

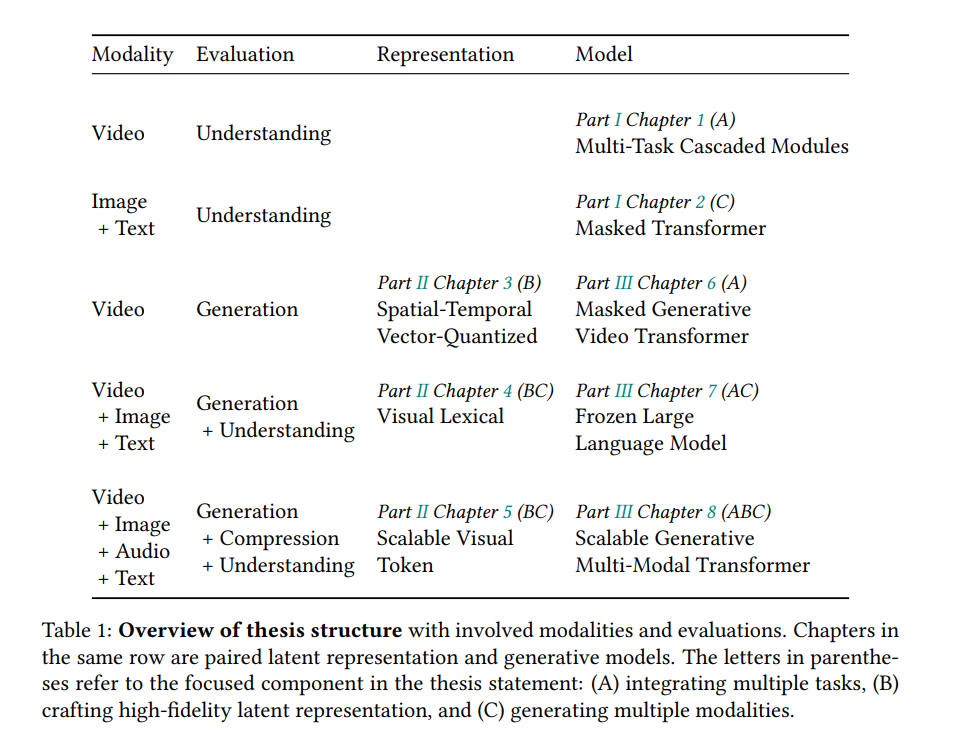
语言基础模型的进步主要推动了最近人工智能的迅猛发展。相比之下,非文本模态的生成学习,特别是视频,显著落后于语言建模。本论文记录了我们在多任务模型构建方面的努力,旨在在多种条件下生成视频和其他模态,以及在理解和压缩应用中的探索。
我们首先介绍了用于独立多任务和多模态设置的两个像素空间原型。尽管这些模型有效,但它们受到特定任务模块和预定义标签空间的限制,这凸显了需要更具普遍适用性的设计。
鉴于视觉数据的高维度性,我们追求简洁且准确的潜在表示。我们的视频原生时空标记器保留了高保真度。我们揭示了一种在视觉观察和可解释词汇术语之间双向映射的新方法。此外,我们可扩展的视觉标记表示在生成、压缩和理解任务中都证明了其优势。这一成就标志着语言模型首次在视觉合成方面超越了扩散模型,而视频标记器也超过了行业标准的编解码器。
在这些多模态潜在空间内,我们研究了多任务生成模型的设计。我们的掩码多任务Transformer在视频生成的质量、效率和灵活性方面表现出色。我们使一个仅在文本上训练的冻结语言模型能够生成视觉内容。最后,我们从零开始构建了一个可扩展的生成多模态Transformer,使其能够在多种条件下生成包含高保真运动及相应音频的视频。
在整个过程中,我们展示了整合多任务、构建高保真潜在表示以及生成多模态内容的有效性。这项工作为未来在生成非文本数据和实现各种媒体形式的实时互动体验方面的探索提出了令人兴奋的可能性。
自近七十年前诞生以来,人工智能(AI)[139]领域经历了显著的演进发展,标志着一系列关键里程碑的出现。这段历程见证了从基于规则的专家系统[28]到由机器学习[173]引领的数据驱动范式的转变,随后超越到深度学习的领域,重点从特征工程[135]转向直接从原始数据中获取表示[117]。基础模型[17]的出现进一步体现了这一进化轨迹,促进了跨任务知识的共享,从而不再需要特定任务的模型。在这一连续体中,BERT[49]作为基础模型的典范,通过自监督训练大量数据,并在众多下游任务中展现出色的适应能力。这篇论文深入探讨了方法创新核心的多任务通用性,追踪了从层次结构化的监督模块到一致的、普遍适用的自监督框架的演变过程。
大型语言模型(LLMs)[7, 25, 191]作为基础模型的代表,具有生成目标,从各种输入中生成文本输出。值得注意的是,某些LLMs的改编版本[133, 145]扩展了其输入能力,涵盖了图像,尽管其输出仅限于文本。这种以文本为中心的输出体现了人类构想的低带宽抽象,导致对高质量文本数据即将短缺的预测[202]。相比之下,存在大量的原始信号数据生成,尤其是视频,其数量往往超过了可用于其有效利用的计算资源。此外,这些非文本数据类型的自监督生成学习的进展显著落后于语言模型,从而限制了相关任务的潜力。本论文的核心在于探索旨在生成超越文本输出的生成学习,包括视频、图像和音频,从而采用更全面的多模态方法。 最初为解释文本标记而设计的Transformer架构[201],是各个领域可扩展模型的基石。然而,当处理视频等原始信号时,由于其本质上具有更高的维度特性,包含高时空分辨率和多个通道,我们面临一个更为复杂的范式。虽然对于预测标签的判别模型来说,简单的降尺度技术[52]可能已经足够,但对于在这些高维空间中生成内容的生成模型来说,特别是在高分辨率图像或长时间视频生成的情况下,这些技术却提出了巨大的挑战。为了解决这个问题,我们开始在高度压缩的空间中构建学习的潜在表示,并随后制定生成模型,旨在这些受限维度内运行。


