该项目旨在利用强化学习(RL)开发防御性无人机蜂群战术。蜂群是一种军事战术,许多单独行动的单元作为一个整体进行机动,以攻击敌人。防御性蜂群战术是美国军方当前感兴趣的话题,因为其他国家和非国家行为者正在获得比美国军方更多的优势。蜂群智能体通常简单、便宜,而且容易实现。目前的工作已经开发了飞行(无人机)、通信和集群的方法。然而,蜂群还不具备协调攻击敌方蜂群的能力。本文使用预先规划的战术模拟了两个军用固定翼无人机蜂群之间的战斗。即使在数量多到100%的情况下,也有有效的战术可以克服规模上的差异。当用于防御舰艇时,这些规划的战术平均允许0到0.5架无人机通过防御并击中舰艇,这超过了阿利-伯克级驱逐舰目前的防御系统和其他研究的无人机蜂群防御系统。这项研究表明,使用某些机动和战术有可能获得对敌人蜂群的战术优势。为了开发更有效的战术,使用RL训练了一种 "智能体 "战术。RL是机器学习的一个分支,它允许智能体学习环境,进行训练,并学习哪些行动会导致成功。"智能体"战术没有表现出突发行为,但它确实杀死了一些敌人的无人机,并超过了其他经过研究的RL训练的无人机蜂群战术。继续将RL落实到蜂群和反蜂群战术的发展中,将有助于美国保持对敌人的军事优势,保护美国利益。
关键词 无人机蜂群战术 强化学习 策略优化 无人机 舰船防御 军事蜂群


引言
现代计算机科学家试图解决的问题正变得越来越复杂。对于大规模的问题,人类不可能想到每一种可能的情况,为每一种情况确定所需的行动,然后为这些行动编码让计算机执行。如果计算机能够编写自己的指令,那么计算机科学的世界可以扩展得更大,以完成更困难的任务。这就是机器学习领域。最近的工作为世界带来了各种照片分类器、计算机视觉、搜索引擎、推荐系统等等。利用机器学习,计算机甚至能够学习和掌握蛇、国际象棋和围棋等游戏。有了这项技术,自动驾驶汽车、智能机器人和自主机械似乎不再是不可能的了。
美国军方一直在推动技术的发展,使其在战术上对敌人有优势。利用机器学习来协助美国作战,将提高军事能力。非传统战争的最新发展催生了无人驾驶车辆和无人机等自主智能体战术蜂群。当务之急是,美国军方必须建立对敌方类似技术的防御措施,并开发出利用蜂群的有利方法。将机器学习方法应用于多智能体无人机群问题,可以为美国军队提供对抗和反击敌人蜂群的能力。
1.1 动机
美国军方一直在探索最新的技术进步,以保持对敌人的竞争优势。蜂群战术是目前军事研究的一个主要领域。美国和其他国家正在寻找使用无人机、船只和车辆与现有蜂群技术的新方法。例如,俄罗斯正在开发令人印象深刻的无人机蜂群能力。[Reid 2018] 伊朗已经创造了大规模的船群。[Osburn 2019] 大大小小的国家,甚至非国家行为者都在利用目前的蜂群技术来增加其军事力量,与美国抗衡。这种对美国安全的可能威胁和获得对其他大国优势的机会是本研究项目的动机。如果美国不发展防御和战术来对付敌人的蜂群,其人民、资产和国家利益就处于危险之中。这个研究项目旨在使用最先进的RL算法来开发无人机群战术和防御性反击战术。研究当前的RL算法,并学习如何将其应用于现实世界的问题,是计算机科学界以及军事界下一步的重要工作。该项目旨在将现有的RL工具与无人机群结合起来,以便找到能击败敌人机群的蜂群战术和反击战术,改进军事条令,保护美国国家利益。
1.2 本报告组织
本报告首先介绍了促使需要无人机蜂群战术的当前事件,以及试图解决的问题的定义。接下来的章节提供了关于无人机、军事蜂群、强化学习以及本研究项目中使用的策略优化算法背景。还包括以前与RL有关的工作,以及它是如何与当前的无人机和蜂群技术结合使用的。下一节介绍了建立的环境/模拟。之后介绍了目前的成果。建立了两个不同的场景,并对每个场景进行了类似的测试。第一个是蜂群对战场景,第二个是船舶攻防场景。这两个场景描述了实施的程序化战术,并介绍了这些战术的比较结果。接下来,描述了RL智能体的设计和RL训练,并测试其有效性。在介绍完所有的结果后,分析了研究发现,并描述了这个研究项目的伦理和未来方向。
军事蜂群应用
无人驾驶飞行器被广泛用于监视和侦查。无人机可以从上面捕捉到战斗空间的状况。这些智能体非常小,可以快速地去一些地方而不被发现。无人机有能力收集信息并回传给蜂群的主机或电子中心。蜂群智能体可以使用信号情报和数据收集战术从敌人那里收集信息。
美国军方和世界各地的军队正在使用蜂群作为一种进攻性威胁。无人机、船只、甚至车辆都可以在无人驾驶的情况下运作,并作为一个单元进行蜂拥,以攻击敌人。大量使用小型和廉价的智能体可以使小型军队在面对美国军队的力量时获得优势。例如,小船或无人机可以汇聚到一艘船上,并造成大量的损害,如摧毁船只的雷达。作为一种进攻性技术,蜂群是强大的资产,可以作为一种进攻性战争的方案来使用。
作为对进攻性蜂群技术的回应,各国军队开始研究并使用蜂群作为防御机制,以对付来袭的蜂群和其他威胁。其他的防御性武器系统并不是为了对抗大量的小型无人机而建造的,因此,发射反蜂群可能是对最新的蜂群战术的一种可行的防御。蜂群也可用于防御单一实体对来袭的武器系统。研究人员正在创造新的方法来建造、武装和训练小型无人驾驶飞行器,以便它们能够成为美国军队的可靠资产。
相关成果
介绍了最近在智能体群体和无人机群的强化学习方面的一些工作。
- 1 用近似策略优化强化学习对四旋翼飞机进行智能控制
Cano Lopez等人使用当前的强化算法来训练四旋翼无人机飞行、悬停和移动到指定地点[G. Cano Lopes 2018]。该系统使用了马尔科夫决策过程,并实现了强化学习的演员评论法,在飞行模拟器中训练智能体。这些强化学习方法与我们希望应用于无人机群战术问题的方法类似。使用Coppelia机器人公司的虚拟实验平台(V-REP)作为模拟,训练无人机飞行。他们的训练策略能够实现快速收敛。在训练结束时,他们能够保持飞行并移动到模拟中的不同位置。这项工作表明,强化学习是训练无人机操作的一种有效方法。我们希望在这个项目中使用的方法可以用目前的技术来实现。我们将扩展本文的实验,在类似的模拟中把RL算法应用于固定翼无人驾驶飞机。然而,我们不是只让无人机飞行和移动,而是要训练它们一起工作,并战略性地计划在哪里飞行和如何操作。
- 2 多重空中交战的协调
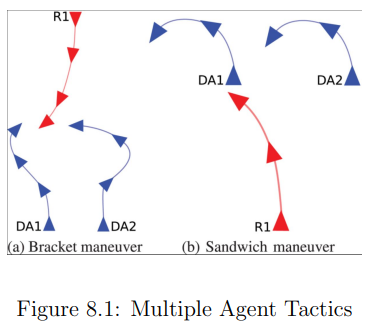
斯特里克兰等人利用模拟来测试各种无人驾驶飞行器的战术,并测试赢得战斗的决定性因素可能是什么。他们对一个具有战术的蜂群进行编程,并让这个蜂群与敌人的蜂群作战。智能体试图使用图8.1所示方法协调对敌方无人机的攻击。只有当有两架无人机对抗一架敌方无人机时,这些战术比单枪匹马射击敌人更有效,而且它们与其他成对的无人机之间有足够的空间。其次,一些特工会飞离敌人,作为保护自己的手段,从不对敌人使用任何攻击性战术。[Strickland 2019]
- 3 多智能体交互中的涌现工具使用
这个项目使用PPO在一个捉迷藏的游戏中使用强化学习来训练多个智能体。两个红色智能体是一个团队,被指定为寻找者,两个蓝色智能体是一个团队,被指定为隐藏者。如图8.2所示,这些智能体在一个有几面墙和一些积木的开放环境中游戏。智能体可以跑来跑去,对可移动的积木施加压力。红队在看到蓝队时得到奖励,蓝队在未被隐藏时得到奖励。两个智能体都是用自我发挥和策略优化算法进行训练的。两队进行了数百万次的训练迭代竞争,并制定了战术和技术来对付对方的行动。起初,两个团队都是漫无目的地跑来跑去,但他们最终发展出一些智能行为来帮助他们获得奖励。蓝队学会了如何堵住门,为自己创造庇护所,并从红队那里藏起其他物体。红队追赶蓝队特工,利用斜坡潜入他们的庇护所,跳到积木上面看墙。这些特工制定的一些战术甚至比人类程序员指示他们做的更有创意。最重要的是,这些智能体教会了自己如何合作,并为每个智能体分配一个特定的角色,以完成团队目标。这项研究的结果显示了强化学习和自我发挥的学习方法的力量。两个智能体都能发展出智能行为,因为它们之间存在竞争。我们将使用这个项目的框架来解决我们的无人机蜂群战术问题。将捉迷藏游戏扩展到无人机群战,将提高强化学习的能力。自我游戏技术在本项目未来工作的RL蜂群对战部分有特色,该部分详见第13.3节。[Baker 2018]

- 4 用自主反蜂群应对无人机群的饱和攻击
在这项研究中,研究人员利用计算机编程和强化学习模拟并测试了无人机群战术。该小组创建了一个可能的蜂群战术清单,包括一个简单的射手,一个将敌人引向队友的回避者,以及一个将敌人的蜂群分成子蜂群的牧羊人。研究人员随后创建了一个模拟器来测试这些战斗战术。他们收集了关于哪些战术最有效的数据,甚至在现实生活中的固定翼无人机上测试了这些算法。我们将在研究的第一阶段实施其中的一些战术,并扩大目前可编程蜂群战术的理论。
这篇研究论文的第二个方面是实施强化学习方法,使智能体能够制定自己的蜂群战术。盟军无人机在杀死敌方无人机时获得正奖励,被敌方杀死时获得负奖励。敌方蜂群是用研究第一阶段的成功单人射手预先编程的。这个项目的目标是让智能体制定对抗敌方蜂群的战术。然而,盟军的无人机学会了应该逃跑,干脆飞离敌人,以避免被杀死的负面奖励。因为敌人太有效了,盟军无人机无法获得足够的正向奖励来学习如何攻击敌人的蜂群。我们将使用强化学习以类似的方式来训练智能体,然而我们希望获得更多的结论性结果。为了防止盟军无人机逃离敌人,我们将对攻击和杀死敌人的智能体给予比死亡风险更多的奖励。我们还可以对智能体进行编程,使其保卫像船只或基地这样的资产。这个研究项目为我们所做的研究提供了一个良好的基础。[Strickland, Day, et al. 2018]。
美国海军学院先前的工作
该研究项目是近期强化学习和无人机群工作的延续。计算机科学领域一直在开发最先进的强化学习算法,如PPO和SAC,该项目旨在应用于当前的无人机群战术的军事问题。
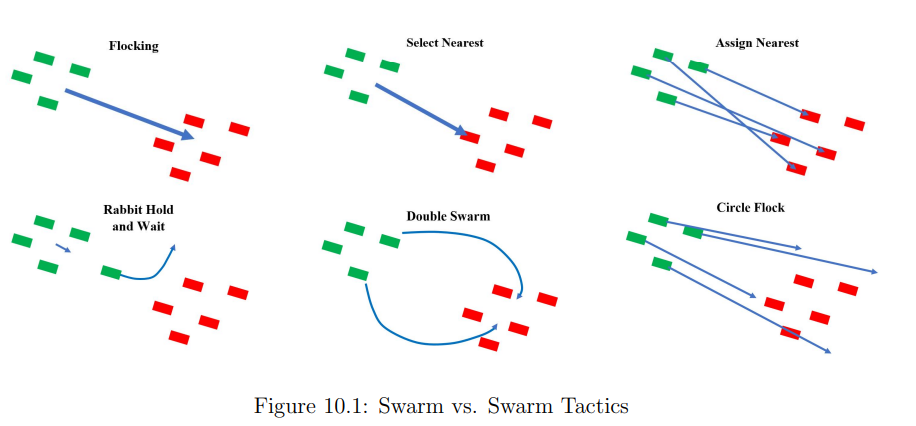
MIDN 1/C Abramoff(2019级)研究了无人机蜂群战术,并在Python中模拟了微型蜂群对蜂群战斗。他创建了一个二维空间,用一个点代表蜂群中的每个特工。每个智能体可以向前射击(在它移动和面对的方向)。被另一个智能体的 "子弹 "击中的智能体被假定为死亡,并从模拟中删除。阿布拉莫夫创建了蜂群,并编写了一个蜂群算法,以便特工能够作为一个整体蜂拥飞行,而不会发生碰撞、分离或破坏蜂群。一旦智能体真实地成群,阿布拉莫夫探索了各种无人机群战术,如选择-最近和分配-最近,并测试了它们对敌人群的有效性。选择-最近 "允许每个特工瞄准离自己最近的敌人。当蜂群向对方移动时,智能体将根据每个时间点上哪个敌人的无人机最近而改变其目标。分配最近的任务给每个智能体一个任务,以消除一个不同的敌方无人机。任务是根据哪个敌方无人机离友军蜂群最近来决定的,并在每一帧重新更新。阿布拉莫夫对两个蜂群的模拟战斗进行了实验,以测试哪种蜂群战术最有效。他还尝试使用反蜂群战术进行战斗,如在蜂群前面派出一个 "兔子 "特工,并分成子蜂群。总之,阿布拉莫夫发现,在他的实验中,"最近分配 "是最有效的,一些反蜂群战术也很成功。这些结果不是结论性的,但显示了在发展蜂群和反蜂群军事战术方面的进展。本研究提案将在MIDN 1/C Abramoff的工作基础上进行扩展,创建一个3-D环境模拟,并改进智能体能力,以代表一个现实的无人机群战。这个研究提案的环境将有一个更大的战斗空间,智能体可以采取更多的行动,包括改变高度、武器瞄准和蜂群间的通信/团队合作。
MIDN 1/C汤普森(2020级)建立了一个三维环境,他用来模拟更多战术。这个环境比MIDN 1/C阿布拉莫夫使用的更真实地模拟了现实世界的战斗空间。蜂群要在三维空间中自由移动,并根据现实世界的物理学原理采取相应的行动,即重力和高度以及飞机上可行的转弯率。图8.3显示了汤普森的Python环境模拟。左上角的无人机群被染成蓝色,代表盟军的无人机群。右下角的无人机群为红色,代表敌人的无人机群。尽管在二维显示中,每架无人机周围的圆圈代表高度。在图8.3中,更大的圆圈显示了更高的高度,这意味着敌人的蜂群比盟军的蜂群要高。MIDN 1/C汤普森固定了环境的三维方面,并将无人机融入该空间。他还研究了每架无人机的转弯率,以确保模拟符合现实生活中的无人机规格。

蜂群vs蜂群场景
模拟开始时有两个由任何数量的无人机组成的蜂群。每队的无人机都被初始化在比赛场地各自一侧的随机位置上。模拟开始时,两队都起飞了。每队都执行给定的战术,可以是预先编程的,也可以是智能体学习的。如果进行了多轮比赛,每队的胜负和平局都会被计算在内。
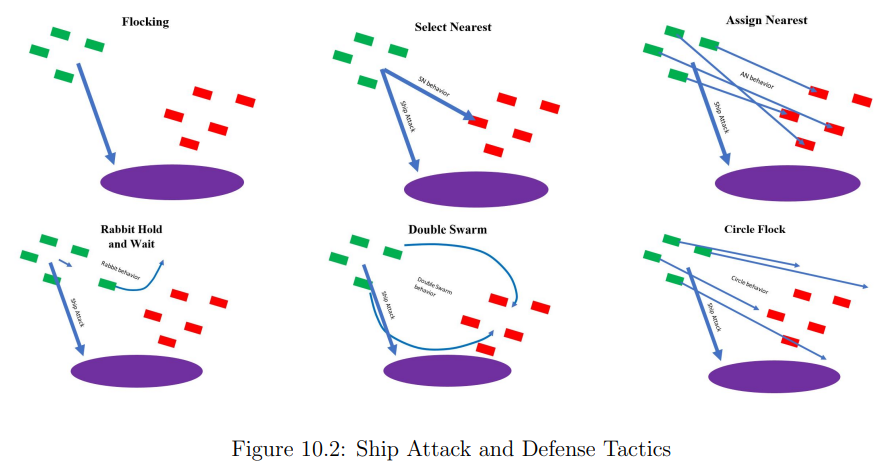
舰艇攻击和防御场景
模拟开始时有两个任意数量的无人机群。防御队被初始化在放置在比赛场地中心的飞船中心。这艘船是静止的,不会还击,但它会计算它所收到的无人机的数量。进攻队被初始化在比赛场地的一个随机位置,该位置距离飞船中心至少有200米。模拟开始时,两队都要起飞。每队都执行给定的战术,可以是预先编程的,也可以是智能体学习的。如果进行多轮比赛,每队都要计算无人机击中飞船的总次数和剩余的防御性无人机数量。