现代机器学习主要受到黑盒模型的驱动,这些模型提供了卓越的性能,但对于如何进行预测的透明度有限。对于需要了解模型如何做出决策的应用,以及协助模型调试和数据驱动的知识发现,我们需要可以回答有关影响模型行为的问题的工具。这就是可解释机器学习(XML)的目标,这是一个子领域,它开发了从多个角度理解复杂模型的工具,包括特征重要性、概念归因和数据估值。本文提供了对XML领域的几个贡献,主要思想分为三部分:(i)一个框架,使得可以统一分析许多当前的方法,包括它们与信息论和模型鲁棒性的联系;(ii)一系列技术,用于加速Shapley值的计算,这是几种流行算法的基础;以及(iii)一系列用于深度学习模型的特征选择的方法,例如,在无监督和自适应的设置中。这些思想中的许多都是受到计算生物学和医学应用的启发,但它们也代表了在各种领域中都有用的基本工具和观点。
在模型透明度的辩论中,传统的观点是我们面临解释性与准确性之间的权衡。1有些人辩称这种权衡并不存在,声称我们可以使用“天生可解释”的模型达到近乎最优的性能(Rudin, 2019);这对于简单的表格数据集往往是正确的,但对于像图像和语言这样的复杂数据模态则较为罕见。在这里,我们采取了更为宽容的立场:鉴于黑盒模型目前提供了最佳的性能并且已经广泛部署,我们探讨是否有可能从任何模型中获得足够的见解。在这样做的过程中,我们开发了一套在很大程度上对模型的内部机制持中立态度,或者说是模型不可知的工具集,因此即使在今天的最高性能的黑盒模型中也能正常运行。 这一目标也被可解释机器学习(XML)子领域的许多工作所共享,并且近年来已经取得了显著的进展。目前,XML工具已被用于了解新疾病的风险因素(Razavian等人,2020;Snider等人,2021),加速数学猜想的发现(Davies等人,2021),在有限的训练数据标签下识别蛋白质结合位点(Gligorijević等人,2021),审计有缺陷的医学诊断系统(DeGrave等人,2021)以及从功能系统中获得新的见解(Ting等人,2017;Sundararajan等人,2017)。这些早期的成功表明了这些工具的潜力,但在这些方法的底层理论以及使它们在实践中高效的计算程序方面仍有进展空间。这篇论文介绍了我在博士期间进行的几项工作,旨在解决这些挑战。
这篇论文包含了我在博士期间完成的大部分项目,所有这些项目都与透明机器学习的核心主题相关。我们首先在第2章建立符号和几个初步的概念。接下来,每一章都基于一篇第一作者的出版物,其中在某些情况下与共同第一作者共享。为了使它们在一个文档中更具连贯性,对各个作品进行了修改,但这里没有提供新的信息,这些论文也可以单独阅读。这些作品被组织成三个部分,如下所述。
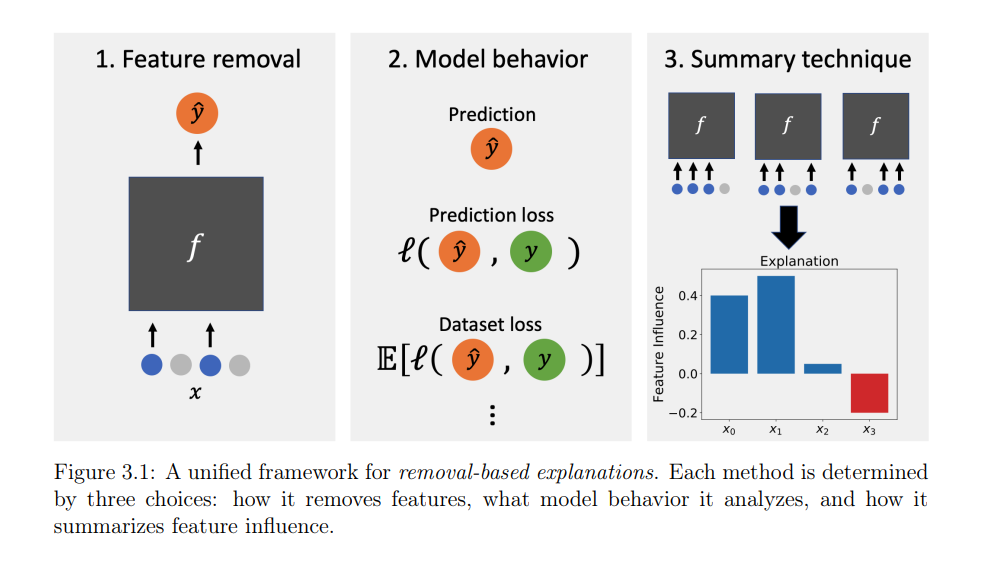
**第一部分:XML的基础 **我们首先讨论一个统一了大部分文献的观点:许多现有的方法都基于一个解释原则,即通过移除或量化从模型中移除特征的影响。我们描述了一个框架,在这个框架中,这些方法基于三个实现选择而有所不同,我们为26个现有的算法确定了这些选择(第3章)。基于这个观点,我们对这些方法进行了统一分析,并找到了与信息理论、博弈论和认知心理学的联系。然后,我们探索这些方法的鲁棒性特性,并得出了描述它们对输入和模型扰动的鲁棒性的新结果(第4章)。 第二部分:Shapley值计算 接下来,我们探讨XML中最广泛使用的工具之一:Shapley值,一种博弈论信用分配技术。这些是最受欢迎的特征归因方法之一,SHAP(Lundberg和Lee,2017)的基础,以及一个著名的数据估值技术(Ghorbani和Zou,2019),但它们是臭名昭著的难以计算。有一系列方法来加速它们的计算(Chen等人,2022),我们在这里讨论两个:基于加权线性回归的近似(第5章),和基于深度学习的摊销优化的近似(第6章,第7章)。 第三部分:深度学习的特征选择 最后,特征选择为提供透明度的同时也降低了特征获取成本提供了另一个方向。由于多次训练不同特征集的模型的高昂成本,似乎很难与深度学习一起实施,但我们探讨了如何使用可微分的层来阻止特征信息进入网络(第8章)。然后,我们讨论如何在自适应设置中应用这些思想,其中我们根据当前可用的信息为每个预测单独选择特征(第9章,第10章)。