阿尔伯塔大学博士毕业论文:基于图结构的自然语言处理
机器之心编辑部
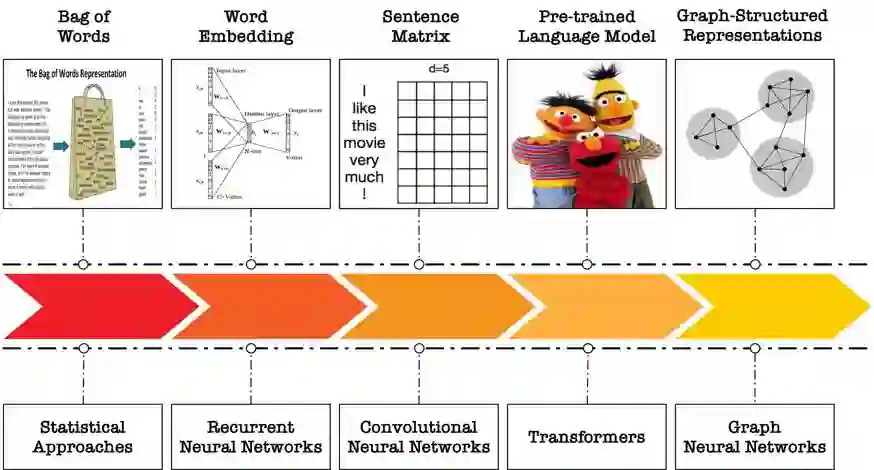
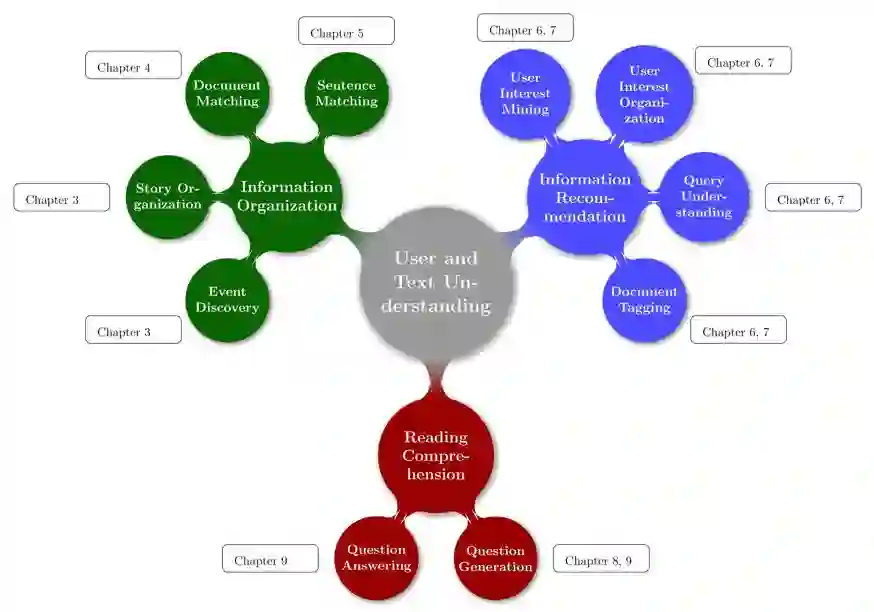
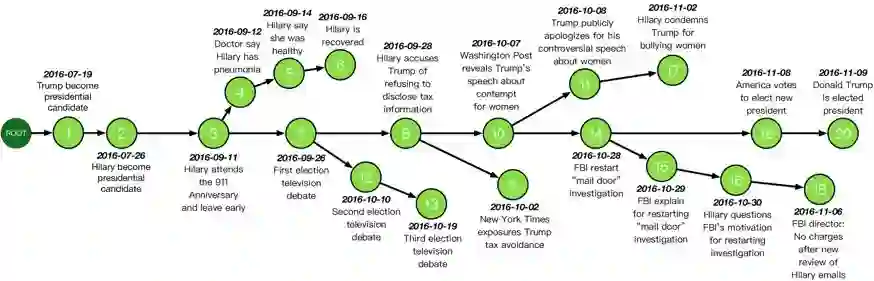
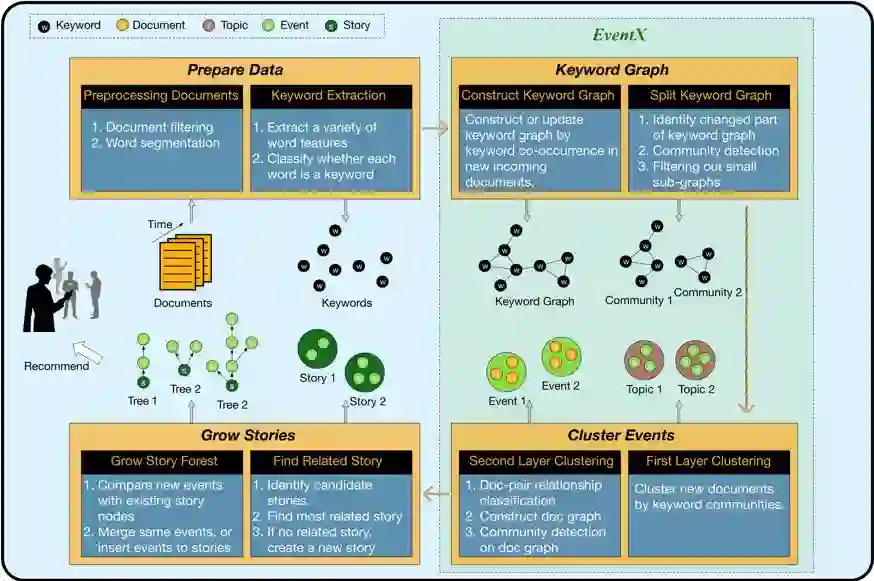
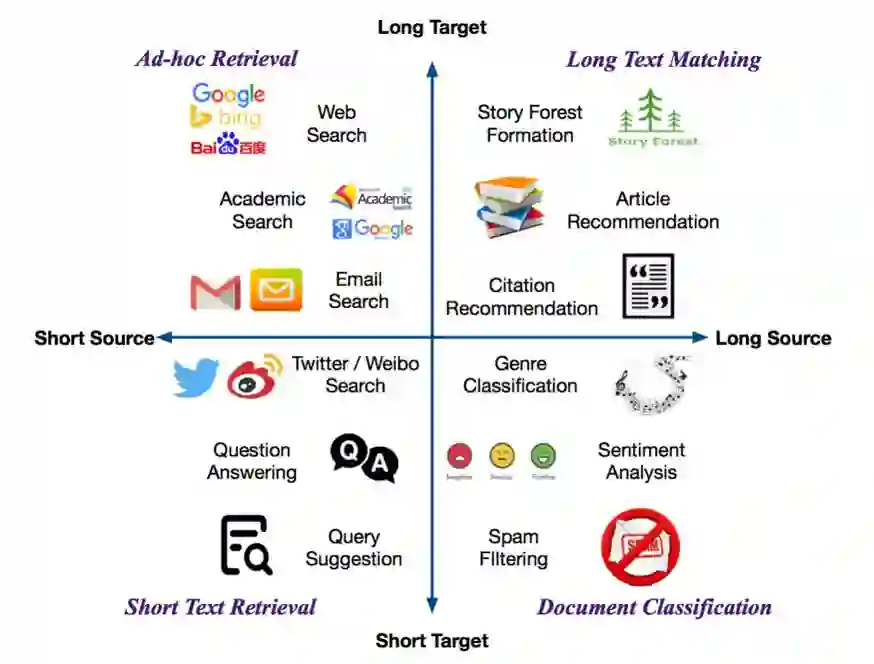
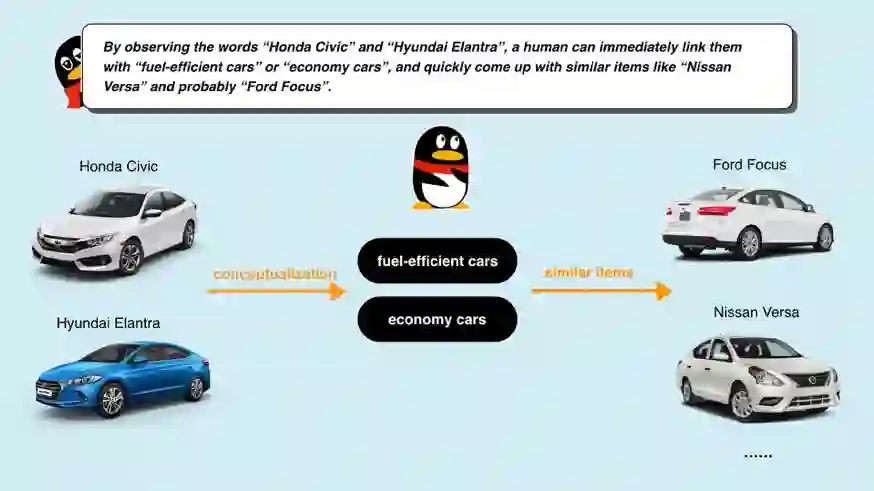
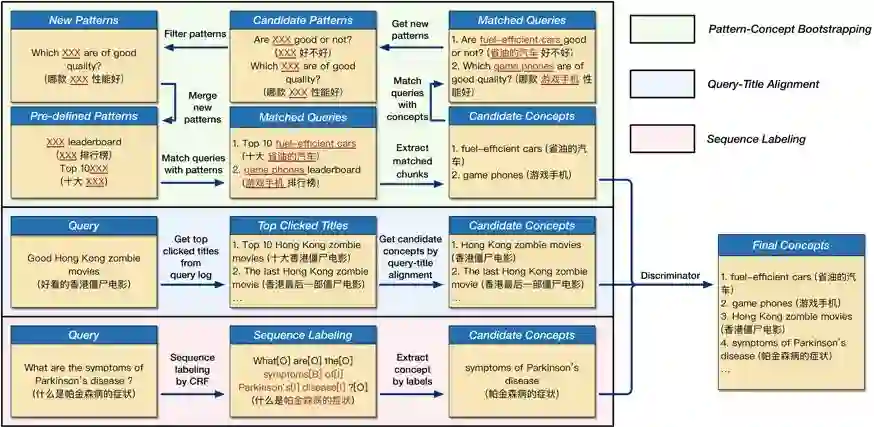
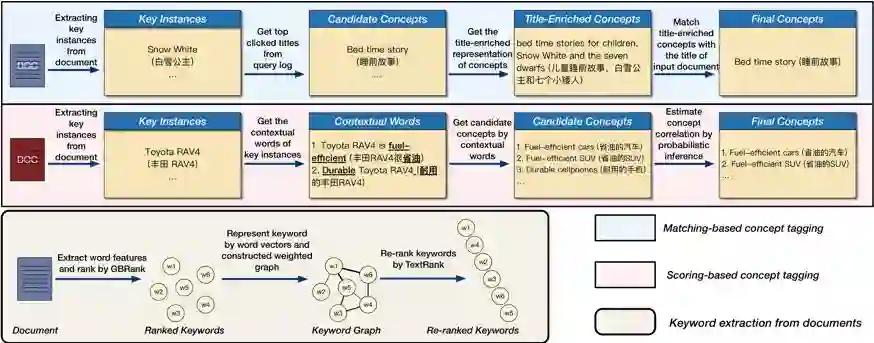
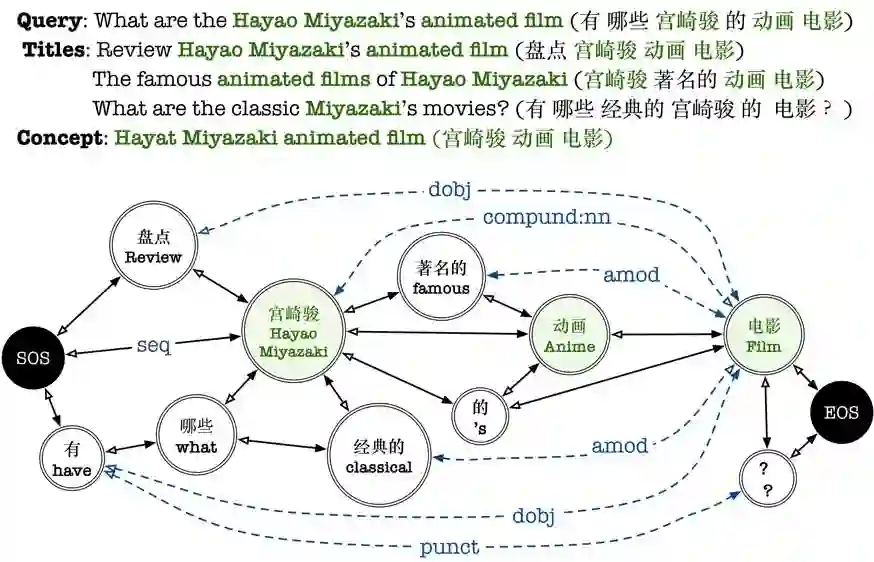
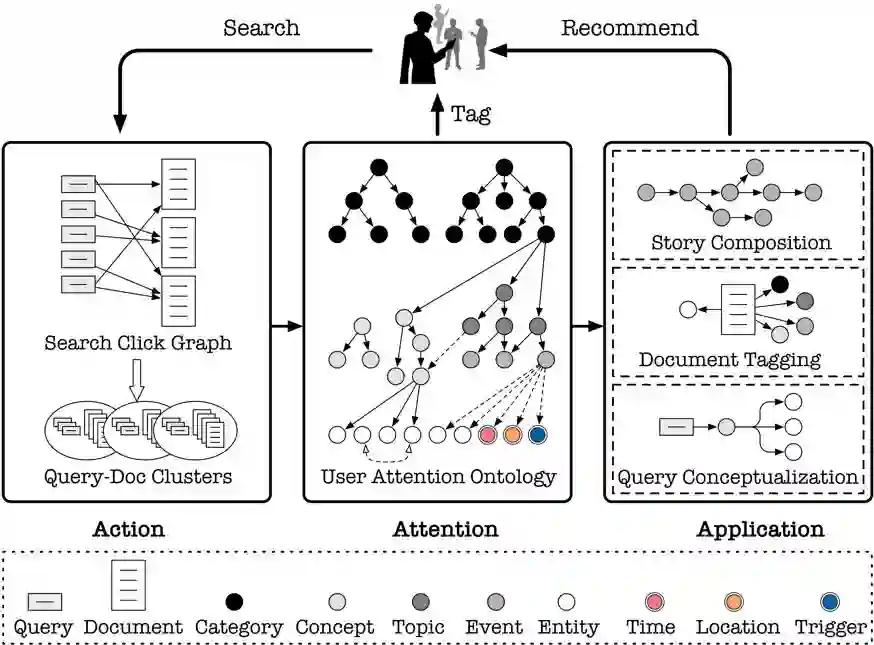
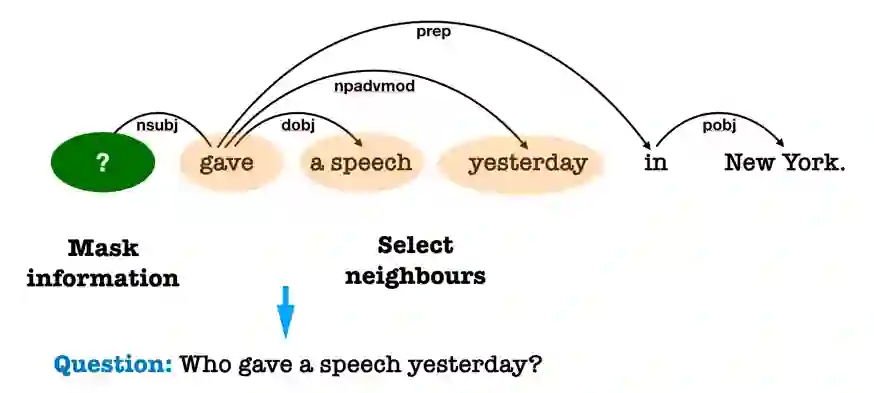
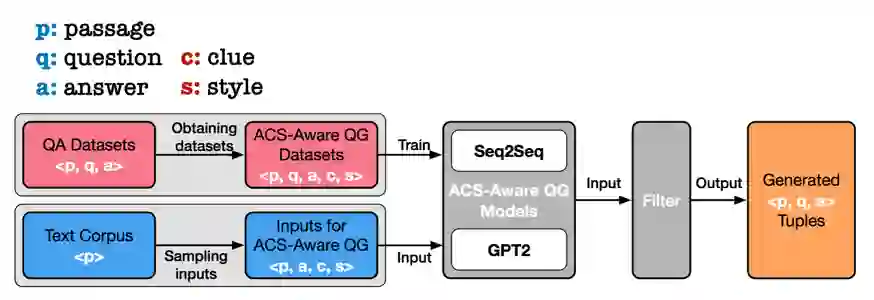
自然 语言处理(Natural Language Processing)是人工智能的核心问题之一,旨在让计算机理解语言,实现人与计算机之间用自然语言进行通信。 阿尔伯塔大学(University of Al berta)刘邦博士在他的毕业论文《Natural Language Processing and Text Mining with Graph-Structured Representations》中,对基于图结构(graph-structured represen tations)的自然语言处理和文本挖掘进行了深入研究。



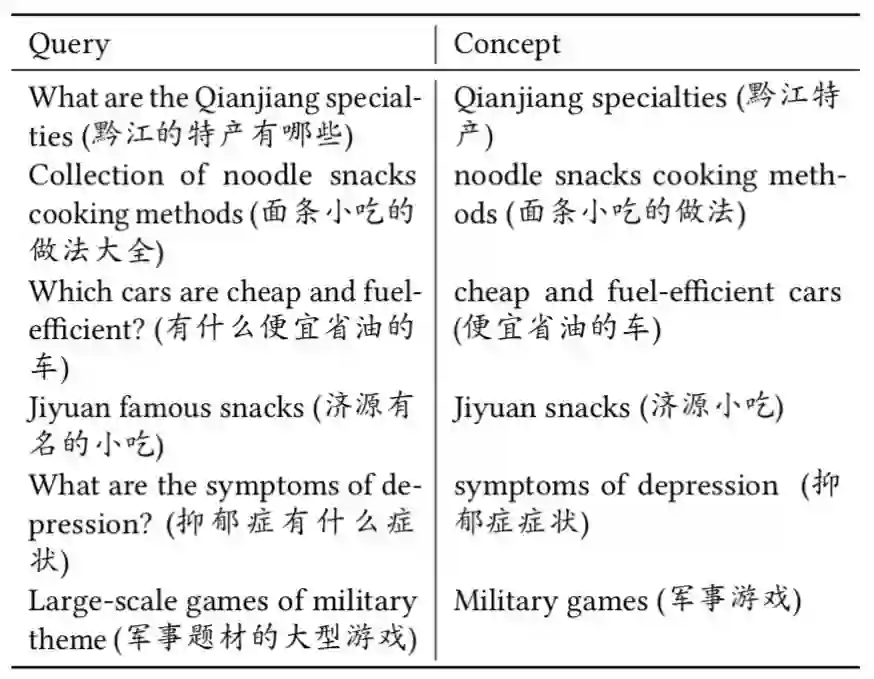
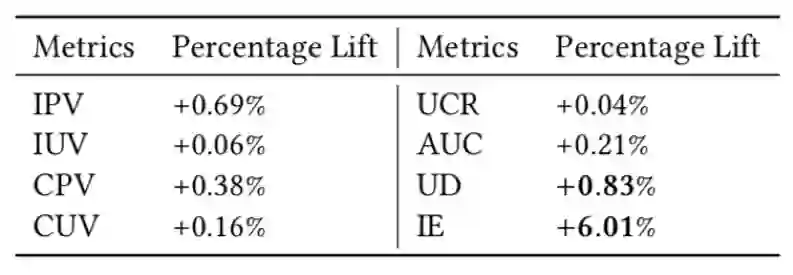
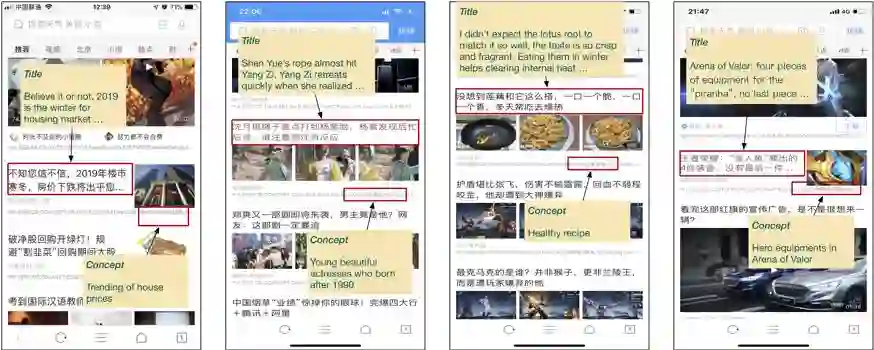
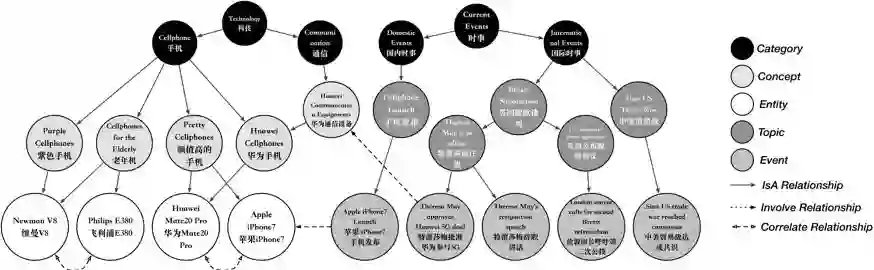



登录查看更多
相关内容

Arxiv
16+阅读 · 2017年11月20日


相关VIP内容
相关资讯