虽然这些模型在多个领域展示了出色的能力,但它们的指数级扩展也带来了显著的推理时间开销,例如内存需求增加、延迟增加和计算成本上升,从而使高效的部署和服务变得具有挑战性。本文通过全栈方法应对这些挑战,旨在提升人工智能推理栈四个关键组件的效率:模型优化、推理方法、模型架构和应用。在模型优化方面,我们引入了量化技术来优化推理时的计算和内存需求。
I-BERT通过采用仅整数量化来优化计算,这实现了最高3.5倍的延迟加速,并使Transformer架构能够在仅支持整数运算的硬件上部署。SqueezeLLM采用极低位宽的权重量化,有效降低了内存需求,同时在LLM推理过程中不牺牲精度。在推理方法的优化方面,我们提出了Big Little Decoder框架,
这是一种通过小模型和大模型之间的协作加速自回归LLM推理的推测解码框架,能够实现最高2倍的加速。关于模型架构,我们提出了一种高效的语音识别设计,采用了Temporal U-Net结构,
通过缩短输入序列长度来提高推理效率。最后,在应用层面,我们引入了LLMCompiler,
这是一个高效编排LLM应用中多个函数调用的框架,通过将复杂的用户输入分解为更小、更易处理的任务,降低了执行延迟和成本,并提高了系统的鲁棒性。这些贡献共同提供了一种全栈策略,用于优化人工智能模型推理,从低层次的系统到高层次的应用,推动了最先进AI解决方案的高效部署和服务。
人工智能技术在自然语言处理、计算机视觉和语音识别等多个领域取得了前所未有的进展。
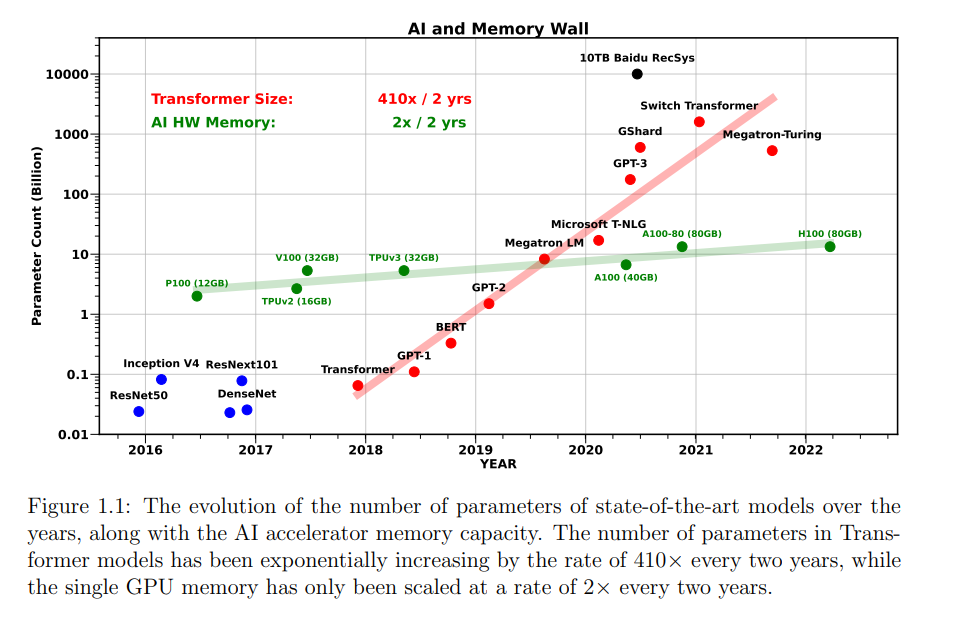
然而,当前普遍采用的扩展模型规模的策略带来了显著的推理时间开销,导致在高效部署和服务最先进模型时面临挑战。例如,如图1.1所示,自2017年引入具有6500万个参数的Transformer架构[266]以来,模型规模呈指数级增长——每两年增长410倍——开启了大型语言模型(LLMs)时代,代表性模型如拥有1750亿参数的GPT-3和其他数十亿参数级的模型。这一增长远远超过了GPU内存的扩展,后者仅每两年翻倍。因此,模型规模的扩展不仅导致了巨大的内存需求,通常超过单个GPU的容量,还引发了延迟、能效和运行这些大型模型的计算成本等方面的挑战。为了解决这一问题并减少人工智能解决方案的运行时开销,全栈优化在人工智能推理栈中的应用至关重要。 如图1.2所示,本文将涵盖提高推理栈中四个关键组件的效率,这些组件分别处于不同的层次:模型优化、推理方法、模型架构和应用。它们涵盖了从面向硬件的底层到面向用户的上层,全面解决从低层系统到高层应用的效率问题。模型优化。
模型优化是通过减少模型规模并更有效地利用底层硬件资源(如计算和内存)来高效部署模型的一种关键方法。常见的技术包括量化,它通过使用低位精度(如8位)而非标准的32位或16位浮点数(即FP32或FP16)来压缩模型的权重和激活值,以及剪枝,它去除模型中不重要的权重。这些方法通常在模型架构设计和训练完成后应用,使得模型能够在显著降低计算和内存需求的同时保持相似的准确性,从而使模型更适用于资源受限的环境。本论文介绍了旨在提高Transformer推理过程中计算和内存效率的量化技术。
在第二章中,我们提出了I-BERT,这是一种通过利用仅整数量化来提高计算效率的方法。通过使用整数算术进行整个推理过程,I-BERT不仅实现了最高3.5倍的延迟加速,还使得Transformer模型能够在仅支持整数计算的硬件上部署。第三章介绍了SqueezeLLM,这是一种通过极低位宽权重量化优化LLM推理中内存效率的量化技术。由于内存操作通常在LLM的自回归生成任务中成为主要瓶颈,SqueezeLLM提供了一种精确的量化策略,通过降低位宽(例如3位或4位)来保持底层权重分布,从而显著降低内存需求,而不牺牲模型的准确性。
推理方法
为了高效服务大规模模型,理解它们的推理动态至关重要,以最小化冗余操作并最大化资源利用率。在第四章中,我们介绍了Big Little Decoder(BiLD),一种旨在解决LLM自回归推理中内存操作低效的推测解码框架。自回归生成通常是内存受限的,因为每生成一个标记都需要执行一个昂贵的内存操作来加载一个大的权重矩阵。因此,减少运行时内存流量是提高推理效率的关键。BiLD通过小模型和大模型之间的协作来解决这一挑战——小模型快速生成多个标记,而大模型间歇性地检查和完善小模型的预测。这种方法使得大模型能够执行非自回归操作,在单次迭代中处理多个标记,从而实现2倍的推理加速,同时不影响生成结果的质量。
模型架构
增强效率的后训练方法,如模型优化和更好的推理方法,由于其在模型设计和训练完成后可以灵活应用,已经变得越来越流行;然而,进一步的效率提升通常需要开发针对特定领域的新型模型架构。这个过程中的一个关键因素是归纳偏置的使用,它在指导模型设计中起着至关重要的作用。归纳偏置[185]指的是学习算法所做的假设,这些假设使得算法能够从有限的训练数据中推广到领域的通用模型。例如,卷积神经网络(CNN)使用局部性作为计算机视觉中图像任务的归纳偏置,展示了领域特定的归纳偏置如何指导更好的架构设计。Transformer模型在提供大量数据时展示了出色的性能,尽管其归纳偏置较少。然而,对于较小的模型或数据相对匮乏的领域,这种方法可能效果不佳。在这些场景中,设计具有强归纳偏置的领域特定架构可以导致更高效、更有效的模型性能,特别是在数据或计算资源有限时。为此,在第五章中,我们提出了一种用于语音识别的更紧凑的架构。通过专注于连续语音信号在时间轴上的冗余,我们提出了一种Temporal U-Net结构,通过有效缩短输入序列长度显著提高了效率。该设计在固定资源预算内提升了语音识别模型的准确性,增强了性能和效率。
人工智能应用
LLM推理能力的最新进展使其潜力超越了内容生成,能够解决更复杂的问题。推动这种问题解决能力扩展的关键因素之一是其功能(或工具)调用能力,使LLM能够调用外部功能并集成其输出以辅助任务完成。LLM的这种集成功能调用的能力促使了LLM应用开发方式的范式转变,推动了代理式应用的兴起。在这些应用中,LLM通过执行动作和通过外部功能收集信息,主动与环境互动,从而使它们能够自主完成用户任务。因此,为了提高这些基于LLM的应用的效率,单纯优化单一模型的效率——无论是通过模型优化、改进推理方法还是更高效的模型架构——是不够的。 同样重要的是要增强LLM与外部功能之间动态交互的效率,从而构建更高效、可扩展和响应迅速的代理式应用。在第六章中,我们介绍了LLMCompiler,它通过将用户输入分解为可执行任务及其相互依赖关系来高效地编排多个功能调用。LLMCompiler通过并行运行独立任务显著减少了执行延迟和成本,同时通过将复杂任务分解为更小、更易管理的任务,增强了任务的鲁棒性。该方法迈出了构建更高效、可扩展的代理式应用的步伐,这些应用能够处理日益复杂的工作流。