

本博士论文研究对抗性攻击下多智能体强化学习(MARL)和多智能体深度强化学习(MADRL)系统的控制问题。论文对各种攻击进行了研究,并提出了几种防御算法(缓解方法),以帮助实现共识控制和适当的数据传输。
研究了无领导者、同质 MARL 系统的共识问题,使用了有恶意智能体和无恶意智能体的行为批判算法。考虑了各种基于距离的即时奖励函数,以提高系统的性能。除了提出基于欧几里得距离、n-norm 距离和切比雪夫距离的四种不同即时奖励函数外,还根据每个智能体和整个智能体团队的累积奖励,严格论证了哪种奖励函数性能更好。理论证明了这些说法,而模拟则证实了理论结论。
研究了修改恶意智能体的神经网络(NN)结构,以及提供均方误差(MSE)损失函数和 sigmoid 激活函数的兼容组合能否减轻恶意智能体对无领导、同质、MARL 系统性能的破坏性影响。除了理论支持,仿真也证实了理论结论。
利用深度 Q 网络(DQN)算法研究了基于梯度的对抗攻击,这些攻击针对的是基于集群、具有延迟数据传输的异构 MADRL 系统。我们引入了两种新的观测方法,分别称为 "准时观测 "和 "延时观测"。通过考虑相邻智能体之间的距离,我们提出了一种新颖的即时奖励函数,将基于距离的奖励附加到之前利用的奖励上,以提高 MADRL 系统的性能。我们考虑了三种基于梯度的攻击,以研究拟议系统数据传输的鲁棒性。我们还提出了两种防御方法,以减少所讨论的恶意攻击的影响。我们用仿真实例对理论结果进行了说明和验证。
还研究了基于集群的异构 MADRL 系统的智能体之间在基于梯度的恶意攻击下的数据传输鲁棒性。我们提出了一种使用 DQN 方法和比例反馈控制器来防御快速梯度符号法(FGSM)攻击并提高 DQN 智能体性能的算法。仿真结果用于验证所提出的结果。
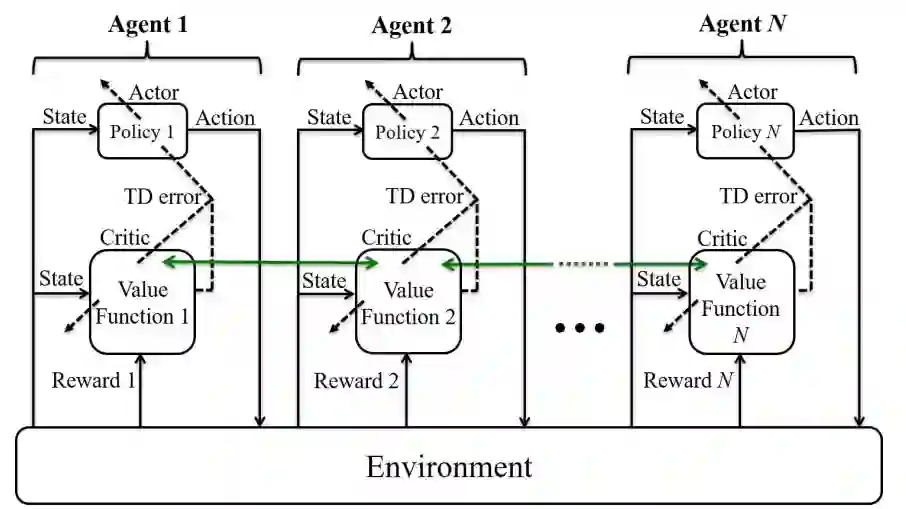
图 4.1: 有 N 个智能体的多智能体评价器架构。绿色箭头表示在相邻智能体之间传输正确数据。
贡献点
本论文的贡献可归纳为以下几个方面:
-
引入了一种基于集群的 MAS 结构,包括 N 个智能体和 P 个集群。我们提出了基于集群的 MAS 的平均位置共识,其中包括具有独特目的的集群,即所有群组的所有智能体的目标都是就相同的位置状态达成全局一致。随后,我们提供了基于集群的 MAS 的平均位置共识,其中包括具有不同目标的集群。在这方面,每个群组的智能体的目标都是就某个位置状态达成局部协议;但是,所讨论的协议与其他群组的解决方法不同。我们将所有计算和模拟实例从二维空间扩展到三维空间。
-
研究了一个无领导、同质 MARL 系统在使用分散式智能体批判法达成共识时的行为,包括有恶意智能体和无恶意智能体。我们根据不同的距离度量定义并提出了各种即时奖励函数。这些即时奖励函数可用于计算每个智能体和 MARL 系统的累积奖励。这项工作研究的是,即使有恶意智能体的破坏作用,改变即时奖励是否也能提高系统的整体性能。假设与现有的距离指标相比,其中一个距离指标(如曼哈顿、欧几里得、n-norm 或切比雪夫距离)在当前位置和期望位置之间提供了一个较小的值。因此,从所讨论的距离度量中提取的即时奖励会为每个智能体和整个 MARL 系统产生更高的回报累积奖励。因此,衡量 MARL 系统行为的标准是基于各种即时奖励函数。
首先,我们研究了 [132] 提出的基于曼哈顿距离的即时奖励函数。因此,我们提出了基于欧氏距离、n-norm 距离和切比雪夫距离的即时奖励函数。此外,我们还提供了一种算法来组合各种即时奖励函数,并根据每一集的最大返回值来使用它们,以提高 MARL 系统内有恶意智能体和无恶意智能体时的智能体累积奖励。然后,我们证明了欧氏即时奖励函数优于曼哈顿即时奖励函数。我们证明了切比雪夫即时奖励函数优于欧氏即时奖励函数。此外,我们还证明了组合即时奖励函数优于其他即时奖励函数。
-
在恶意智能体的 NN 结构中提供了均方误差(MSE)损失函数和 sigmoid 激活函数的兼容组合,以降低 MARL 系统中被讨论的敌对智能体的累积奖励并增加累积损失。在这种情况下,恶意智能体对 MARL 系统性能的有害影响得到了缓解,MARL 系统达成位置共识的效率得到了提高。我们证明了 MSE 损失函数与线性激活函数的结合比 MSE 损失函数与 sigmoid 激活函数的结合更优越,能获得更高的累积奖励和更低的累积损失。
-
研究了基于集群的异构 MADRL 系统中智能体之间在对抗性攻击下的延时数据传输问题。除了无领导者 MAS 外,我们还提出了领导者-追随者 MAS,即每个集群中预先指定的领导者与其他集群的领导者以及本集群的智能体进行通信。我们考虑了数据传输中的两种新型观测,即准时观测和延时观测,并研究了它们对 DQN 损失和团队奖励的影响。我们提出了一种新颖的即时奖励函数,该函数考虑了包长度、包头大小和相邻智能体之间的距离,从而在延时数据传输期间的近似累计团队折扣奖励方面改善了 MAS 性能。我们考虑了 FGSM、FGM 和 BIM 对手(基于梯度的攻击)来攻击 DQN 算法。然后,我们研究了这些攻击对 MAS 性能和延时数据传输的影响。我们引入了两种防御算法来抵御所实施的对抗性攻击。在所提出的防御方法中,DQN 智能体的 DNN 会从产生最大扰动值的状态中学习,并利用其负反馈在对抗性攻击中提高系统性能。
-
为 DQN 算法设计了一个比例控制器,以抵御 FGSM 对抗性攻击的破坏性影响。我们考虑了准时和延时数据传输,研究了一种防御算法,包括 DQN 方法和反馈控制系统。因此,我们提出了一种以 DQN 算法作为反馈控制系统过程的算法,以抵御 FGSM 网络攻击。我们证明了在 DQN 学习过程中使用比例控制器在实现 MADRL 系统更高的平均近似累积团队折扣奖励方面的优越性。


