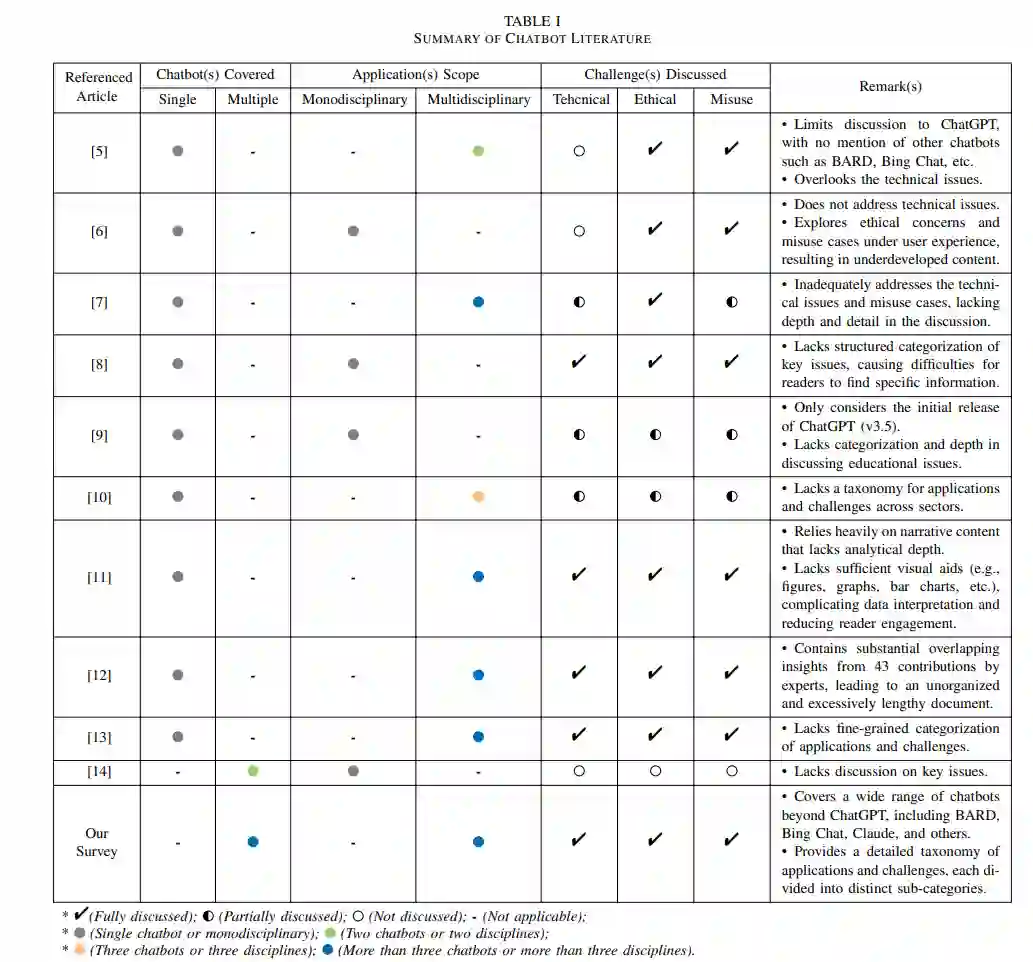
过去几十年里,数据量激增,为依赖数据的学习型AI技术奠定了基础。对话代理(通常称为AI聊天机器人)在很大程度上依赖这些数据来训练大型语言模型(LLM),并在响应用户提示时生成新的内容(知识)。随着OpenAI的ChatGPT的问世,基于LLM的聊天机器人在AI社区中树立了新的标准。本文对基于LLM的聊天机器人的演变和部署进行了完整的综述。我们首先总结了基础聊天机器人的发展历程,接着是LLM的演变,然后概述了当前使用中的以及开发阶段的基于LLM的聊天机器人。鉴于AI聊天机器人作为生成新知识的工具,我们探讨了它们在各个行业的多样化应用。随后,我们讨论了开放性挑战,考虑到用于训练LLM的数据以及生成知识的滥用可能引发的诸多问题。最后,我们展望了未来,以提高它们在众多应用中的效率和可靠性。通过梳理关键里程碑和当今基于LLM的聊天机器人的现状,我们的综述邀请读者深入探讨这个领域,反思下一代聊天机器人将如何重塑对话式AI。
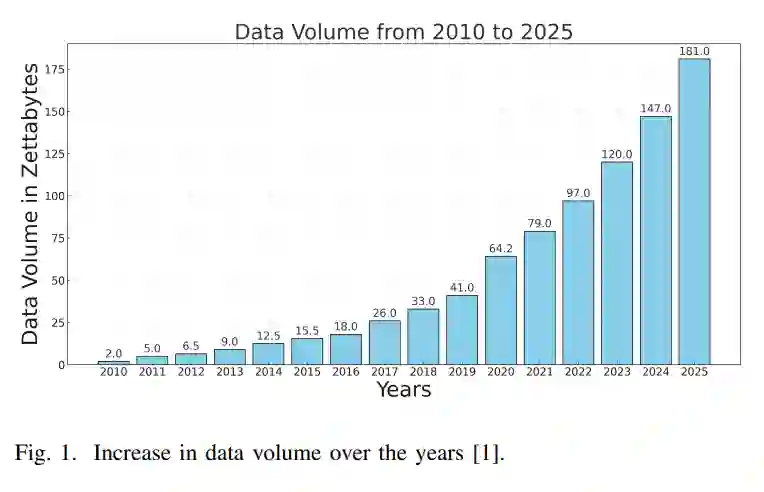
近几年,数据的指数级增长改变了数字信息的世界。2023年,全球创建、捕获、复制和消费的数据总量约为120泽字节,预计到2024年将达到147泽字节,到2025年将超过180泽字节【1】。图1展示了2010年至2023年数据量的增加情况,并预测了2024年和2025年的数据量。这一数据生态系统的快速扩展为人工智能(AI)领域的突破性创新铺平了道路,促成了多种机器学习模型的发展。其中,大型语言模型(LLM)由于其在理解、生成和处理人类语言方面的卓越能力而成为一个重要的子集【2】。
在AI驱动的聊天机器人时代【15】–【17】,LLM在推动对话能力和实现类人互动方面发挥了关键作用【2】【7】。数据的显著增长和计算知识的进步提高了基于LLM的聊天机器人的功能,使其在各个领域变得越来越受欢迎和广泛采用。它们在理解和回应人类语言时所具备的前所未有的上下文相关性和准确性,以及处理大量信息流的能力,使其成为教育【18】–【20】、研究【21】–【23】、医疗保健【8】【24】【25】等诸多领域的必备工具。鉴于基于LLM的聊天机器人的巨大潜力和前景,其不断增长的使用量和必要的优化带来了诸多挑战,需要进行深入的研究和评估。随着基于LLM的聊天机器人领域的快速扩展,学者、专业人士和新手都面临着大量的研究文献。因此,我们的工作为应对这些不断变化的需求提供了一份及时且完整的基于LLM的聊天机器人的综述。
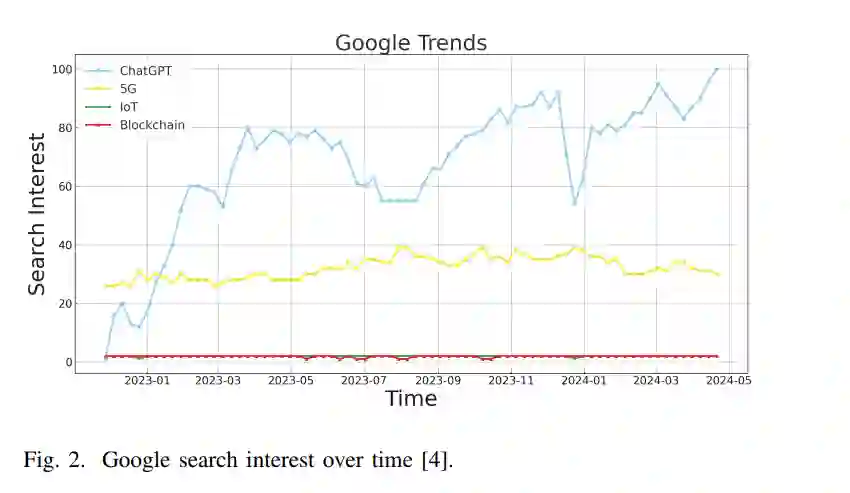
在LLM和基于LLM的聊天机器人出现之前,对话式AI面临着诸多挑战。早期的聊天机器人在上下文理解和领域特异性方面有限,往往提供不准确的回应。缺乏复杂的语言理解限制了它们进行类人交互的能力,导致用户体验显得机械化和不连贯。在各个行业的可扩展性也存在问题,因为处理大量信息流并实时响应是个挑战。LLM的出现彻底改变了聊天机器人,并开启了AI驱动的交互新纪元。2023年3月,OpenAI推出了其最新的杰作GPT-4(也称为ChatGPT Plus【29】),继2022年11月ChatGPT 3.5首次亮相以来引发的热议之后【30】【31】。图2展示了自初次发布以来ChatGPT(蓝色)的人气指数,其相比于其他广泛使用的技术(如黄色的5G、绿色的物联网和红色的区块链)具有明显优势。其创新能力引发了前所未有的人气激增,标志着AI驱动通信的新篇章。在相关发展中,谷歌于2023年2月6日宣布推出其首个基于LLM的聊天机器人BARD【32】,并于3月21日提供早期访问【33】。此外,还有许多其他基于LLM的聊天机器人正在开发中。鉴于这些技术的深远影响,本文综述旨在提供关于基于LLM的聊天机器人的发展、行业应用、主要挑战以及提高其有效性和可靠性的策略的精简且最新的概述。我们的目标是将这些多样化的研究整合成一篇结构合理的综述,以便深入理解基于LLM的聊天机器人,并为读者提供未来研究的指南。
A. 现有综述、评论和案例研究
多篇文章回顾了基于LLM的聊天机器人的广泛应用,突出了它们的重大影响和在各个领域所带来的复杂挑战。本文将讨论其中的一些文章,并展示我们的综述如何扩展和区别于它们。
【5】探讨了AI和聊天机器人在学术领域的使用及其对研究和教育的伦理影响,研究了这些技术对教育评估完整性的影响及其转变学术研究的潜力,并提出了有效解决方案以缓解教育和研究领域的伦理挑战和可能的滥用问题。
【6】通过案例研究探讨了ChatGPT如何提升在线学习。研究结果表明,学生们更倾向于使用这些代理来进行教育活动,认为其提供了更互动和更有吸引力的学习环境。Koubaa等【7】详细审查了ChatGPT的技术创新,并在他们的综述中开发了一种独特的分类法,用于研究分类,探索了ChatGPT在各个领域的应用。此外,他们还强调了显著的挑战和未来探索的方向。【8】系统性地回顾了ChatGPT在医疗保健中的应用,重点关注教育、研究和实践。作者概述了ChatGPT在科学写作和个性化学习中的革命性潜力,同时批判性地分析了其优点,并承认存在的重大问题,如伦理和准确性问题。另一篇评论文章【9】评估了ChatGPT在教育中的影响,指出其在经济学、编程、法律、医学教育和数学等学科中的不同表现。文章突出了这一工具的潜力和挑战,如准确性问题和抄袭,并建议更新评估方法和教育政策,以负责任地使用这些工具。【10】的作者通过虚拟和面对面的反馈进行了一项探索性调查,分析了ChatGPT在教育、医疗保健和研究中的影响。调查显示,ChatGPT可以提高个性化学习、临床任务和研究效率。他们还解决了主要的伦理和实际问题,建议在部署AI时要谨慎并遵循严格的伦理指南以应对这些挑战。同样,【11】对ChatGPT进行了全面分析,重点关注其演变、广泛应用和主要挑战。与【10】通过调查直接获取反馈不同,【11】通过汇总现有研究的发现来评估ChatGPT的影响和挑战,提供了更普遍的视角,而不涉及初级数据收集。进一步探讨,【12】和【13】深入研究了ChatGPT的广泛跨学科应用。【12】汇集了多个学科的见解,评估了其在市场营销、教育和医疗保健等领域的影响,而【13】则引入了ChatGPT研究的分类法,详细介绍了其在医疗保健、金融和环境科学等领域的应用。此外,这两篇文章都讨论了伦理考虑和实际部署方面的基本挑战。另一篇近期文章【14】通过单一案例研究方法评估了ChatGPT和Bing Chat在化学教育中的有效性。研究分析了这些工具与模拟学生之间的广泛互动,以提高创造力、解决问题的能力和个性化学习。研究结果显示,两者都是有价值的“思考代理”,但ChatGPT在提供更全面和上下文相关的回应方面明显优于Bing Chat。
与现有工作不同,我们的综述不仅关注具体的聊天机器人,还涵盖了包括BARD、Bing Chat和Claude在内的各种模型。此外,我们探索了多个领域的应用,讨论了各种挑战,每个挑战都详细分类。表I总结了所讨论文章的发现,便于对其贡献进行比较理解。
B. 我们的贡献
我们的综述旨在回答以下问题:
-
聊天机器人如何从简单的自动化系统发展到今天的基于LLM的变体?LLM的基础性进步如何自LLM时代之前重新定义了聊天机器人的能力?
-
基于LLM的聊天机器人在不同领域的关键应用是什么?它们如何影响这些领域的运营动态和用户交互?
-
基于LLM的聊天机器人的广泛使用带来了哪些挑战?这些挑战如何影响其性能和可靠性?
-
基于LLM的聊天机器人需要哪些技术改进?如何通过实施伦理指南确保其负责任的使用? 在回答这些问题时,我们提供了对聊天机器人历史的全面概述。此外,我们讨论了LLM的基础知识,重点介绍了基于Transformers的自注意力机制和GPT模型中的创新特性,如上下文学习和链式思维(CoT)提示。接着,我们提供了基于LLM的聊天机器人的详细分类,按其在教育、研究和医疗保健等领域的功能和应用进行组织。我们还承认它们在软件工程和金融中的日益重要性。接下来,我们从技术方面探讨了开放性挑战,涵盖了知识的时效性问题以及幻觉等问题,同时还考虑了数据透明度、偏见、隐私风险和不公平等伦理问题。然后,我们从学术滥用、过度依赖和错误信息传播等角度探讨了滥用问题。最后,我们讨论了基于LLM的聊天机器人的未来展望,从技术改进如模型优化到遵循伦理指南和在各个领域推广负责任的使用。我们的贡献总结如下:
-
与大多数专注于特定聊天机器人或其有限方面的文章不同,我们的综述涵盖了多种基于LLM的模型,包括ChatGPT、BARD、Bing Chat等。
-
虽然大多数文章专注于单个聊天机器人在一个或多个领域的应用,而没有详细分类,但我们的综述扩展到多个应用领域的各种聊天机器人。我们提供了详细的应用分类法,结构化且深入地探索了不同聊天机器人在教育、研究、医疗保健、软件工程和金融等领域的表现。
-
我们从技术、伦理和滥用角度讨论了若干开放性挑战。此外,我们围绕知识和数据这两个LLM的核心支柱构建了讨论。这种方法展示了聊天机器人与广泛训练数据的交互及其后续生成新内容(知识)之间的动态关系。 综述的其余部分安排如下:第二部分介绍了聊天机器人的基础年、LLM的兴起及基于LLM的聊天机器人的概述。第三部分重点介绍了这些聊天机器人在教育、研究和医疗保健中的应用,还涵盖了软件工程和金融等杂项应用。第四部分探讨了这些聊天机器人固有的挑战,第五部分探索了该领域的未来展望。最后,第六部分总结了综述的主要发现和整体贡献。图3展示了我们综述的提纲。