摘要—— 世界建模已成为人工智能研究的基石,使智能体能够理解、表征并预测其所处的动态环境。以往的研究主要聚焦于针对二维图像和视频数据的生成方法,但往往忽视了大量快速发展的工作,这些工作利用原生的三维和四维表示(如 RGB-D 图像、占据网格、LiDAR 点云)来进行大规模场景建模。同时,由于缺乏对“世界模型”的统一定义与分类体系,相关文献中出现了碎片化甚至不一致的论断。本文通过呈现首个专门针对 3D 与 4D 世界建模与生成 的全面综述来弥补这一空白。我们给出了精确定义,并提出了一个结构化的分类体系,涵盖基于视频的 (VideoGen)、基于占据的 (OccGen)、以及基于 LiDAR 的 (LiDARGen) 方法。同时,我们系统性地总结了适用于 3D/4D 场景的数据集与评测指标。进一步地,我们讨论了实际应用,指出了开放挑战,并强调了潜在的研究方向,旨在为推动该领域的发展提供一个连贯且奠基性的参考。现有文献的系统化总结可在 https://github.com/worldbench/survey 获取。 关键词—— 世界模型;视频生成;三维生成;四维生成;三维场景理解;空间智能
1 引言
世界建模已成为人工智能与机器人学中的一项基础任务,其目标在于使系统具备理解、表征和预测其所处动态环境的能力 [1], [2], [3]。近年来,生成建模技术的进步——包括 变分自编码器(VAEs)、生成对抗网络(GANs)、扩散模型(diffusion models)、以及自回归模型(autoregressive models) ——极大地推动了该领域的发展,使得复杂的生成与预测能力成为可能 [4], [5]。然而,这些进展大多集中在 二维数据 上,主要是图像和视频 [6], [7], [8]。而现实世界的场景本质上存在于 三维空间并且具有动态特性,这通常需要能够利用原生 3D 和 4D 表示 的模型,例如 RGB-D 图像 [9], [10], [11]、占据网格(occupancy grids) [12], [13], [14]、以及 LiDAR 点云 [15], [16], [17],以及捕捉时间动态的序列形式 [18], [19]。这些模态显式提供了几何结构与物理约束,对于具身智能体和诸如自动驾驶、机器人等安全关键系统是不可或缺的 [20]–[26]。 除了这些原生格式之外,世界建模也在邻近领域得到了探索 [27]–[29]。一些研究面向 视频、全景图像或网格(mesh)数据,相关系统能够实现大规模、通用的视频-网格生成 [30], [31]。与此同时,另一类研究聚焦于 三维对象生成 以服务资产创建,强调可控性和高保真对象合成 [32]–[34]。与此同时,来自头部企业的工业项目也纷纷启动雄心勃勃的世界建模计划,目标覆盖 交互式机器人、沉浸式仿真 以及 大规模数字孪生 等实际应用 [35]–[40],凸显了该领域在学术界与工业界的重要性。 尽管发展迅速,但“世界模型”这一术语本身仍存在模糊性,在文献中存在不一致的使用方式 [27], [41], [42]。部分研究将其狭义地理解为 针对感知数据(如图像和视频)的生成模型,而另一些研究则扩大范围,涵盖 预测建模、仿真器以及决策框架 [43]–[47]。此外,现有综述大多强调 二维或仅视觉模态 [6], [48],而对 原生 3D 和 4D 数据的独特挑战与机遇 着墨甚少,导致文献呈现出碎片化且缺乏统一框架或分类体系的现象。
为什么原生 3D 和 4D 很重要? 与二维投影不同,原生 3D/4D 信号直接编码了物理作用所在坐标系中的 度量几何、可见性和运动 [18], [49]。它们是可操作建模所需约束的一等公民,包括 多视角与自中心一致性、刚体与非刚体运动学、场景级遮挡推理、地图/拓扑一致性。在安全关键环境中,智能体不仅需要生成照片级真实的帧,还必须遵循 几何、因果性与可控性;RGB-D、占据网格和 LiDAR 提供了满足这些需求的归纳偏置。第 2 节将形式化这些表示及其所依赖的条件信号(Cgeo, Cact, Csem)。
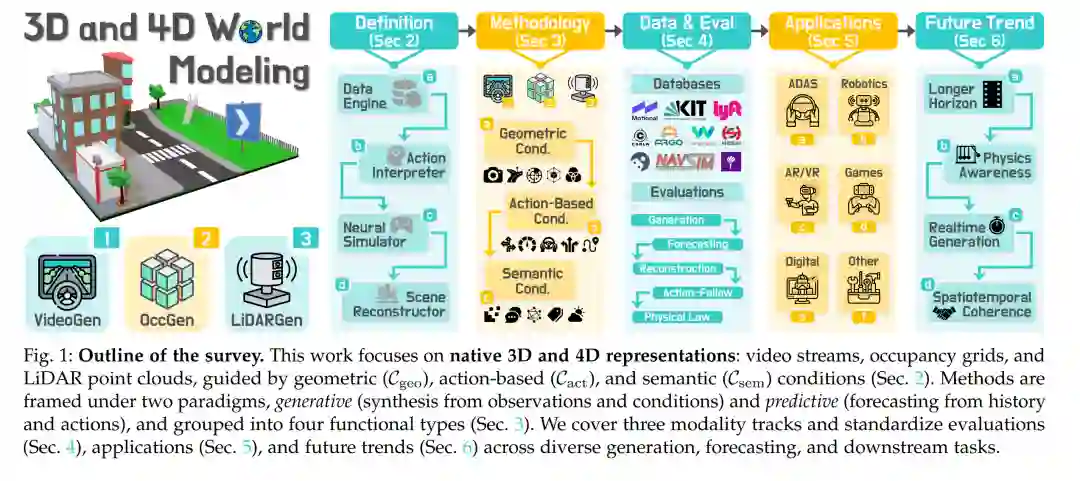
在更广泛领域中的位置。 邻近研究方向——视频/全景/网格世界模型 [30], [31] 与面向对象的三维资产生成器 [32]–[34]——是互补的:前者提供外观、拓扑与资产,后者则提供几何约束下的动态与交互 [19], [50]。实际系统日益将这些能力结合起来:例如,基于资产初始化的网格/全景世界,再由占据网格或 LiDAR 驱动的动态演化,或者由三维先验约束视角与运动正确性的视频模型。本文综述聚焦于后者——原生 3D/4D ——并在必要时与相关研究交叉对比。 * 从条件到功能。 该领域的常见痛点在于混淆了“模型接收的输入条件”(conditions)与“模型的功能作用”(functions)。因此,我们将 几何/动作/语义条件(见表 1)与功能类型区分开来。第 3 节按表示模态(VideoGen、OccGen、LiDARGen)对方法进行组织,并进一步分为四类功能角色:
数据引擎(Data Engines):在 Cgeo, Csem, Cact 条件下实现多样化场景合成; 1. 动作解释器(Action Interpreters):在历史条件下基于 Cact 进行预测; 1. 神经模拟器(Neural Simulators):在策略环路中执行闭环滚动预测; 1. 场景重建器(Scene Reconstructors):基于部分 3D/4D 观测进行补全/重定向。 这种解耦方式使我们能够在 保真度、一致性、可控性和可扩展性 等共同维度上比较异质方法。
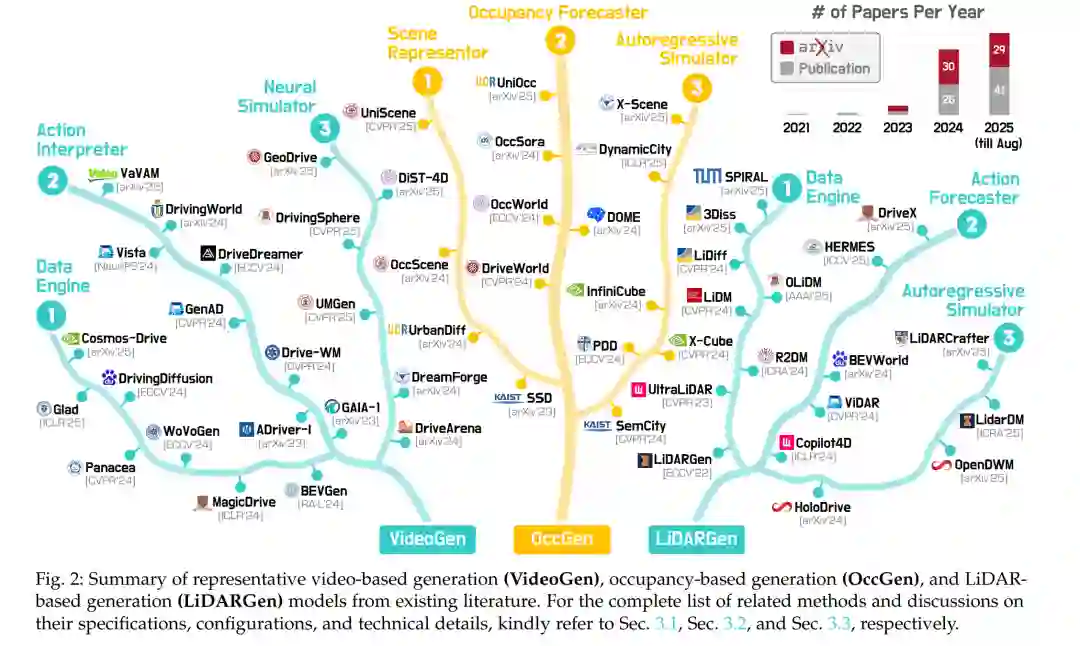
贡献。 为填补上述空白,本文综述提出了首个专门面向 3D 与 4D 世界建模与生成 的全面回顾,主要贡献如下: * 我们为“世界模型”和“3D/4D 世界建模”建立了精确定义,为研究社区提供一致的术语与概念清晰度; * 我们提出了一个分层分类体系,将现有方法按其表示模态归类,即基于 VideoGen、OccGen 和 LiDARGen 的世界建模方法; * 我们全面梳理了专门针对 3D 和 4D 场景的数据集与评测协议,为当前与未来的世界建模与生成方法提供了系统化基准。
研究范围。 不同于以往综述(主要聚焦二维生成模型 [48], [51]–[52],或在有限语境下宽泛定义世界建模 [53]–[57]),本文明确针对 利用原生 3D 与 4D 表示的方法论。这一专门化焦点包括利用 RGB-D、体素占据网格、LiDAR 点云及其时空形式 的方法。通过强调这些模态,我们不仅弥补了关键知识空白,还为研究者开发 鲁棒且可泛化的 3D/4D 生成模型 提供了奠基性参考。 文章结构。 本文余下部分组织如下:第 2 节介绍预备知识,涵盖世界建模的基本概念、定义与关键生成范式;第 3 节提出新的分层分类体系,详细讨论 VideoGen、OccGen 与 LiDARGen 方法,并提供比较分析;第 4 节系统性总结和分类了广泛使用的数据集与评测指标,并对相关方法进行了基准测试;第 5 节回顾 3D 与 4D 世界模型在自动驾驶、机器人、仿真环境中的实际应用;第 6 节讨论主要挑战并指出未来潜在研究方向;最后,第 7 节给出结论。