
文 / 陈益强
**摘 要:**本文提出了一种新型的大模型分布式构建框架——模型联邦网络(简称“模联网”),旨在解决行业大模型训练面临的“数据孤岛”“算力孤岛”和“模型孤岛”三大挑战。模联网通过联邦学习、安全共享计算等方式,实现数据加工式共享,降低对集中式大算力的依赖,促进模型融合与协同。详细介绍了模联网在打破数据孤岛、模型孤岛方面的关键技术,展示了其在医疗领域的应用案例,并进一步探讨了模联网突破传统大模型规模效应局限的潜力,提出模联效应概念,通过模型融合与协同实现能力聚合,提升大模型性能。未来,模联网有望成为跨行业的“AI4ALL”基础科创平台,为各行业领域和用户提供低门槛、低成本和高效能的智能模型与服务。
**关键词:**数据孤岛;联邦学习;模联网;AI4ALL 平台
0 引言
预训练大模型正在成为各行业领域重要的“生产力工具”。Google 研发的医学大语言模型Med-PaLM2 首次在美国医疗执照考试中达到了专家水平,具有和临床医生水平相当的医疗问答能力;DeepMind 研发的蛋白质结构预测专用大模型AlphaFold3,不仅预测了几乎涵盖所有已知氨基酸序列的 2 亿多个蛋白质结构,而且在分子水平上实现了蛋白质与其他生物分子相互作用的高精度结构预测,其研究者因此获得了 2024 年诺贝尔化学奖。
Scaling Laws(规模效应)被称为大模型的第一性原理,即增大参数规模、训练样本和训练时间将持续提升模型性能。在此指导下,目前大模型发展主要采用“集中式”炼大模型的方式,在大数据上利用大规模的算力集群训练超大规模的模型参数。然而,在很多行业应用场景下不仅缺乏“集中式”炼大模型所需要的大算力和高质量、多样性的海量大数据,而且大模型训练所消耗的资源也难以负担。尤其在我国数据大但共享难、算力多但分布广和模型多但协作难的现实国情下,采用传统集中式方法训练行业垂类大模型将面临数据孤岛、算力孤岛和模型孤岛的三大挑战:首先,大数据拿不到,行业领域的专用数据具有较强的私有性和敏感性,如医院对医疗数据安全的保护要求很高,难以集中式地获得大数据(“数据孤岛”);第二,大算力买不起,行业应用边缘侧用户通常缺乏大规模计算集群及对应的并行算法框架,难以支撑行业大模型的训练和推理(“算力孤岛”);第三,大模型训不起,大模型训练消耗大量的电力(例如,GPT-3 训练使用了大约 128.7 万度的电,相当于美国约 121 个家庭一整年的用电量),增加模型参数规模的方式难以可持续发展,只能各自训练小规模参数(“模型孤岛”)。行业大模型作为新质生产力,本质上是算力对专业数据进行场景化精加工后的结构性抽象,若将现有针对特定场景和任务构建的专用大模型进行网络化联接和融合协同计算,有望保证“大模型”能力的持续提升。因此,我们提出一种新型的大模型分布式构建框架——模型联邦网络(简称“模联网”),通过联邦学习、安全共享计算等方式将传统数据上传式共享改进为加工式共享,解决数据孤岛问题;通过模型拆分与异步调度将算力需求从传统集中式改进为分布式,解决算力孤岛问题;通过模型融合与协同将传统“炼”大模型改进为“联”大模型方式,解决模型孤岛问题。
模联网示意图如图 1 所示。
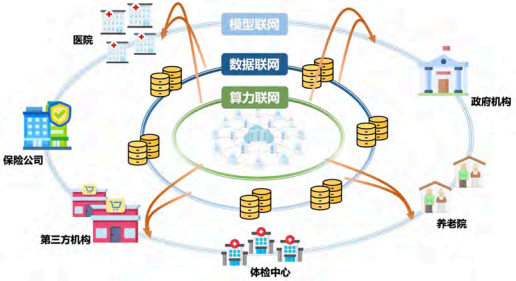
图 1 模联网示意图
1 数算成模:打破数据孤岛
**
**
“数算成模”的过程要求联合数据和算力,现在主要有“数随算动”和“算随数动”两个路径:① 数随算动,将数据提交到各地的算力中心进行模型训练,结束后返回模型参数;但是,这种方式在行业场景中存在数据无法出域和数据安全等问题。② 算随数动,在数据侧直接建设算力中心,通过增加算力节点的数量令算力无处不在;但是,这种方式存在建设成本高且可持续运营难等问题。
如何在数据不动且算力分布下构建行业大模型?联邦学习是近年来提出的一种新型的计算方法,能够打造安全可靠的数据流通环境,在保证原始数据不出域的条件下,通过本地小规模训练和共享模型参数,实现大范围多用户的协同训练,这种计算方法也得到了国家数据局,以及美国和欧盟的关注。然而,在利用联邦学习构建行业大模型时还需解决不可见数据治理与分布式算力不均衡的技术难点。
1.1 数据质控联邦学习技术——FedClean
众所周知,训练数据的质量直接影响模型性能。由于基于联邦学习的数算成模技术需保证原始数据不可见,因此难以直接对数据质量进行评估与治理,只能通过传输的模型参数实现数据质控。对此,我们提出了数据不可见下数据质控联邦学习技术——FedClean,包括以下三种方法:① 联邦机会计算方法 Focus。与传统联邦学习中云端缺乏数据的假设不同,现实中的联邦大多由行业龙头机构牵头,作为发起方的云端通常会有一套金标准数据。Focus 方法提出一种对称性检验损失,对比云端和本地数据分别在本地和全局模型的损失,从而在不接触原始数据的情况下评估本地数据整体的质量,相关工作发表在首部联邦学习的英文专著 Federated Learning:Privacy and Incentive。② 基于联邦共识的标签修正方法 CLC。行业中各机构水平参差不齐,虽然各自采集的数据有效,但标注水平差异导致行业大模型训练受到噪声干扰。对此,CLC 提出了一种联邦共识机制,利用多中心损失分布中蕴含的知识实现样本级的噪声检测和标签修正,从而避免了信息损失,相关工作发表在 JCR Q1 期刊 IEEE TNNLS。③ 混合带噪联邦学习 FedMIN。在原始数据不可见的情况下,难以保证各机构采集数据的有效性,即数据噪声可分为标签噪声和样本噪声两种类型。FedMIN 通过联邦学习过程中的损失分布实现不同噪声类型的有效区分,针对性地采取不同手段进行噪声处理,提高联邦学习的鲁棒性,相关成果发表于 CCF A 类会议 IJCAI。
1.2 分布式模型拆分与异步联邦学习框架 FedBone
目前大模型训练主要采用集中式的算力集群,但现实情况中广域分布的算力是极不均衡的。比如,大型三甲医院能够建设自己的算力中心,但在地区医院或者诊所很难配置足够算力来支撑大模型的训练。充分利用异构的分布式算力来训练行业大模型需要新型的计算框架,对此,我们将联邦学习与拆分学习结合起来,提出一种分布式模型拆分与异步联邦学习框架 FedBone,将大模型中最耗计算资源的、用于提取抽象特征的中间部分拆分并调度至大算力中心,本地小算力则专注于浅层网络及决策层的适配,从而降低本地计算的算力需求。FedBone 将本地浅层处理的中间特征上传至云端,继续进行更深层次的、计算负载高的表征学习,并将计算后的表征嵌入返回本地后,通过个性化适配完成本地任务。在云端的表征学习通过异步联邦学习实现多用户的模型聚合,降低异地分布式计算中对低延迟的需求。在公开数据集和眼底图像检测医学任务数据集上的实验结果表明,FedBone 在多任务上能够取得最佳的平均性能,特别是当模型规模扩展为亿级至十亿级时,FedBone 的本地模型参数能够维持在百万级别,显存占用低于 4 GB,并且保证模型的整体性能,相关工作发表于我国计算机领域唯一 SCI 期刊 JCST。
1.3 应用案例
基于上述方法,我们采用“模型即服务”(model as a service,MAAS) 的方式搭建了一套“联”大模型共性技术平台,实现了数据不动模型动、数据可用不可见的多中心协同建模。目前已支撑爱尔眼科集团、中国帕金森联盟、中国人民解放军总医院、中国联通等机构开展了多中心的联邦协作,在 100+家医院进行了应用示范。
1.3.1 可扩展的数字眼科联邦协同平台 FedEYE®
针对多中心医学影像数据孤岛问题,如眼底图像一般分布在不同医院,但医院之间并不完全互通,我们与爱尔眼科医院集团共同构建了可扩展的数字眼科联邦协同平台 FedEYE® 实现了覆盖北京、上海、南京、成都、武汉、沈阳等 15 个省级与地级市的大规模多眼病细分类眼底影像数据管理,包含 2.2 万张经过多名眼科专家一致标注的高质量眼底图像数据集,在此基础上构建的眼科疾病辅助诊断模型在多个眼科测试任务上精度超过 90%,与单中心模型精度相比提高了 5%~10%,相关成果发表于 Cell 子刊 Patterns。该平台落地建设爱尔眼科“1+8+N”联邦协同架构,覆盖 9 大区域中心、200+ 个县市区域和 1000+ 个眼健康服务站点。
1.3.2 神经退行性疾病预警与辅诊
针对帕金森病临床评价量表 MDS-UPDRS 主观性强和一致性弱的问题,我们研发了神经退行性疾病智能辅诊系统(STAND 系统),集成了包括智能手机、手环和鞋垫等多模态可穿戴设备,基于联邦学习方法构建了多中心的神经退行性疾病智能辅诊模型。其中,基于患者行为客观感知数据实现了运动症状的量化评估,帮助提升帕金森病平均诊断率10%;同时在多中心隐私协作条件下,提出了一种联邦可解释学习方法,能够从客观感知的运动数据中挖掘与疾病症状相关的关键特征,与临床使用的量表评分相比具有更高的敏感性,有望在评分未发生变化时提前预警疾病进展,未来能够为帕金森病数字化标志物的发现提供支持。该系统获得首都医科大学宣武医院国家老年疾病临床医学研究中心的应用证明支撑,并在 400 多家医院的中国帕金森联盟进行应用。
2 模联生智:打破模型孤岛
**
**
联邦学习一定程度上可解决单联邦内的“数据孤岛”问题,构建联邦内可共享的模型,但模型在联邦间难以直接共享,形成了“模型孤岛”。因此,如何打通多联邦间的协同建模成为了新的挑战。
2.1 基于循环蒸馏的“联邦之联邦”协作方法MetaFed
打破模型孤岛目前主要有两种技术路线,一种是在多个联邦之上再增加一个全局可信的协调节点,但由于现实中难以找到具有广泛信任基础的第三方,这种方法在大多数行业中难以实施;第二种是采用去中心化的点对点联邦架构,例如 Nature 发表的封面文章 Swarm Learning,然而在去中心化的联邦学习中,模型参数需要在所有权利均等的成员之间进行广播,消耗大量的带宽资源。对此,我们提出了一种基于循环蒸馏的“联邦之联邦”协作方法 MetaFed,包括共性知识积累和个性化适配两个阶段,以环形或图的拓扑结构构建知识传递的路径,通过路径优化和多轮循环实现知识的叠加,并通过知识交换过程中的权重保证本地知识的自适应,实现模型的个性化适配。该方法有效实现了不同联邦之间的协同学习和知识传递,在传统联邦学习基础上进一步提升了模型性能,荣获了 FL-IJCAI 2022的创新奖。2024 年,Nature Biotechnology 发表的 It takes two to think 从生命科学的角度验证了 MetaFed 所提出的“两人交换知识或是最佳”策略。
2.2 联邦迁移学习框架 FedHealth
在行业场景下,如医疗健康,联邦学习的各参与方通常具有个性化的任务需求,参与方协同共建的统一共享的大模型一定程度上丢失了个性化信息。对此,我们提出一种面向医疗健康应用的联邦迁移学习框架 FedHealth,由云端下发统一的联邦模型及共享数据,利用本地数据与云端数据进行联邦模型的个性化迁移,从而实现联邦模型的自适应适配。我们在医疗健康场景中验证了 FedHealth 的有效性,其精度较非联邦模型和非迁移模型分别最大提升了 21.6% 和 14%,相关工作在 2019 年获得首届 FL-IJCAI 研讨会的最佳应用论文奖,并于 2020 年发表于 IEEE Intelligent Systems(截止目前,Google 学术引用率超过 950 次)。
2.3 应用案例:跨物种生命基础大模型GeneCompass
基于上述框架,我们与中国科学院动物研究所等多家科研机构合作,共同研发了国际首个跨物种基因基础大模型,覆盖了 1.2 亿多单细胞数据和 3 万多基因数量,实现人与小鼠的跨物种融合,以及人类先验知识的嵌入,针对基因扰动预测、药物敏感性预测等典型生命科学下游任务,通过大模型的迁移适配形成的专用模型,其性能取得了国际领先水平。同时,基于 GeneCompass 的迁移适配探索了“干 + 湿”融合的实验新范式,针对诱导胚胎干细胞发育的靶基因筛选,发现了 5 个候选基因,与传统靶基因发现依赖经验和知识的方法相比,极大缩小了湿实验对象的搜索空间,显著提升了相关生命科学研究的效率。相关成果作为封面文章刊登于 2024 年 10 月 Nature 的子刊 Cell Research 上,自正式发表以来浏览次数已超过 1.3 万次。
3 智演未来:突破规模效应
**
**
大模型在预训练阶段的 Scaling Laws 已产生了边际效应递减现象,在不断扩大数据规模、参数规模和训练时间上可能已遇到发展的天花板。OpenAI o1 的横空出世开启了大模型演化的新范式——后训练, 也 被 称 为 Inference Scaling Laws。OpenAI o1 结合 COT 技术将推理阶段的时间增加,把更多的算力放到了推理阶段,从而在数学代码等复杂推理能力上取得的巨大进步,直逼人类博士水平。可以看出,大模型的发展不再是单纯地追求“越大越好”,而是结合实际需求明确 Scaling 的对象。因此,我们基于联邦学习机制提出了一种面向模型的 Scaling Law——模联效应,建立以“联”为核心的超大规模模型群,通过模型融合与协同实现能力聚合,以模型网络节点规模的扩张提升大模型性能。我们初步探索了模联效应的实现,重点研究了模联网构建中安全流转、公平融合以及智能测调等关键技术。
首先,模联网的节点之间进行模型的共享与流程需要一个可信的流转模型载体,避免模型的敏感信息和训练样本通过模型参数泄露。对此,我们提出了一种面向模型流转的安全模型封装方法 PrivFusion。PrivFusion 采用混合式的差分隐私技术将预训练的神经网络模型封装成图结构流转载体,通过多尺度的图节点与边扰动,保障模型信息安全;通过去中心化的联邦图匹配方法,保证模型融合效果,实现不同模型的跨域协同。此过程不需要训练数据,通过细粒度的隐私预算控制,融合后的模型在可用性与安全性之间的平衡达到最优,在保证模型性能的同时在所有测试基准上比其他方法的安全性更好,相关成果发表于 CCF A 类期刊 IEEE TKDE。
其次,模联网的节点之间进行模型融合需要考虑隐私性和公平性,一方面模型参数中蕴含训练样本的知识,模型参数的明文融合易产生隐私泄漏风险;另一方面,模型的训练样本具有非独立同分布的天然属性,尤其是跨地域、跨人群的模型之间会存在性别、年龄、种族等因素影响,群体模型的融合进化需要考虑公平性,避免产生有偏好的模型输出。对此,我们提出了一种面向模型公平融合的群体模型进化方法 FairFusion,采用基于最优传输理论的模型内部表征对齐和基于本地化差分隐私的模型参数保护,实现跨节点的模型安全融合,通过调整隐私预算、融合比例等敏感性参数,构建候选模型池,利用多目标量化约束与群体进化寻优,进而寻求融合模型的帕累托最优解和帕累托前沿,实现融合模型在可用性、安全性和公平性之间的平衡最优,相关成果发表于 CCF A 类会议 IEEE ICDE。
最后,传统多模型协同通常依赖固定规则或预设流程,难以适应复杂动态的任务需求。针对这一问题,我们提出了一种面向模联网服务的模型智能测调方法 FusionHive(如图 2 所示),以模型能力、增强策略和服务场景为核心进行模型管理和动态测调。通过多方向的优化策略(如微调、放缩、裁剪等)对公开模型和私有模型进行能力扩展,构建动态模型知识图谱,将公共和私有模型有机连接,形成模型间的关联与归档体系。同时,通过自监督学习和多模型对齐技术,优化模型增强效果,提升模型的泛化能力与场景适配性。在智能测调方面,FusionHive 基于用户需求和优化目标,构建模联网协同测调框架,利用强化学习和图神经网络形成最优候选模型集,并设计模型路由机制以实现“下一个模型预测(next model prediction)”的动态调度与高效匹配。在模型服务方面,FusionHive 强调模型输出、新数据和人类反馈的协同作用,将前一个模型的输出结合少量新场景数据和反馈决策干预作为下一个模型的输入,构建在复杂场景下的动态模型服务链 CoM。
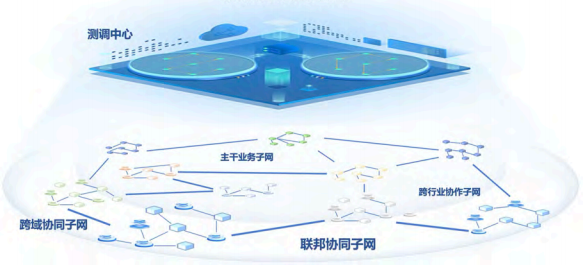
图 2 模联网双层架构
4 未来展望
模联网探索了一条以“系统化”思维实现广域分布式模型训练与服务的技术路线,区别目前大模型以“算”为核心、以参数规模扩张提升性能的路线,突破以“联”为核心的模型网络构建技术,以网络节点规模的扩张提升性能,量变实现质变。作为一种新型的大模型分布式构建框架,模联网具备广域共享、智能测调、自主增强和持续优化的核心能力,能有力支撑可信数据空间的数据、算力和模型协同,为各行业领域和用户提供低门槛、低成本和高效能的智能模型与服务。
未来,我们致力于将模联网打造为“两低一高”跨行业的“AI4ALL”基础科创平台。其中,高效能交叉:强有力的数据治理与模型工具超市,支持 AI 与行业的高效能交叉创新;低门槛参与:自适应的人机交互界面,降低行业领域人员使用 AI 工具的障碍,无论其学科背景、组织关系及地点;低成本互惠:开放共享的 AI 资源(数据、模型、实训等),促进行业领域人员 AI 技能和知识能力的提升,确保越来越多行业用户能够使用最先进的 AI 技术。
(参考文献略)

陈益强
中国科学院计算技术研究所副所长,研究员,智能研究部主任,移动计算与新型终端北京市重点实验室主任,国家级领军人才,CCF Fellow,CAAI 智慧医疗专委会常务委员。主要从事人工智能、普适计算及智慧医学方向研究。
**
**

