

人工智能(AI)经过几十年的发展,在技术和研究上都取得了重大进展,并被广泛应用于计算视觉、自然语言处理、时间序列分析、语音合成等众多领域。在深度学习时代,特别是在大型语言模型的出现下,大多数研究者的注意力都集中在追求新的最先进(SOTA)的结果上,这导致了模型大小和计算复杂性的不断增加。对高计算能力的需求带来了更高的碳排放,并通过阻止资金有限的小型或中型研究机构和公司参与研究,破坏了研究的公平性。为了应对AI的计算资源和环境影响的挑战,绿色计算已经成为一个热门的研究话题。在这次综述中,我们对绿色计算中使用的技术进行了系统性的概述。我们提出了绿色计算的框架,并将其分为四个关键组成部分:(1) 绿色性的衡量、(2) 节能AI、(3) 节能计算系统以及(4) 用于可持续性的AI应用案例。对于每个组成部分,我们都讨论了已经取得的研究进展以及为优化AI效率常用的技术。我们得出的结论是,这个新的研究方向有潜力解决资源限制与AI发展之间的冲突。我们鼓励更多的研究者关注这个方向,使AI变得更加环保。
https://www.zhuanzhi.ai/paper/ce8ba40c06f87f2efbd8a4563d358b07
人工智能(AI)旨在模仿人类的认知能力,并在不同程度的自主性下执行任务。这涉及到问题解决、学习、推理、知觉和语言理解等过程[1]。经过几十年的发展,AI在技术和研究上都取得了重大进展。而近年来,为了应对AI的计算资源和环境影响的挑战,绿色计算已经成为一个热门的研究话题[2, 3, 4, 5]。在本章中,我们分析AI的研究和开发(R&D)趋势,讨论为什么我们需要绿色计算,并给出这次综述的大纲。
1.1 人工智能的研究和开发(R&D)趋势
AI的早期阶段主要基于符号、逻辑理论和专家规则来模仿人类的决策,这需要大量的人力努力。随着机器学习的崛起,特别是神经网络,AI进入了深度学习的阶段,在这个阶段,计算机从数据中学习,而不是明确地编程[6]。深度学习使AI系统能够自动地从大量数据中学习并提取抽象特性或表示,因此需要更多的计算资源和训练数据,但少了人的参与。由于深度学习现在在学术界和工业界都被广泛采用,我们将重点介绍AI的深度学习阶段,并总结其R&D趋势如下:
研究者更加关注准确性与效率
在最近的AI社区中,公开的数据集/基准测试上报告的结果已经成为了展示工作贡献的广泛接受的方式。为了分析公开基准上的研究趋势,我们从PepersWithCode1中收集了数据。截至2023年10月,总共有超过11k的基准测试,如图1(a)所示,超过一半的任务有超过100个基准测试。以ADE20K这个图像分割基准为例,我们统计了每年(2014-2023)报告该基准测试结果的论文数量。如图1(b)所示,从2021年开始,针对这个基准测试的论文数量明显增加。为了找出大多数研究者正在瞄准的具体指标,我们随机抽取了4个CV和NLP的任务,对于每个任务,我们选择了5个常用的数据集/基准测试。对于每个基准,我们统计了报告与准确性(如IoU、Accuracy、F1、EM、BLEU score等)或效率(如GFLOPs、所用时间、参数数量等)相关指标的模型数量。从表1的结果可以看出,超过80%的论文报告了与准确性而非效率相关的指标。而且有10/20的基准测试没有效率指标报告。这个结果表明,研究社区的常见兴趣是瞄准像准确性这样的性能指标,而忽略了像执行时间、模型大小等基于效率的性能。
模型的大小和复杂度持续增长
近年来,由于硬件和计算能力的进步,模型的大小和复杂度都呈快速增长趋势。如前一个趋势所提到的,大部分的研究努力都集中在推动公共基准上的性能(如准确性)的极限,尤其是取得新的最先进(SOTA)结果。由于增加模型的大小和复杂度是一种简单且有前景的方法来提高模型的性能,研究者们倾向于使用这种方法在公共基准上取得更好的成绩。我们以MMLU2为例,这是NLP的一个多任务语言理解基准。如图2所示,GPT-3(175B)达到的分数是GPT-2(1.5B)的1.5倍,而Flan-PaLM(540B)达到的分数是2.3倍。但如果我们考虑参数的数量,Flan-PaLM(540B)与GPT-2(1.5B)相比,参数增加了360倍。
虽然这些大型模型在准确性方面展示出有前景的结果,但它们的能源和碳足迹也以指数级增长。这对AI从业者来说是一个重要的考虑因素。例如,由OpenAI开发的模型AlexNet有6000万个参数,但现在,一种称为GPT-4的大规模文本生成模型有1.8万亿个参数,在短短6年内增加了30,000倍。图3描绘了从2012年到2023年模型参数的迅速增长。根据Kasper Groes Albin Ludvigsen(2023)的数据,最新版本的生成预训练转换器GPT-4,参数为1.8万亿,如果在加利福尼亚的普通电网上进行训练,可能会排放12,456至14,994公吨CO2e,而拥有175B参数的GPT-3可以排放近500M的碳。 根据[2],我们将上述趋势归类为红色计算(Red Computing),在这种趋势中,研究者们优先考虑通过利用大量的计算资源来增强在基准上的准确性(或类似的指标),常常以忽略成本考虑为代价,从本质上来说是"购买"更高的性能,或者在排行榜上获得新的最先进(SOTA)。然而,这种方法有几个缺点,其中之一是能源消耗和碳排放不断增加。如[2]所示,如果我们继续增加模型的复杂性,如参数的数量,将会得到模型性能的边际回报递减。当我们进入大型语言模型(LLM)的阶段时,模型的大小开始更快地增加。根据[7]的统计数据,一个有1760亿参数的语言模型BLOOM的训练总共需要1,082,990小时的GPU训练时间,消耗433,196 kWh的能源,并排放约50.5吨的CO2eq。BLOOM的API在推理时间部署每天大约排放19公斤的CO2eq。由于大多数像Llama2[8]、PaLM[9]和BLOOM[10]这样的大型模型在训练时都需要NVIDIA A100或同等水平的高计算能力的GPU,因此小型和中型的研究机构或公司由于资金或计算能力有限,常常在参与研究时面临困难,这阻碍了整个社区的发展。
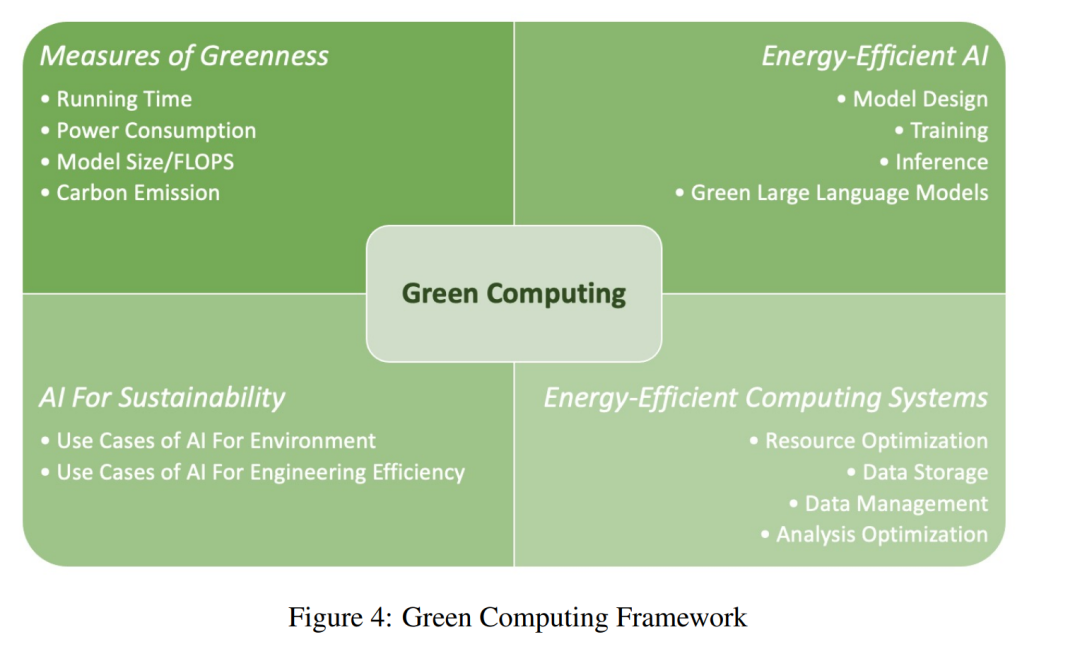
1.2 绿色计算
红色计算(Red Computing)的方法已经通过推动AI的边界取得了重大进展,但它也对环境和自然资源构成威胁。根据Gartner的研究报告3,AI已经消耗了整个国家电力使用量的约2%。因为使AI更加环境友好是一个关键目标,这里我们参考[2],使用“绿色计算”(Green Computing)这个词,它指的是那些试图平衡AI解决方案的性能和计算资源及环境影响成本的研究。 如图4所示,绿色计算的框架包括以下关键组件: (1) 绿色度量(Measures of Greenness):测量一个智能系统所需计算资源的关键因素和方法,或称为计算中的“绿色度”。常见的度量包括直接的指标,如运行时间、功耗(如电力使用量)和模型大小,还包括间接的指标,如碳排放。 (2)** 节能AI(Energy-Efficient AI)**:优化AI模型整个生命周期的节能方法,包括模型设计、训练、推理。它还包括大型语言模型的优化技术,以减少训练和推理的功耗。 (3) 节能计算系统(Energy-Efficient Computing Systems):优化计算系统中资源消耗的技术,包括集群资源调度、分区和数据管理优化。 (4) AI的可持续性(AI for Sustainability):采用AI提高可持续性的用例,包括为环境效益提供的应用程序(环境绿色计算)和提高工程效率(工程绿色计算)。环境绿色计算包括像利用卫星成像计算机视觉来监测空气污染排放和碳封存估计的用例,工程绿色计算包括像优化加密用于数据库安全的用例。
1.3 本综述的概述
在这项综述中,我们根据图4所示的框架对绿色计算进行了系统性的审查。本调查的概述组织如下: • 引言:本章为当前的人工智能研发趋势提供了一个概述,也被称为红色计算。它还讨论了绿色计算的动机、框架以及采用绿色计算技术的机会。 • 绿色计算的度量:我们描述影响计算资源消耗的关键因素,以及常用的测量计算“绿色度”的方法。 • 节能模型设计:在这一章,我们列出了节能模块来设计一个高效的AI模型,我们还描述了策略和NAS(神经结构搜索)方法来继续优化模型。 • 节能训练:本章列出了在模型训练过程中优化计算资源和数据使用的方法,同时保持训练模型的性能。 • 节能推断:这一章描述了优化训练模型的常用技术,包括模型修剪、低秩分解、量化、蒸馏和提前退出策略。 • 绿色计算系统:在这一章,我们描述了用于优化部署环境中的资源消耗的技术,包括云环境中的集群资源调度、服务器资源分区和数据管理。 • 绿色大型语言模型:在大型语言模型(LLM)的时代,对计算资源的需求越来越高。本章列出了优化LLMs的训练和推断的新方法。 • 绿色计算的应用:本章涉及AI的可持续性。在这一章,我们列出了几种采用AI为各个行业的环境和工程效益的用例。
• 结论:本章总结了综述,并讨论了绿色计算的可能未来方向。


