【ICLR2022顶会论文分享】PPO算法的37个Implementation细节

来源:ICLR blog

Jon 是一名对强化学习 (RL) 感兴趣的一年级硕士生。在他看来,RL 似乎很迷人,因为他可以使用 Stable-Baselines3 (SB3) 等 RL 库来训练智能体玩各种游戏。他很快认识到近端策略优化 (PPO) 是一种快速且通用的算法,并希望自己将 PPO 实现为一种学习体验。读完论文,Jon心里想,“嗯,这很简单。” 然后他打开了一个代码编辑器并开始编写 PPO。来自 Gym 的 CartPole-v1 是他选择的模拟环境,不久之后,Jon 让 PPO 与 CartPole-v1 一起工作。他度过了一段美好的时光,并有动力让他的 PPO 在更有趣的环境中工作,例如 Atari 游戏和 MuJoCo 机器人任务。“那该有多酷?” 他以为。
然而,他很快就挣扎了。让 PPO 与 Atari 和 MuJoCo 合作似乎比预期更具挑战性。Jon 然后在网上寻找参考实现,但很快就不知所措:非官方存储库似乎都做不同的事情,而他只是无法阅读官方 repo 中的 Tensorflow 1.x 代码。幸运的是,Jon 偶然发现了最近两篇解释 PPO 实现的论文。“就是这个!” 他咧嘴一笑。无法控制自己的兴奋, Jon开始在办公室里跑来跑去,不小心撞到Sam,Jon知道他正在研究 RL。然后他们进行了以下对话:


博客文章就在这里!这篇博文没有进行消融研究并就哪些细节很重要提出建议,而是退后一步,重点关注复现 PPO 的结果。具体来说,这篇博文通过以下方式补充了之前的工作:
Genealogy Analysis:我们通过检查 openai/baselines GitHub 存储库(PPO 的官方存储库)中的历史修订来确定重现官方 PPO 实现的意义。正如我们将展示的,openai/baselines 存储库中的代码经历了几次重构,这些重构可能会产生与原始论文不同的结果。所以认清哪个版本的官方实现值得研究是很重要的。
Video Tutorials and Single-file Implementations:我们制作了有关在 PyTorch 中从头开始重新实现 PPO 的视频教程,匹配官方 PPO 实现中的细节以处理经典控制任务、Atari 游戏和 MuJoCo 任务。值得注意的是,我们在代码库中采用单文件实现,使代码更快、更易于阅读。视频如下所示:
https://www.youtube.com/watch?v=MEt6rrxH8W4
https://www.youtube.com/watch?v=05RMTj-2K_Y
https://www.youtube.com/watch?v=BvZvx7ENZBw
Implementation Checklist with References: ,在重新实施期间,我们编制了一份实施清单,其中包含以下 37 个细节。对于每个实现细节,我们显示其代码的永久链接(学术论文中没有这样做)并指出其文献联系。
13 core implementation details
9 Atari specific implementation details
9 implementation details for robotics tasks (with continuous action spaces)
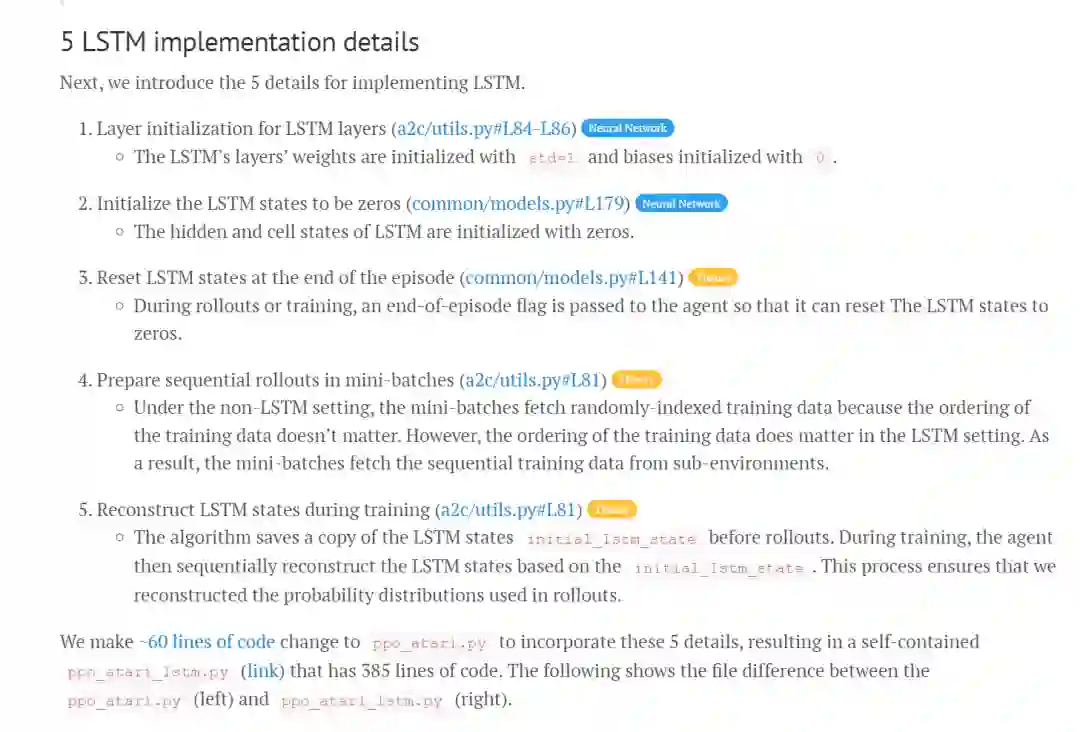
5 LSTM implementation details
1 MultiDiscrete action spaces implementation detail
High-fidelity Reproduction:为了验证我们的重新实现,我们展示了我们实现的经验结果与原始的那些在经典控制任务、Atari 游戏、MuJoCo 任务、LSTM 和实时策略 (RTS) 游戏任务中的结果非常匹配。
Situational Implementation Details::我们还介绍了 4 个未在官方实现中使用但在特殊情况下可能有用的实现细节。
我们的最终目的是帮助人们彻底了解 PPO 的实施,以高保真度重现过去的结果,并促进新研究的定制。为了使研究具有可重复性,我们在 https://github.com/vwxyzjn/ppo-implementation-details 上提供了源代码,在 https://wandb.ai/vwxyzjn/ppo-details 上提供了跟踪实验
Background
PPO 是 Schulman 等人 (2017) 提出的一种策略梯度算法。作为对信任区域策略优化 (TRPO) (Schulman et al., 2015) 的改进,PPO 使用更简单的裁剪智能体目标,省略了 TRPO 中昂贵的二阶优化。尽管目标更简单,但 Schulman 等人 (2017) 表明 PPO 在许多控制任务中比 TRPO 具有更高的采样效率。PPO 在包含 Atari 游戏的街机学习环境 (ALE) 中也具有良好的经验表现。
(-): No publicly reported metrics available
($): The experiments uses the v1 MuJoCo environments
(*): The experiments uses the v2 MuJoCo environments
(^): The experiments uses the v3 MuJoCo environments
(0): 1M steps for MuJoCo experiments, 10M steps for Atari games, 1 random seed
(1): 2M steps for MuJoCo experiments, 10M steps for Atari games, 2 random seeds
(2): 25M steps and 10 workers (5 envs per worker) for Atari experiments; 44M steps and 16 workers for MuJoCo experiments; 1 random seed
(3): 3M steps, PyTorch version, 10 random seeds
(4): 2M steps, 10 random seeds
(5): 3M steps, 10 random seeds for MuJoCo experiments; 10M steps, 1 random seed for Atari experiment
(6): 5M steps, 10 random seeds

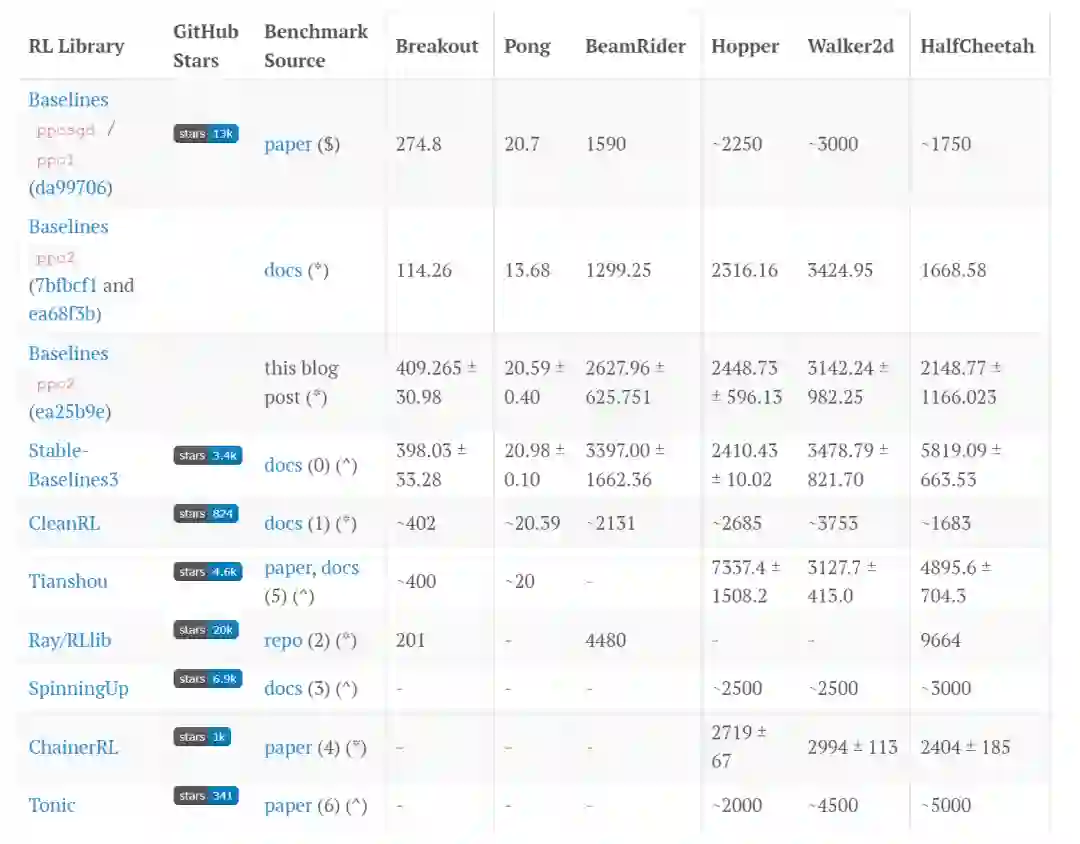
我们提供了几个观察结果。

尽管情况复杂,但我们发现 ppo2 (ea25b9e) 是一个值得研究的实现。它在 Atari 和 MuJoCo 任务中都获得了良好的性能。更重要的是,它还融合了 LSTM 和 MultiDiscrete 动作空间处理等高级功能,解锁了对实时策略游戏等更复杂游戏的应用。因此,我们将 ppo2 (ea25b9e) 定义为官方 PPO 实现,并将本博文的其余部分基于此实现。
Reproducing the official PPO implementation
在本节中,我们将介绍五类实现细节,并从头开始在 PyTorch 中实现它们。
13 core implementation details
9 Atari specific implementation details
9 implementation details for robotics tasks (with continuous action spaces)
5 LSTM implementation details
1 MultiDiscrete implementation detail
对于每个类别(第一个类别除外),我们将我们的实现与三个环境中的原始实现进行基准测试,每个环境都有三个随机种子。
13 core implementation details
我们首先介绍无论任务如何都常用的 13 个核心实现细节。为了帮助理解如何在 PyTorch 中编写这些细节,我们准备了如下的逐行视频教程。请注意,视频教程在制作过程中跳过了第 12 和第 13 的实现细节,因此视频的标题是“11 核心实现细节”
1. Vectorized architecture (common/cmd_util.py#L22)
PPO 利用一种称为矢量化架构的高效范式,该架构具有一个单一的学习器,可以收集样本并从多个环境中学习。下面是一个伪代码:
envs = VecEnv(num_envs=N)
agent = Agent()
next_obs = envs.reset()
next_done = [0, 0, ..., 0] # of length N
for update in range(1, total_timesteps // (N*M)):
data = []
# ROLLOUT PHASE
for step in range(0, M):
obs = next_obs
done = next_done
action, other_stuff = agent.get_action(obs)
next_obs, reward, next_done, info = envs.step(
action
) # step in N environments
data.append([obs, action, reward, done, other_stuff]) # store data
# LEARNING PHASE
agent.learn(data, next_obs, next_done) # `len(data) = N*M`在这个架构中,PPO 首先初始化一个向量化的环境 envs,它通过利用多进程顺序或并行运行 N 个(通常是独立的)环境。envs 提供了一个同步接口,它总是从 N 个环境中输出一批 N 个观察结果,并且它需要一批 N 个动作来步进 N 个环境。当调用 next_obs = envs.reset() 时,next_obs 会得到一批 N 个初始观察值(读作“下一个观察值”)。PPO 还将环境完成标志变量 next_done(发音为“next done”)初始化为一个长度为 N 的零数组,其中它的第 i 个元素 next_done 的值为 0 或 1,对应于第 i 个子 环境分别未完成和完成。
一个常见的错误实现是基于情节训练 PPO 并设置最大情节范围。下面是一个伪代码。

env = Env()
agent = Agent()
for episode in range(1, num_episodes):
next_obs = env.reset()
data = []
for step in range(1, max_episode_horizon):
obs = next_obs
action, other_stuff = agent.get_action(obs)
next_obs, reward, done, info = env.step(action)
data.append([obs, action, reward, done, other_stuff]) # store data
if done:
break
agent.learn(data)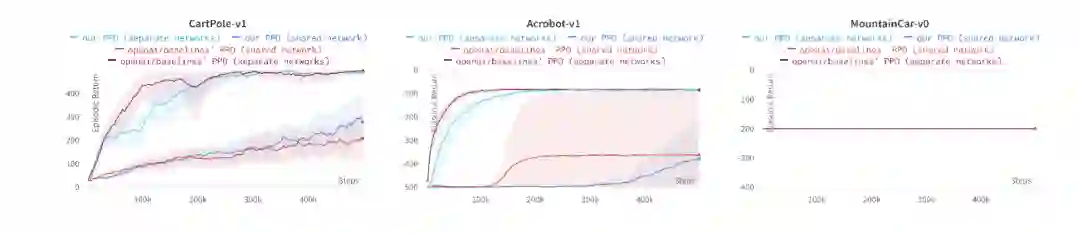
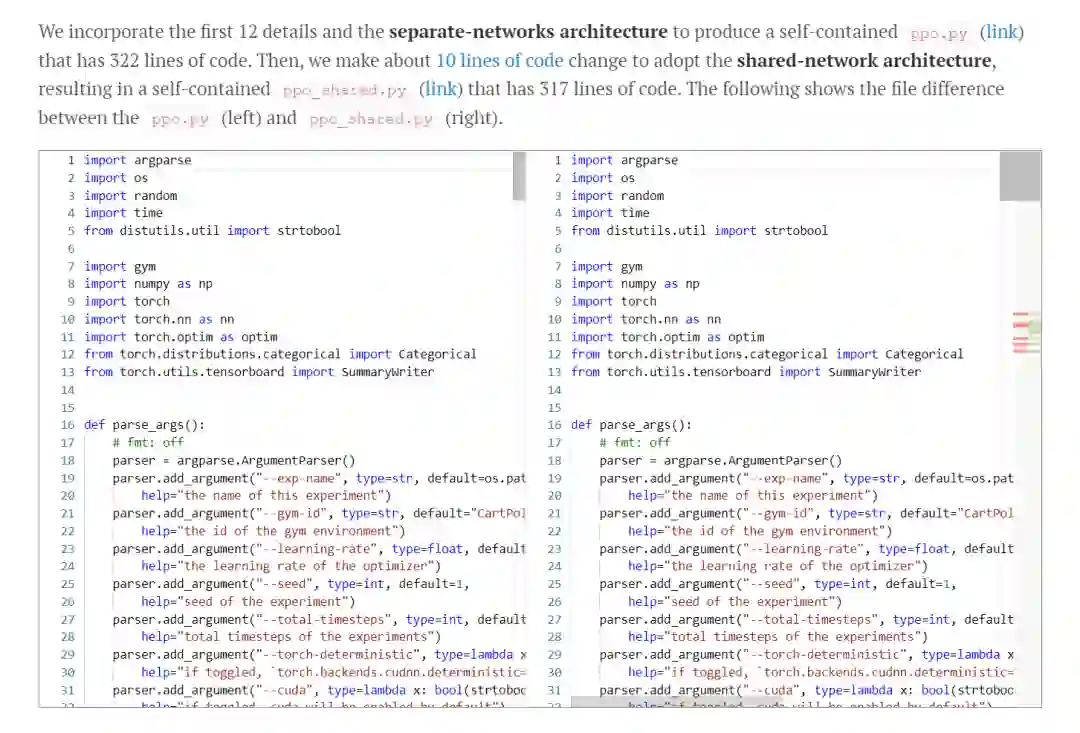
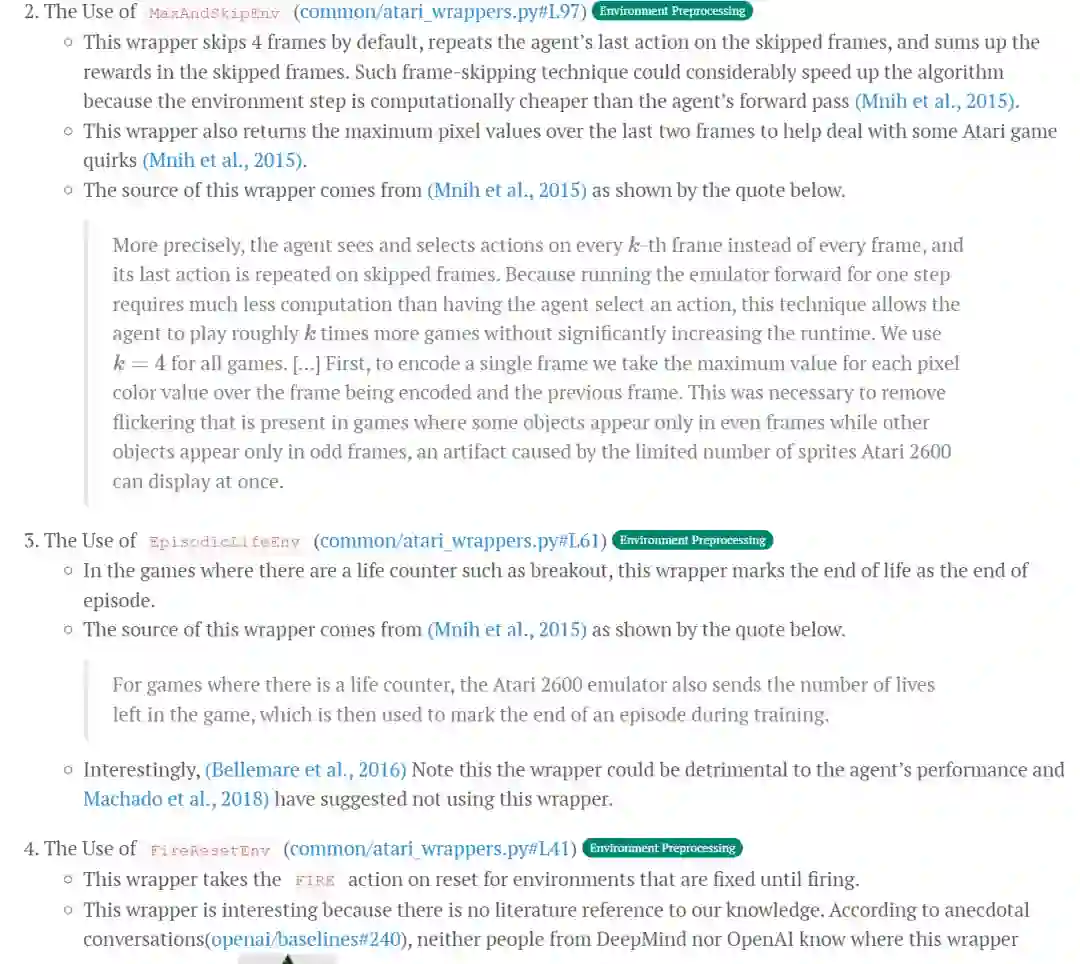
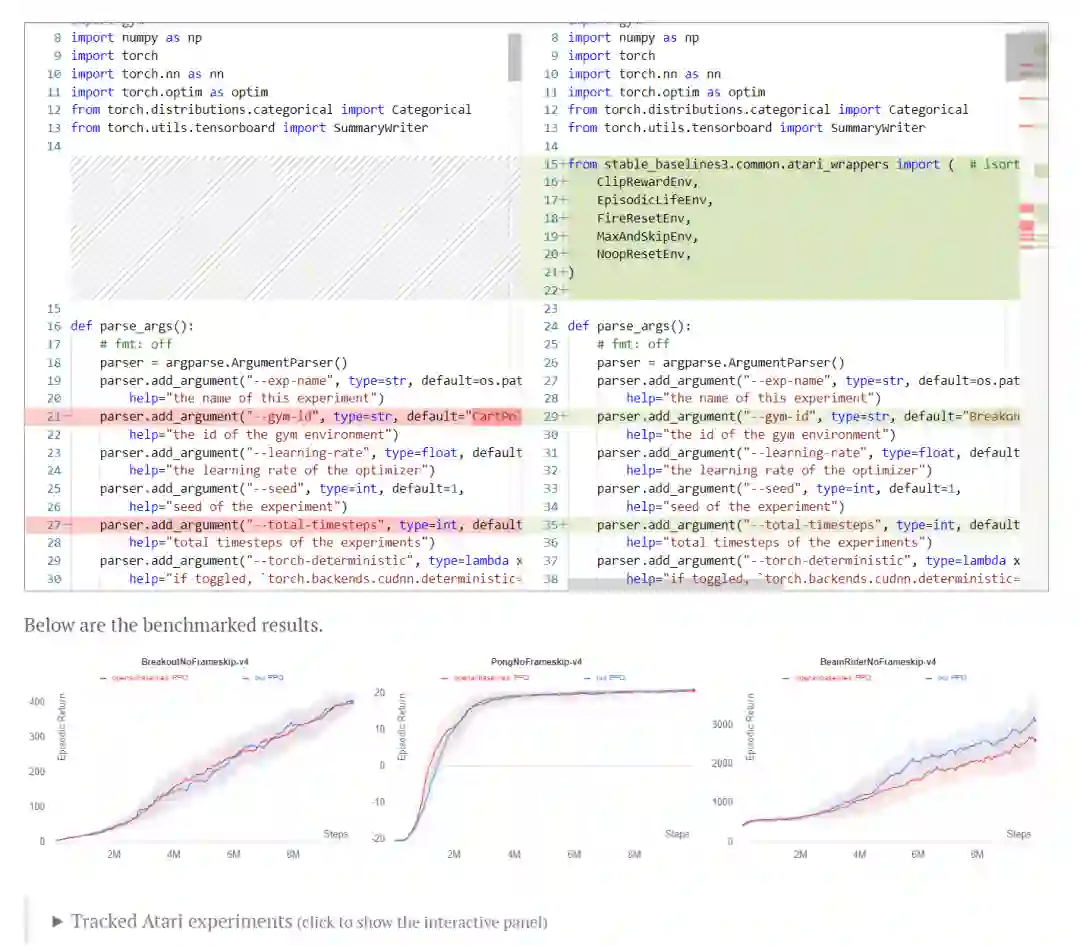
部分翻译(点击 阅读原文)
http://deeprlhub.com/d/745-ppo37implementation
参考原文:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
@inproceedings{
anonymous2022the,
title={The 37 Implementation Details of Proximal Policy Optimization},
author={Anonymous},
booktitle={Submitted to Blog Track at ICLR 2022 },
year={2022},
url={https://openreview.net/forum?id=Hl6jCqIp2j},
note={under review}
}




