

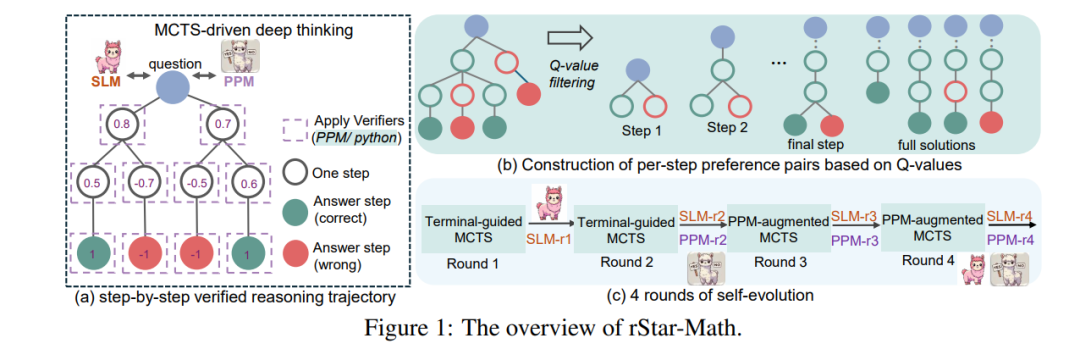
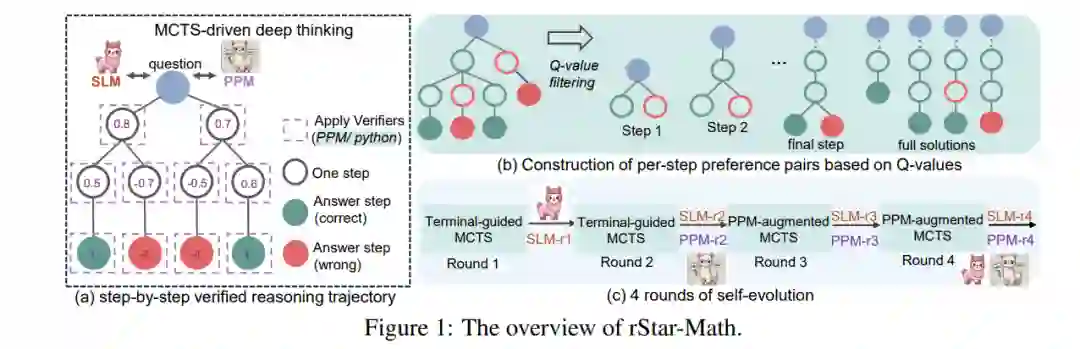
我们介绍了rStar-Math,旨在展示小型语言模型(SLMs)能够与OpenAI的o1模型竞争,甚至超越其数学推理能力,且无需通过优越模型进行蒸馏。rStar-Math通过运用“深度思维”结合蒙特卡罗树搜索(MCTS)实现这一目标,其中数学策略SLM在测试时通过基于SLM的过程奖励模型进行搜索指导。rStar-Math提出了三项创新,以解决训练这两个SLM面临的挑战: 1. 一种新颖的代码增强链式思维(CoT)数据合成方法,该方法通过广泛的MCTS展开生成逐步验证的推理轨迹,用于训练策略SLM; 1. 一种新型的过程奖励模型训练方法,避免了简单的逐步评分注释,从而生成更有效的过程偏好模型(PPM); 1. 一种自我进化的策略,其中策略SLM和PPM从零开始构建,并通过迭代演化来提升推理能力。
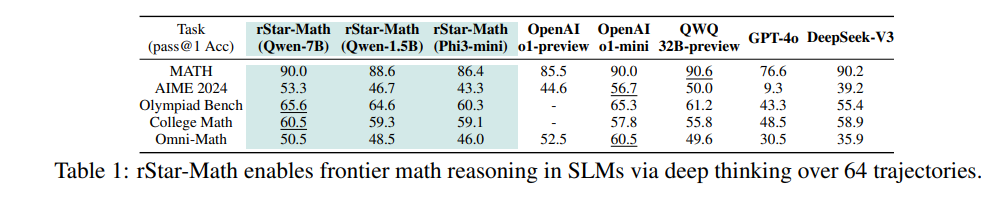
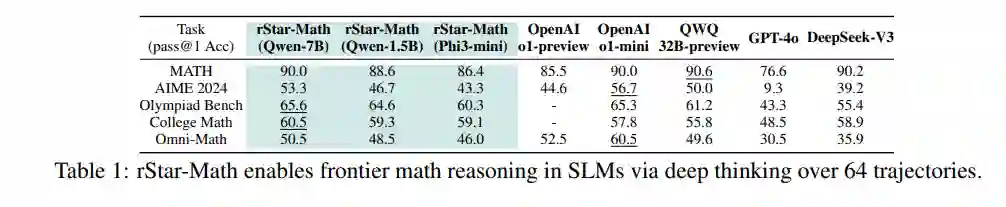
通过4轮自我进化,结合数百万个合成解决方案解决747k个数学问题,rStar-Math将SLM的数学推理能力提升至最先进的水平。在MATH基准测试中,rStar-Math将Qwen2.5-Math-7B的得分从58.8%提高至90.0%,将Phi3-mini-3.8B的得分从41.4%提高至86.4%,分别超越o1-preview +4.5%和+0.9%。在美国数学奥林匹克(AIME)中,rStar-Math平均解决了53.3%(8/15)的问题,排名位于最优秀的20%高中数学学生之中。 代码和数据将在https://github.com/microsoft/rStar提供。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日