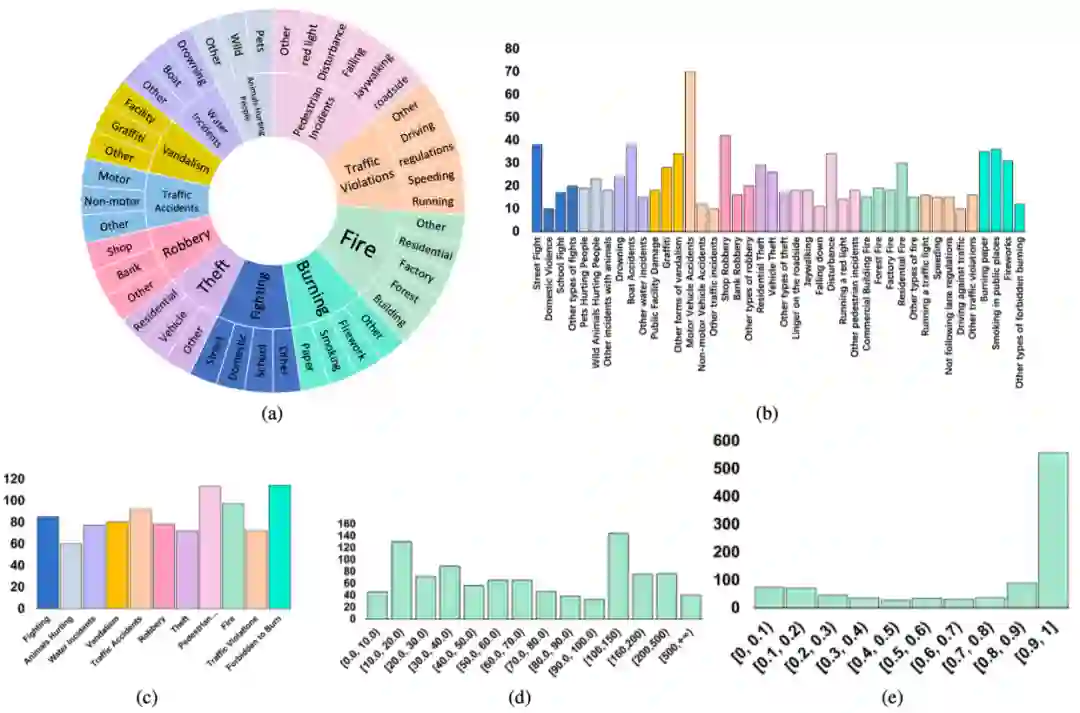
图 4 CUVA数据集的统计数据 我们的CUVA数据集包含1000个视频片段和6000个问答对,视频的总长度为32.46小时,平均帧数为3345,我们以60 FPS的速度从原始视频中提取帧。这些视频涵盖了广泛的领域。然后我们将异常事件归类为11种场景,从而得出总共42种异常类型,如图4 (a)所示。视频类别的分布如图4 (b)和4 (c) 所示,视频长度的分布如图4 (d) 所示,图4 (e)则展示了随着视频异常时间段的时间分布。 提出的方法:Anomaly Guardian 下面我们将介绍一种基于prompy的多模态大模型A-Guardian,这种方法可以解决我们的CUVA数据集提出两个挑战。我们利用VLM的逻辑推理能力来建立因果关系逻辑链。为了有效地捕获长视频的关键线索,我们提出了一种prompt机制来引导VLM更加专注于视频中与问题相关的关键线索。 (一)Hard Prompt设计 我们使用ChatGPT协助确认和补充用户提示,使VLM更好地理解用户的意图。具体而言,我们首先利用一个包含例子的指令提示来纠正错误指导并规范输出格式。由于长视频中包含了大量事件,我们采用了一种多轮对话机制来帮助VLM识别视频中与异常相关的事件。经过多轮对话,VLM可以更加专注于与异常有关的片段,进而给出更加准确的答案。 (二)Soft Prompt设计 我们使用MIST中的选择器来捕捉与问题相关的时空特征,原理如下。我们首先将视频划分为K个片段来统一长度,每个片段又由T帧组成。为了更好地捕捉不同视觉粒度下的关系,我们将每帧又划分为N个块。划分好后,我们利用[CLS] token来代表每个片段和帧。 l我们使用CLIP模型来提取块级别的特征
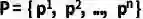
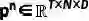
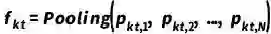
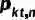
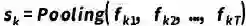
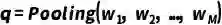
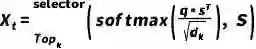
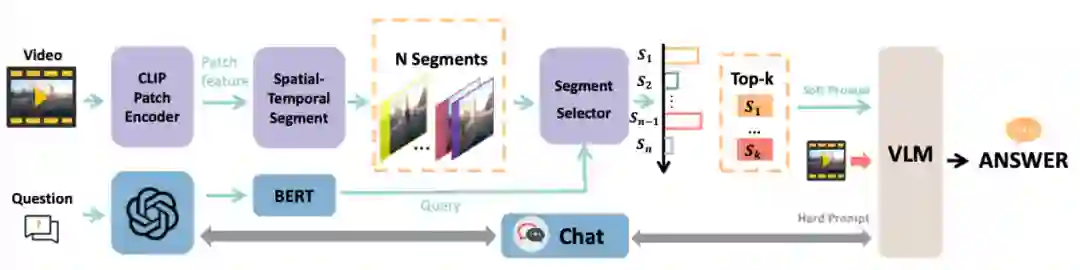
图 5 基于prompt的多模态大模型A-Guardian架构图 实验结果 (一)我们提出的MMEval评估指标 考虑到我们的数据集广泛采用自然语言来描述异常事件及其因果关系,以及CUVA是一个多模态数据集(包含视频、文本和附加的评论),这就需要我们从仅针对自然语言的度量转换为对多模态输入信息的度量。因此,我们引入一个全新的评估指标MMEval,原理如图6所示。
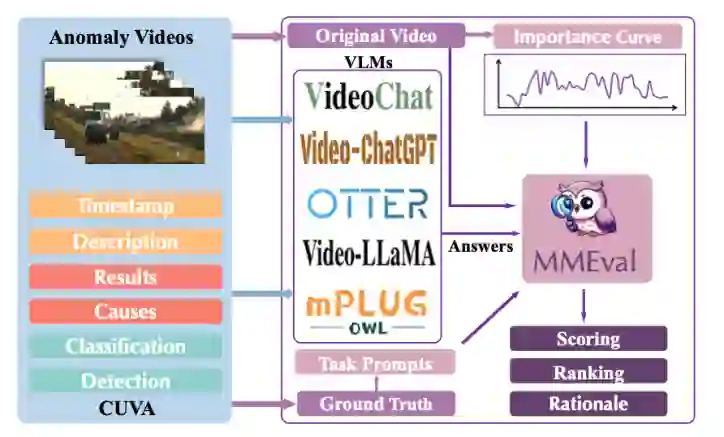
图 6 MMEval评价指标概览图 为了从多模态和人类理解角度评估模型性能,我们选择Video-ChatGPT作为我们的基础模型,并利用自然语言prompt来引导MMEval指定评估任务类型。为了强化模型的鲁棒性,我们还使用曲线标签来帮助VLM更加专注与异常相关的片段,即通过设置阈值来提取曲线中的重要事件周期并对对应的视频段进行密集采样。我们的MMEval评价指标可用于评分、排名和提供原理解释。 (二)MMEval一致性评估 我们的MMEval指标可以更好地与人类对视频异常因果理解的偏好进行对齐。为了验证MMEval与人类判断的一致性,我们实施了人类一致性实验。使用来自第一轮注释、第二轮注释和GPT生成的答案作为基本事实。我们使用各种评估指标和人类感知对这些答案进行排名,结果如表1所示。
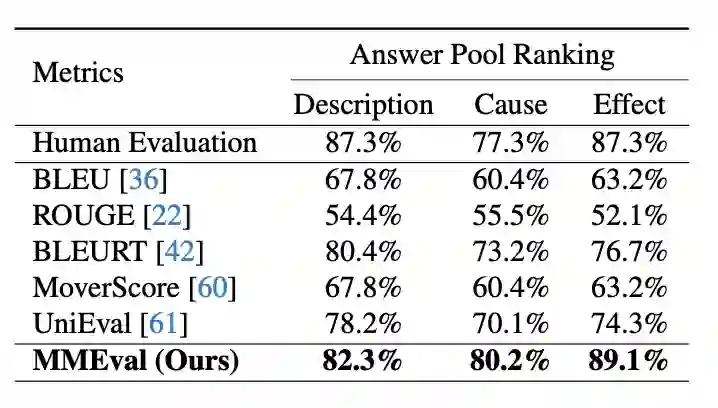
表 2 人类一致性评估
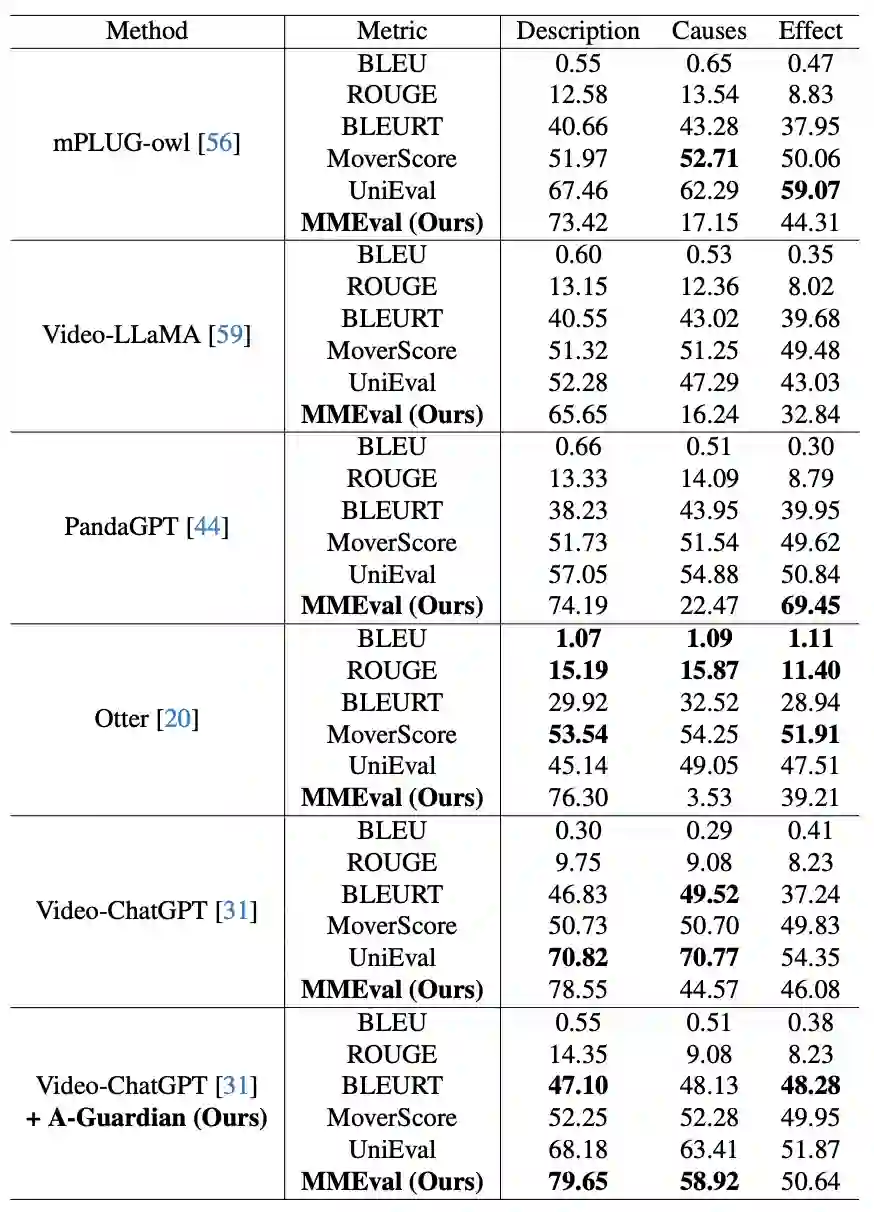
(三)对Anomaly Guardian的定量评估 我们提出对A-Guardian模型可以在描述和原因任务上都达到最先进的表现。我们在我们数据集包含的所有任务上实施了实验,实验结果如表2所示。对于自由文本任务(如原因、后果、描述),我们利用不同评估指标对多种VLM模型和我们的模型进行评估,A-Guardian的性能始终优于大多数模型。
对于其他任务(如检测、分类、时间戳),我们设置统一的prompt并使用字符串匹配从VLM推理结果中提取与问题相关的答案。如表3所示为这些任务上的实验结果。
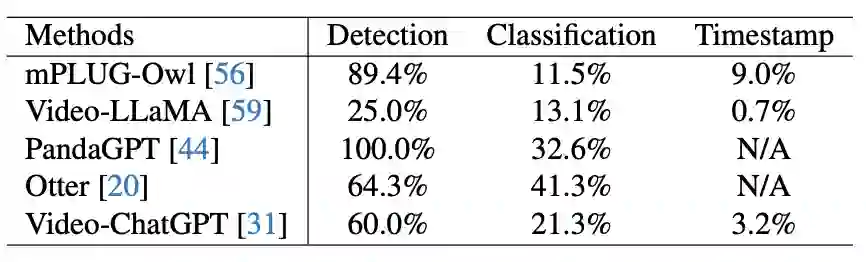
表 4 在CUVA上其他任务的实验结果
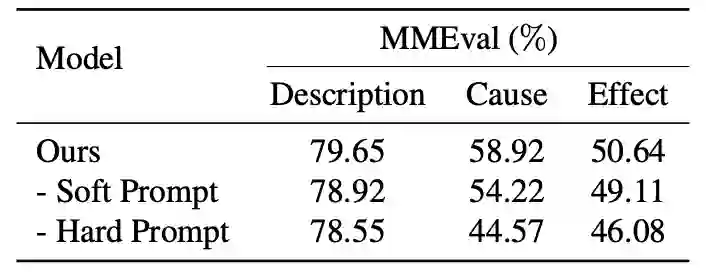
(四)消融实验 Hard prompt和soft prompt都显著提高了VLM对视频因果关系的理解。如表4所示,hard prompt的设计比soft prompt的设计实现了更大的改进,表明hard promot在揭示VLM的推理能力方面比soft prompt更直观有效。
(五)实例分析 如图7所示,我们展示了Otter、Video-ChatGPT和加入A-Guardian的Video-ChatGPT模型对异常现象提供的不同答案。可以看到,Video-ChatGPT提供的描述一般是正确的,但并没有着重描述异常事件部分。而A-Guardian的加入使得模型的描述更加准确——特别强调盗窃是一个异常事件,并对其提供了更详细的描述。 另外,Otter和Video-ChatGPT明明提供了完全不同的描述,但传统的度量标准却对它们给出了相似的评估结果。而MMEval具有多模态评估能力,能够识别出视频中与异常事件相关的片段,进而给出与人类理解高度一致的评估结论。

(六)结果讨论 通过实验,我们得出了以下结论:1)对于自由文本任务,大多数VLM模型在异常描述方面表现出色,但在因果分析方面表现不佳。这是因为描述任务只需要VLM对视频内容进行理解,而因果分析需要VLM对视频内容进行处理,考验VLM的因果逻辑推理能力。2)时间戳定位任务是挑战最大的。由于视频帧之间的时间和空间关系相对简单,VLM在时间戳定位等细粒度任务中表现较差,而在异常检测和分类等粗粒度任务中表现较好。3)传统的评估指标对视频异常相关任务的评估效果较差,而MMEval则能够产生更准确的评估结果。 结论 本文介绍了CUVA,一个对于视频异常因果理解的全新基准,据我们所知为该领域的第一个基准。与现有的数据集相比,CUVA更能满足用户需求,提供更加全面、高质量的注释。我们相信CUVA将促进各种下游任务如异常检测、异常预测、异常推理等的发展。我们还提出了MMEval评估指标,更好地实现与人类理解的对齐。此外,我们还提出了一种基于prompt的多模态大模型A-Guardian,可以作为CUVA上的基线方法来捕捉异常关键线索并建立因果关系逻辑链。实验结果表明,CUVA能够帮助我们发展和评估各种VLM方法。在未来,我们计划将CUVA应用到更实际的场景中,用于异常理解和其他基于VLM的任务。