【CVPR2021】背景鲁棒的自监督视频表征学习

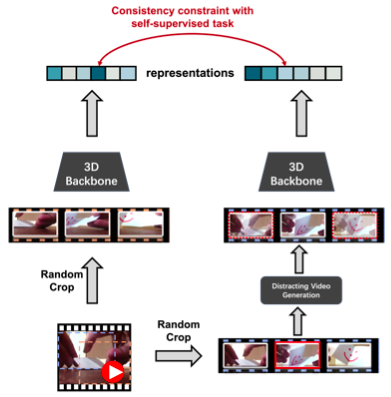
自监督学习通过从数据本身来获取监督信号,在视频表征学习领域展现出了巨大潜力。由于一些主流的方法容易受到背景信息的欺骗和影响,为了减轻模型对背景信息的依赖,我们提出通过添加背景来去除背景影响。具体而言,给定一个视频,我们从中随机选择一个静态帧,并将其添加到其它的每一帧中,以构建一个分散注意力的视频样本,然后要求模型拉近 分散注意力的视频样本与原始视频样本之间的特征距离,如此使得模型能够更好地抵抗背景的影响,而更多地关注运动变化。我们的方法命名为背景消除(Background Erasing,BE)。值得注意的是,我们的方法可以便捷地添加到大多数SOTA方法中。BE在MoCo的基础上,对具有严重背景偏见的数据集UCF101和HMDB51,分别带来了16.4%和19.1%的提升,而对具有较小背景偏见的数据集Diving48数据集带来了14.5%的提升。
https://www.zhuanzhi.ai/paper/14820cc4d73f0a98bb76c67c3cea6c3c
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SVRL” 就可以获取《【CVPR2021】背景鲁棒的自监督视频表征学习》专知下载链接



登录查看更多
相关内容




相关VIP内容
相关资讯